10.4.3 实例分割
语义分割已经能回答:
- 哪些像素属于“人”
但如果图里有三个人,它还不够。 实例分割更进一步:
不仅知道像素属于哪个类别,还要知道它属于哪一个具体实例。
学习目标
- 理解实例分割和语义分割的差别
- 理解“类别”与“实例”为什么是两个层次
- 通过可运行示例建立实例 mask 直觉
- 理解实例分割为什么更接近真实视觉场景
先建立一张地图
实例分割最适合新人的理解顺序不是“又多了一个分割任务”,而是先看清:
所以这节真正想解决的是:
- 为什么“类别对了”还不够
- 为什么“同类个体拆开”会显著增加任务难度
一、实例分割比语义分割多了什么?
语义分割:
- 只区分类别
实例分割:
- 类别 + 个体区分
也就是说,图里两个“person”不该混成一个整体。
一个新人最该先分清的三件事
第一次学实例分割时,最值得先记住的是:
- 语义分割回答“这是什么类别”
- 实例分割还要回答“这是第几个个体”
- 所以后者天然更接近真实多目标场景
一个更适合新人的总对比表
很多新人第一次学到这里,最容易把分类、检测、语义分割、实例分割搅在一起。 最稳的办法是先把它们放在同一张表里看:
| 任务 | 输出什么 | 最核心的问题 |
|---|---|---|
| 分类 | 一张图一个类别 | 这张图整体是什么 |
| 检测 | 类别 + 框 | 目标在哪 |
| 语义分割 | 类别 mask | 哪些像素属于什么类别 |
| 实例分割 | 类别 mask + 个体区分 | 同类目标怎么一个个拆开 |
这张表特别值钱,因为它会让你一下子看清:
- 实例分割不是“更细一点的语义分割”
- 它其实是把“像素级理解”和“个体级区分”同时扛起来
二、先看一个最小实例 mask 示例
instance_map = [
[0, 1, 1, 0],
[0, 1, 1, 2],
[0, 0, 0, 2],
]
def pixels_of_instance(instance_map, target_id):
pixels = []
for r, row in enumerate(instance_map):
for c, value in enumerate(row):
if value == target_id:
pixels.append((r, c))
return pixels
print("instance 1:", pixels_of_instance(instance_map, 1))
print("instance 2:", pixels_of_instance(instance_map, 2))
预期输出:
instance 1: [(0, 1), (0, 2), (1, 1), (1, 2)]
instance 2: [(1, 3), (2, 3)]
这里的两个 instance ID 不是类别标签,而是“具体对象编号”。它们可以属于同一个类别,但系统仍然要把它们分开。
这个例子最关键的地方是什么?
它说明实例分割不只是输出类别编号, 还会区分:
- 第 1 个实例
- 第 2 个实例
这在计数、跟踪和交互场景里非常重要。
为什么实例分割会特别适合安防和自动驾驶?
因为这些场景里,系统往往不只关心:
- 画面里有没有人
更关心:
- 到底有几个人
- 哪几个目标彼此挨得很近
- 后续能不能继续跟踪这些个体
也就是说,实例分割天然更像“面向后续决策的视觉表示”。
再看一个最小“计数 + 面积”示例
实例分割之所以在真实系统里特别值钱, 是因为它不仅能告诉你“有几个目标”, 还更容易继续往下算:
- 每个目标面积多大
- 哪个目标离边界更近
- 哪些目标彼此重叠
下面这个例子先用最小方式体会这种“个体级统计”:
instance_map = [
[0, 1, 1, 0, 2],
[0, 1, 1, 0, 2],
[0, 0, 0, 0, 2],
]
def instance_area(instance_map, target_id):
area = 0
for row in instance_map:
for value in row:
if value == target_id:
area += 1
return area
for target_id in [1, 2]:
print(target_id, "area =", instance_area(instance_map, target_id))
预期输出:
1 area = 4
2 area = 3
一旦每个对象都有自己的 mask,你就可以计数,也可以计算面积。这正是实例分割在质检、跟踪和规划系统里很有价值的原因之一。
这个例子最值得先抓住的不是代码本身, 而是:
- 一旦个体被拆开
- 后面很多统计和决策都会自然多出来
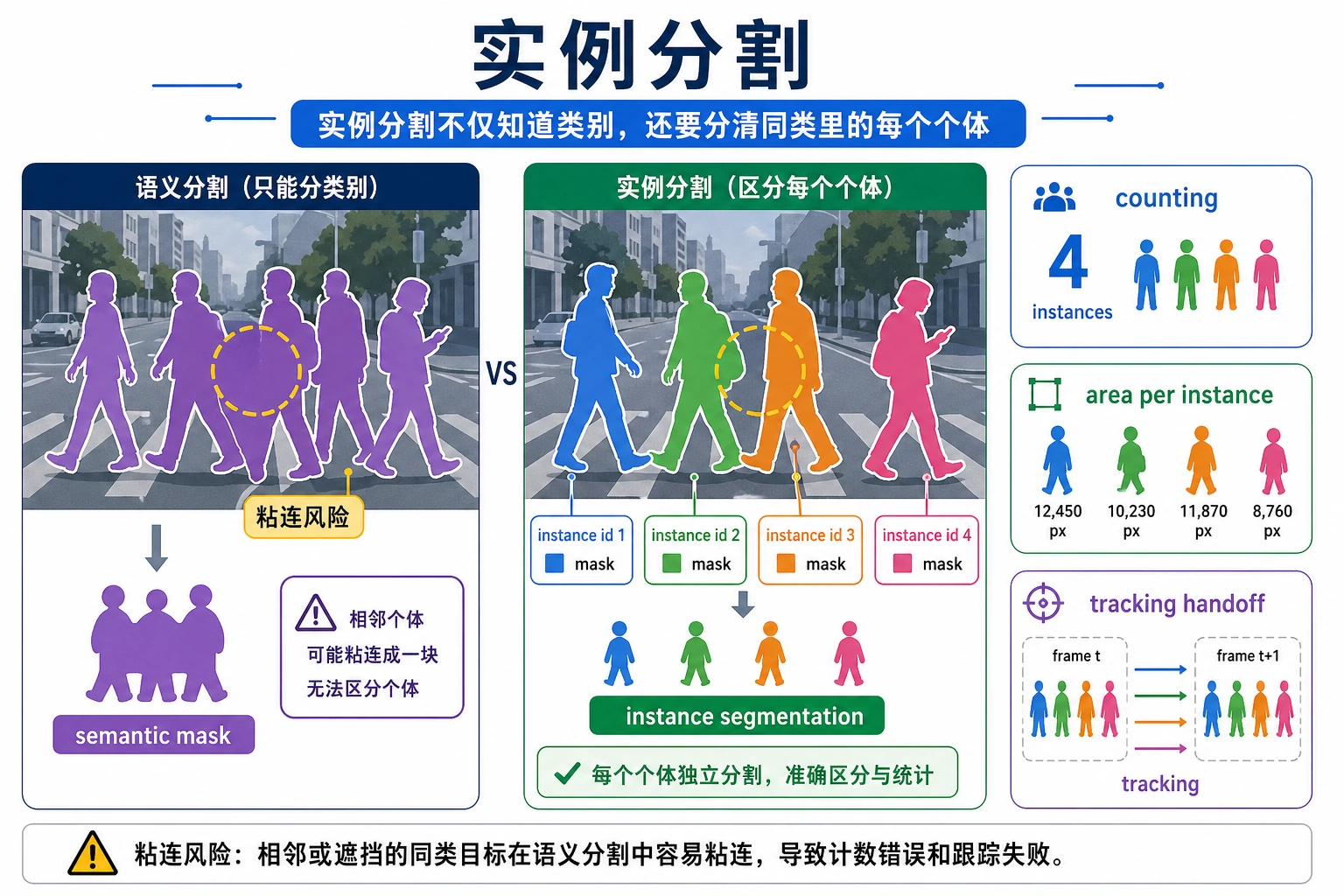
语义分割只关心“哪些像素是人”,实例分割还要分清“第 1 个人、第 2 个人”。读图时重点看相邻同类目标为什么容易粘连,以及个体拆开后如何继续做计数和面积统计。
三、最容易踩的坑
相邻同类实例容易粘在一起
这是实例分割特别常见的错误。
小实例更难
个体越小、越拥挤,越难分清。
评估比语义分割更复杂
因为现在不仅要看 mask 质量, 还要看实例是否正确拆开。
四、第一次做实例分割项目时,最稳的默认顺序
第一次把实例分割放进项目里, 更建议按这个顺序推进:
- 先确认任务真的需要“拆开同类个体”
- 先拿少量样本人工看实例边界是否明确
- 先做一个可视化 baseline,看实例有没有被粘连
- 再看 mask 质量和个体拆分是否同时成立
- 最后再考虑更复杂模型和更细评估
这会比一开始就追复杂网络更稳, 因为实例分割最怕的往往不是“模型不够复杂”, 而是:
- 标注边界本身不清
- 任务需求没定义清楚
五、第一次学这节时最正确的预期
这一节最重要的不是今天就学会复杂实例分割网络, 而是先真正看清:
- 为什么语义分割和实例分割不是一个东西
- 为什么相邻同类目标会成为真正难点
- 为什么这个任务一旦做好,会对计数、交互和跟踪特别有价值
小结
这节最重要的是建立一个判断:
实例分割比语义分割多解决了一层“同类目标之间怎么区分”的问题,因此更接近真实多目标视觉场景。
这节最该带走什么
- 实例分割是在语义分割之上再补“个体拆分”
- 难点往往不在类别,而在相邻同类目标的边界
- 如果后续任务需要计数、跟踪或交互,实例分割往往特别有价值
练习
- 自己构造一个更大的
instance_map,再标出 3 个实例。 - 为什么实例分割比语义分割更难?
- 如果两个相邻目标总被粘成一个实例,你会首先怀疑什么?
- 想一想:实例分割在自动驾驶或安防里为什么特别有价值?