4.2.1 概率路线图:给 AI 一套描述不确定性的语言
概率和统计解释模型为什么会输出置信度、数据为什么会波动,以及训练为什么使用 loss,而不只是对/错标签。
先看地图
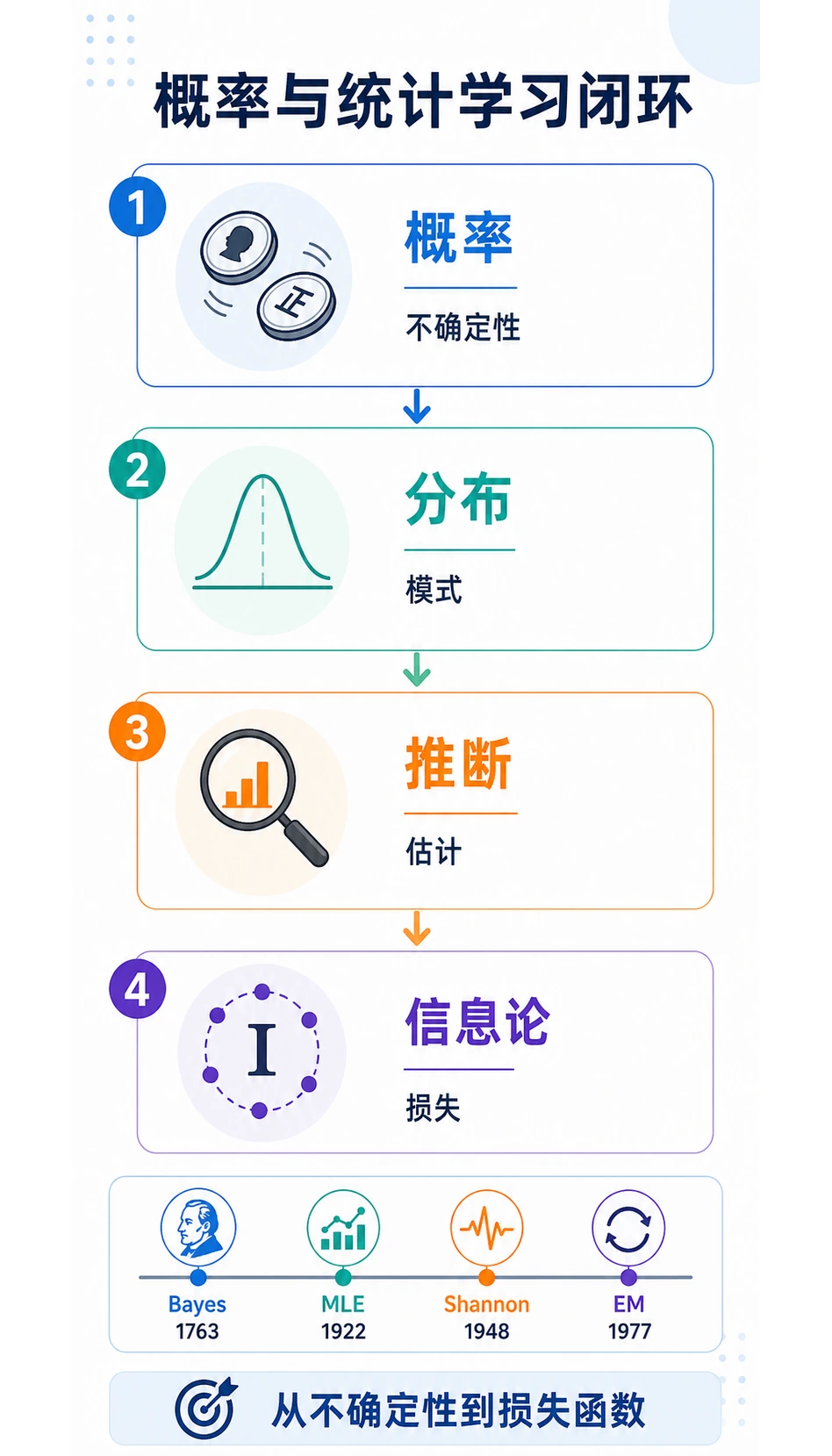
本小章流向是:

| 术语 | 先问的问题 |
|---|---|
| 概率 | 这件事有多可能发生? |
| 分布 | 很多随机结果整体长什么样? |
| 推断 | 看见数据后能得出什么结论? |
| 熵 | 结果有多不确定? |
| 交叉熵 | 预测的概率分布错得有多远? |
| KL 散度 | 两个分布有多不同? |
跑最小闭环
创建 probability_first_loop.py。它只用 Python 标准库。
import math
labels = [1, 0, 1, 1]
predicted_probs = [0.9, 0.2, 0.6, 0.8]
losses = []
for y, p in zip(labels, predicted_probs):
loss = -(y * math.log(p) + (1 - y) * math.log(1 - p))
losses.append(loss)
cross_entropy = sum(losses) / len(losses)
print("cross_entropy:", round(cross_entropy, 3))
print("predicted_probs:", predicted_probs)
预期输出:
cross_entropy: 0.266
predicted_probs: [0.9, 0.2, 0.6, 0.8]
交叉熵越低,说明预测概率越接近标签。这就是概率和模型训练直接相连的地方。
按这个顺序学
| 顺序 | 阅读 | 先抓住什么 |
|---|---|---|
| 1 | 4.2.2 概率基础 | 事件、条件概率、贝叶斯更新 |
| 2 | 4.2.3 概率分布 | 伯努利、二项、正态分布 |
| 3 | 4.2.4 统计推断 | MLE、MAP、置信度、A/B 测试 |
| 4 | 4.2.5 信息论 | 熵、交叉熵、KL 散度 |
| 5 | 4.2.6 历史基础 | 贝叶斯、Fisher、Shannon、EM 的位置 |
通过标准
能说清一个概率术语在衡量哪种不确定性,并能解释分类器输出 0.93 为什么有用但不是绝对真相,就算通过。