10.6.3 项目:医学影像分析【选修】
医学影像项目和普通视觉项目最大的不同,不在于模型换了个名字,而在于:
- 错误代价更高
- 数据更贵
- 标注更难
- 上线边界更敏感
所以它特别适合用来练“高风险 AI 项目”的判断能力。
学习目标
- 学会把医学影像项目范围定得足够清楚
- 学会把标注、指标和临床风险一起写进项目定义
- 学会设计更像临床辅助系统的评估展示方式
- 学会把这类项目做成作品级页面而不是炫图 demo
先建立一张地图
医学影像项目更适合按“任务边界 -> 风险指标 -> 人工复核 -> 错误复盘”的顺序理解:
所以这节真正想解决的是:
- 医学影像项目为什么不能只拿普通视觉项目那套思路直接套
- 为什么这类项目特别强调边界、风险和复核
一、项目题目为什么一定要收窄?
一个适合作品集的题目可以是:
做一个“肺部病灶区域分割辅助系统”,输入 CT slice,输出病灶区域 mask 和风险说明。
为什么这个题目好?
- 输入输出明确
- 指标可解释
- 风险边界清晰
为什么不建议一开始做太大?
例如:
- 覆盖多器官、多病种、多模态
这会让项目从一开始就失去可验证性。
二、作品级医学影像项目最小闭环
- 定义任务和临床边界
- 说明标注协议
- 选 baseline
- 定义高风险指标
- 展示成功与失败样例
- 明确人工复核与适用边界
如果这些没讲清,项目就很难让人信任。
一张更像真实临床辅助系统的闭环图
这个闭环很重要,因为医学影像项目通常不是:
- 模型跑完就结束
而是:
- 模型先给出辅助判断
- 人工再做确认
- 失败样本再回流修订数据和规则
三、先看一个更像真实项目的规划对象
from dataclasses import dataclass, field
@dataclass
class MedicalProject:
task: str
input_type: str
labels: list
metrics: list
clinical_constraints: list
risks: list = field(default_factory=list)
project = MedicalProject(
task="肺部病灶区域分割",
input_type="CT slice",
labels=["background", "lesion"],
metrics=["dice", "iou", "sensitivity", "false_negative_rate"],
clinical_constraints=[
"高风险样本必须人工复核",
"结果仅作辅助,不直接替代临床判断",
],
risks=["标注不一致", "类别极度不平衡", "假阴性代价高"],
)
print(project)
预期输出:
MedicalProject(task='肺部病灶区域分割', input_type='CT slice', labels=['background', 'lesion'], metrics=['dice', 'iou', 'sensitivity', 'false_negative_rate'], clinical_constraints=['高风险样本必须人工复核', '结果仅作辅助,不直接替代临床判断'], risks=['标注不一致', '类别极度不平衡', '假阴性代价高'])
这个输出刻意不只是指标列表,而是把任务、输入、标签、指标、临床边界和风险一起写进了一个项目对象。
为什么这里要把 clinical_constraints 单独列出来?
因为这类项目和普通视觉项目最大的差别之一就在于:
- 不是只看模型成绩
- 还要看临床使用边界
这也是它更像真实高风险项目的地方。
四、为什么这类项目最怕假阴性?
如果模型漏掉病灶, 通常风险比多报一个可疑区域更大。
所以作品级项目里, 很值得单独展示:
- sensitivity / recall
- false negative rate
而不是只放一个总体准确率。
一个更适合新人的总类比
你可以把医学影像系统想成:
- 机场安检机器
它可以多报几个可疑包裹,再让安检员复查; 但如果真正危险的包裹完全没被发现,问题会严重得多。
这就是为什么很多医学项目里:
- 误报很烦
- 漏报更危险
再看一个最小“病例复核优先级”示例
cases = [
{"id": "case-001", "lesion_score": 0.91, "size_mm": 18},
{"id": "case-002", "lesion_score": 0.44, "size_mm": 5},
{"id": "case-003", "lesion_score": 0.78, "size_mm": 22},
]
def review_priority(case):
if case["lesion_score"] >= 0.85:
return "high"
if case["lesion_score"] >= 0.6 or case["size_mm"] >= 20:
return "medium"
return "low"
for case in cases:
print(case["id"], review_priority(case))
预期输出:
case-001 high
case-002 low
case-003 medium
case-001 因为分数高,所以优先级高;case-003 虽然分数没超过 0.85,但病灶尺寸较大,所以是中优先级。
这个例子虽然很小,但它已经体现出一个真实项目思路:
- 不是所有样本都同样对待
- 高风险样本要优先人工复核
五、一个最小“高风险指标优先级”示例
metrics = {
"dice": 0.81,
"iou": 0.69,
"sensitivity": 0.92,
"false_negative_rate": 0.08,
}
def risk_summary(metrics):
if metrics["false_negative_rate"] > 0.1:
return "当前假阴性偏高,不适合直接作为高风险辅助系统。"
if metrics["sensitivity"] < 0.9:
return "召回仍偏低,建议优先继续优化病灶检出率。"
return "指标初步可用,但仍需配合人工复核与临床验证。"
print(risk_summary(metrics))
预期输出:
指标初步可用,但仍需配合人工复核与临床验证。
这些指标通过了这个简化风险门槛,但提示语仍然保留临床边界:这是辅助系统,不是自动诊断。
这个例子为什么比只打印一堆分数更有价值?
因为它把指标翻译成了:
- 可用于项目判断的语言
这在医学项目里非常关键。
一个更适合初学者先记的评估表
| 指标 | 更像在回答什么问题 |
|---|---|
| Dice / IoU | 区域分得准不准 |
| Sensitivity / Recall | 真正的病灶有没有尽量找出来 |
| False Negative Rate | 漏掉高风险样本的比例有多高 |
| 人工复核通过率 | 结果有没有机会进入真实辅助流程 |
这个表很适合新人,因为它会把医学影像评估从“又多几个指标名”重新变成“这些指标到底在替谁服务”。
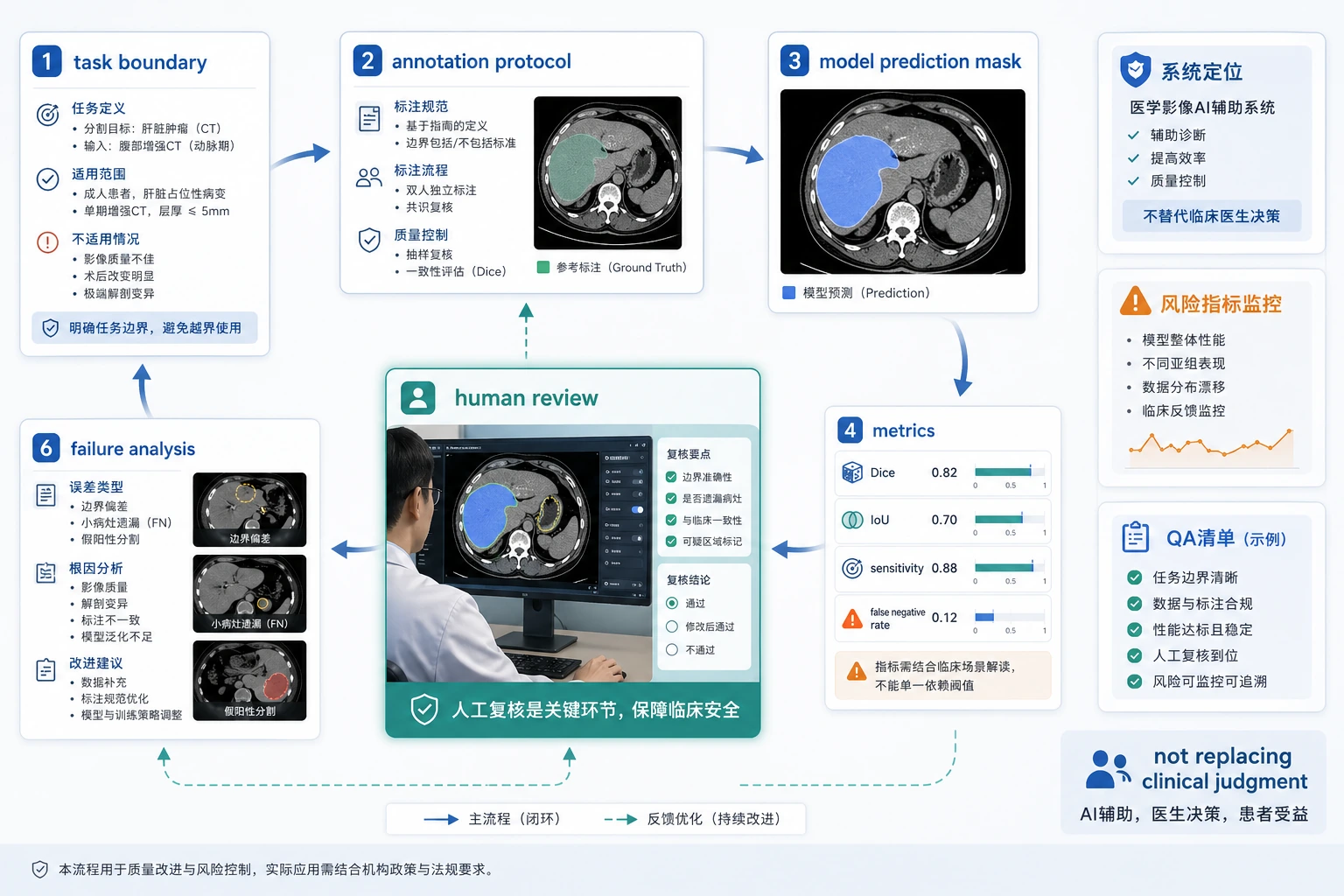
医学影像项目不能只展示漂亮 mask。读这张图时按任务边界、标注协议、sensitivity、false negative rate、人工复核和失败样本回流来判断它是否可信。
六、医学影像项目最值得展示什么?
建议至少展示:
- 原图
- 专家标注 mask
- 模型预测 mask
- 失败样例
- 风险边界说明
为什么这些比“几张好看的成功图”更重要?
因为高风险项目最重要的是:
- 可信
- 可解释
- 边界清楚
如果你第一次做这类项目,最稳的默认顺序
更稳的顺序通常是:
- 先把任务收窄成一个病种或一个器官
- 先做二分类或单类分割 baseline
- 先把标注协议和风险边界写清楚
- 再补 sensitivity、false negative rate 这些高风险指标
- 最后再展示成功样本、失败样本和人工复核流程
这样会比一开始就追求:
- 多病种
- 多模态
- 多任务
更容易做出一个可信的项目。
如果把它做成作品集,最值得展示什么
最值得展示的,不只是模型分数,而是:
- 任务为什么收得这么窄
- 为什么假阴性是重点风险
- 模型结果如何进入人工复核流程
- 失败样本长什么样
- 你的项目边界在哪里
这样招聘方或读者会更容易感觉到:
- 你理解的是系统问题
- 不只是会跑一个分割模型
一个新人可直接照抄的错误分析顺序
第一次做这类项目时,更稳的错误分析顺序通常是:
- 先分漏检和误检
- 再看高风险样本是不是特别容易错
- 再看边界问题还是标注问题更突出
- 最后再决定是补数据、补规则还是改模型
这样会比一上来就重新换网络更容易看清真正问题。
目标是拿出围绕风险的证据,而不是只做视觉演示效果。
七、最常见误区
只看总体准确率
不写标注一致性问题
不说明人工复核边界
只展示漂亮成功图,不展示高风险错例
医学影像项目最容易“看起来很强”, 因为成功案例往往很直观。 但真正更有价值的通常是:
- 哪些病例最容易漏
- 哪些边界最容易分错
- 这些错误会不会影响人工辅助决策
小结
这节最重要的是建立一个作品级判断:
医学影像项目真正像项目的地方,不是模型多复杂,而是你能否把任务边界、标注协议、敏感指标和风险说明一起讲清楚。
只要这一点做到位,这类项目会非常有说服力。
这节最该带走什么
- 医学影像项目比普通视觉项目更强调风险边界
- 很多时候 sensitivity 和 false negative rate 比总体准确率更关键
- 一个可信的医学项目,必须把人工复核和适用边界一起讲出来
版本路线建议
| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。
练习
- 把项目再改成一个更小的二分类筛查任务,重写
clinical_constraints。 - 为什么说医学影像项目里
false_negative_rate往往比总体准确率更值得被单独展示? - 想一想:标注一致性不高时,模型结果该怎么被解读?
- 如果把这个项目放进作品集,哪一段风险说明最值得你单独强调?