8.0 学習チェックリスト:LLM アプリ開発と RAG
このページは印刷用チェックリストとして使います。詳しい説明が必要なときは、第 8 章入口ページ に戻ってください。
2時間の初回通読
| 時間 | やること | ここまで言えたら止める |
|---|---|---|
| 20 分 | 入口ページの RAG アプリループを見る | 「RAG の回答は検索証拠と結びついているべき。」 |
| 25 分 | Tiny RAG スクリプトを動かす | 「回答を信じる前に top-k チャンクを確認できる。」 |
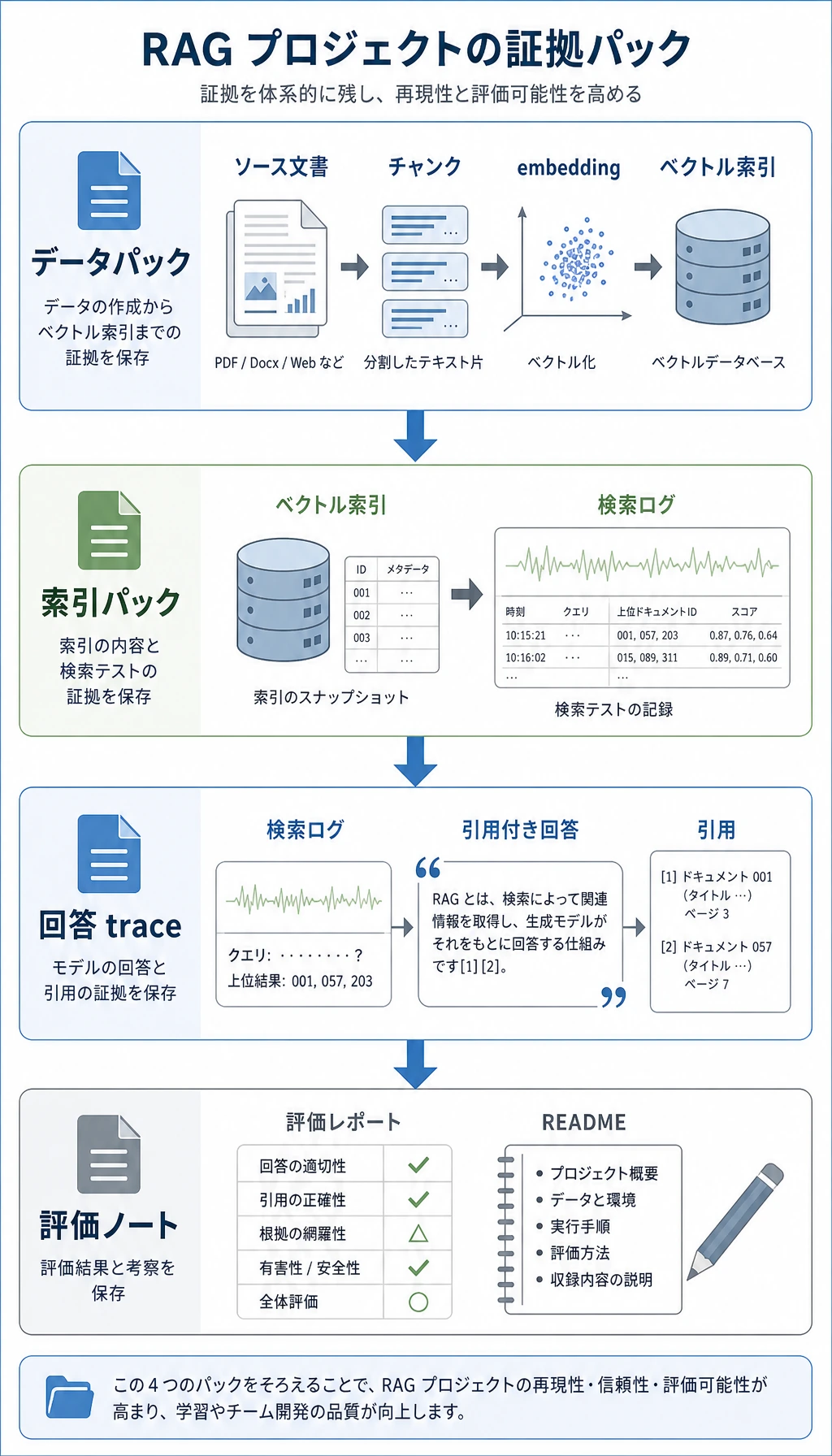
| 25 分 | 8.1 RAG 基礎と文書処理をざっと読む | 「chunk サイズ、重なり、metadata は検索と引用に効く。」 |
| 25 分 | 8.3 API 実践と tool/function calling をざっと読む | 「LLM アプリには request、response、error、retry の経路が必要。」 |
| 25 分 | デバッグ階段を読む | 「文書、検索、生成、引用、運用の失敗を分けられる。」 |
必ず残す証拠
| 証拠 | 最小版 |
|---|---|
chunks.jsonl | id、source、text、version を持つ 5~10 個の chunk |
retrieval_logs.jsonl | 各テスト質問の query、top-k chunk ID、score、source |
eval_questions.csv | 少なくとも10個の固定質問と期待出典または回答ポイント |
failure_cases.md | 少なくとも3つの失敗例。document、chunking、retrieval、generation、citation、deploy に分類 |
rag_config.md | chunk サイズ、overlap、top-k、rerank の有無、Prompt 版 |
rag_app_workshop_output.txt | 8.5.6 実践:第 8 章 RAG アプリ完全ワークショップ の出力 |
README.md | 実行コマンド、例の質問、引用付き回答、評価結果、次の修正 |
品質ゲート
| ゲート | 合格条件 |
|---|---|
| 引用 | すべての事実回答が chunk、source、version を引用する。 |
| 空検索 | 証拠がないとき、システムは回答を拒否する。 |
| 回帰評価 | chunking、retrieval、reranking、Prompt の変更前後で同じ質問を実行する。 |
| 運用 | ログに query、top-k、Prompt 版、latency、token cost、失敗ラベルがある。 |
章を出る前の質問
- RAG は「長い Prompt を書く」ことと何が違うか説明できますか?
- ある質問に対して、どの文書チャンクが検索されたか示せますか?
- chunk metadata が引用とデバッグに必須な理由を説明できますか?
- 検索が空のとき、推測ではなく「資料不足」と返せますか?
- 同じ評価質問で2つの RAG 版を比較できますか?
答えがすべて「はい」なら、第 9 章へ進みます。第 9 章では、システムを「回答生成」から、計画し、ツールを呼び、失敗から回復できる Agent へ発展させます。