4.2.4 统计推断基础
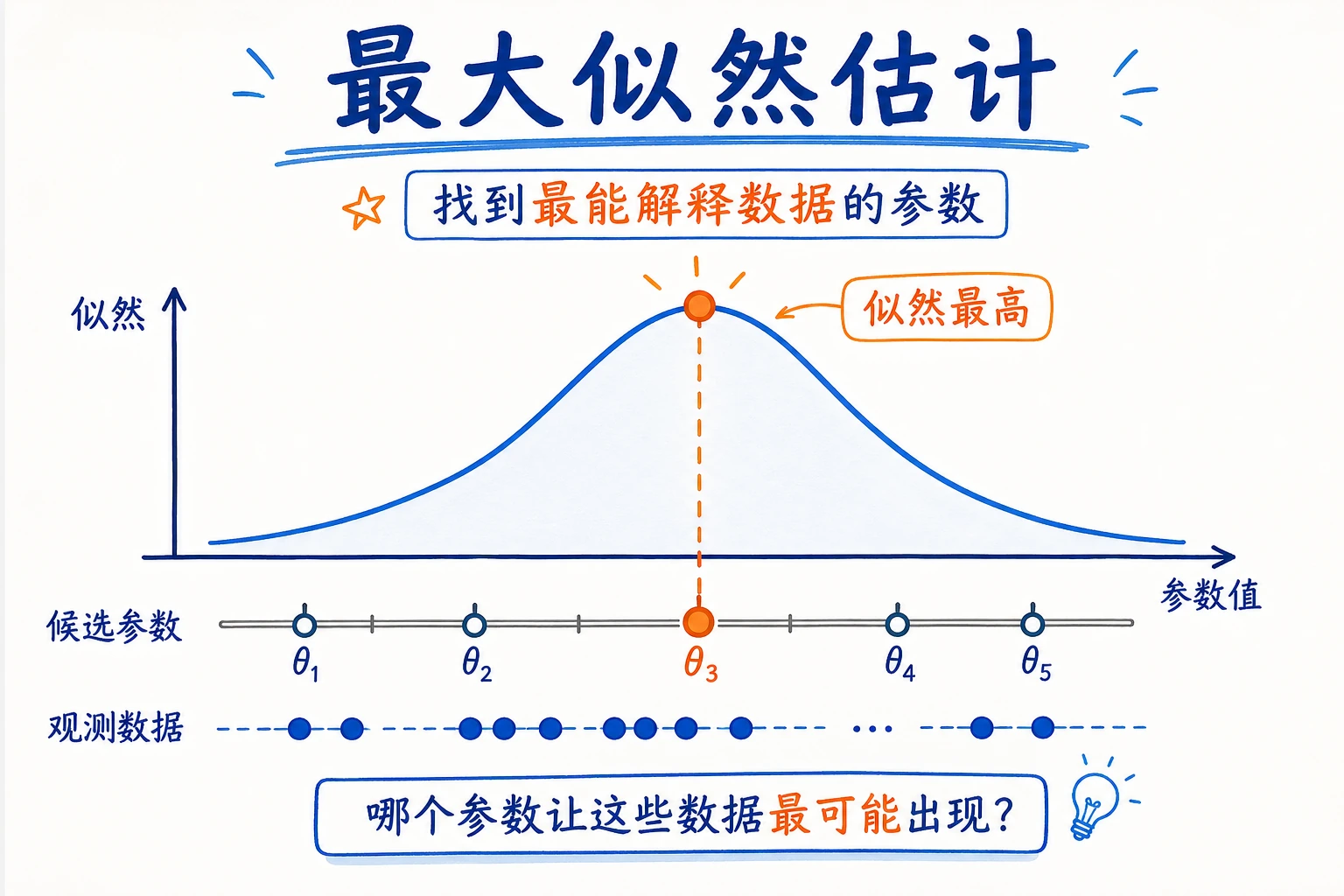
上一节学了各种概率分布。但真实世界中,我们不知道分布的参数(比如硬币正面概率是多少)。统计推断就是从观测到的数据,反推出分布的参数。
学习目标
- 理解最大似然估计(MLE)的直觉——为什么要"最大化概率"
- 理解最大后验估计(MAP)——加入先验知识
- 理解假设检验和 p 值(A/B 测试思维)
- 用 Python 实现 MLE
推断前先解码这些术语
统计推断里有很多缩写,最好把它们当成一个流程来理解,而不是孤立背定义:
| 术语 | 全称/含义 | 新人可以先问什么问题 |
|---|---|---|
MLE | Maximum Likelihood Estimation,最大似然估计 | 哪组参数最能让已经看到的数据变得合理? |
MAP | Maximum A Posteriori,最大后验估计 | 同时考虑数据和先验后,哪组参数最可信? |
EM | Expectation-Maximization,期望最大化 | 有隐藏变量时,怎样一边猜隐藏量,一边更新参数? |
likelihood | 似然 | 如果这个参数是真的,看到这批数据有多合理? |
log-likelihood | 对数似然 | 用加法处理很多很小的概率,比直接连乘更稳定 |
prior | 先验 | 看到当前数据之前,我们原本相信什么? |
posterior | 后验 | 结合数据和先验之后,我们更新成什么判断? |
p-value | 零假设下的尾部概率 | 如果真的没有差异,当前结果有多不寻常? |
CI | Confidence interval,置信区间 | 未知量比较可能落在哪个范围里? |
特别提醒:p 值 不是 “零假设为真的概率”。它是在“假设零假设为真”的前提下,观察到当前这么极端结果的概率。
历史背景:MLE 和 EM 各自是怎么来的?
这一节里有两个特别值得知道的历史节点:
| 年份 | 节点 | 关键作者 | 它最重要地解决了什么 |
|---|---|---|---|
| 1922 | Maximum Likelihood Estimation | Ronald Fisher | 把“最能解释观测数据的参数”系统化,成为统计学习和损失函数主线的重要底座 |
| 1977 | EM Algorithm | Dempster, Laird, Rubin | 给“有隐变量、缺失信息”的参数估计问题提供了稳定迭代框架 |
这里有个很重要的区分:
- MLE 更像一个完整领域 / 原则
- EM 更像在某类困难场景下求 MLE 的经典方法
所以新人第一次学这一节,最值得先知道的是:
MLE 在回答“什么参数最像真的”,EM 在回答“当问题里有看不见的部分时,怎么一步步逼近这个参数”。
为什么这条线对很多初学者会特别有吸引力?
因为它第一次把“从数据反推规律”这件事讲得很像破案:
- 真相你没直接看到
- 参数也没人告诉你
- 但你手里已经有很多观测痕迹
于是问题就变成:
- 哪种解释最能把这些痕迹串起来?
MLE 会让人觉得“像侦探”, EM 会让人觉得“像在黑箱里摸着石头过河”, 这也是为什么很多人第一次认真学统计推断时,会突然感觉:
原来模型训练不只是算公式,而是在做一种有步骤的反推。
这条线为什么会让统计学习后来那么重要?
因为它把一个很朴素的问题讲得非常清楚:
- 既然世界不会直接把参数告诉你
- 那你就应该从数据倒着猜
MLE 最打动人的地方,恰恰就是它很像侦探工作:
- 现场已经留下了很多痕迹
- 你不知道真相
- 但你可以问:哪种解释最像真的发生过
而 EM 更像是在说:
- 如果现场有一部分信息根本看不见
- 那就不要放弃,先猜一版,再修一版,反复逼近
所以这条主线对初学者很有吸引力的地方在于:
它让“从数据反推规律”第一次变得像一个有步骤、有策略、能逐步逼近的过程。
先说一个很重要的学习预期
这一节很容易让新人一读到 MLE / MAP / p 值 就开始发虚。
但这里最重要的不是一下子把统计推断学得像统计课那样完整,而是先让你知道:
- 看到了数据以后,我们到底想反推出什么
- “最能解释数据”这句话在数学上是什么意思
- 为什么这些思想最后会直接长进 loss、正则化和 A/B 测试里
先建立一张地图
前两节学的是“概率怎么定义、分布长什么样”,这一节开始进入:
既然我们拿到了数据,怎样反推出背后的参数和结论?
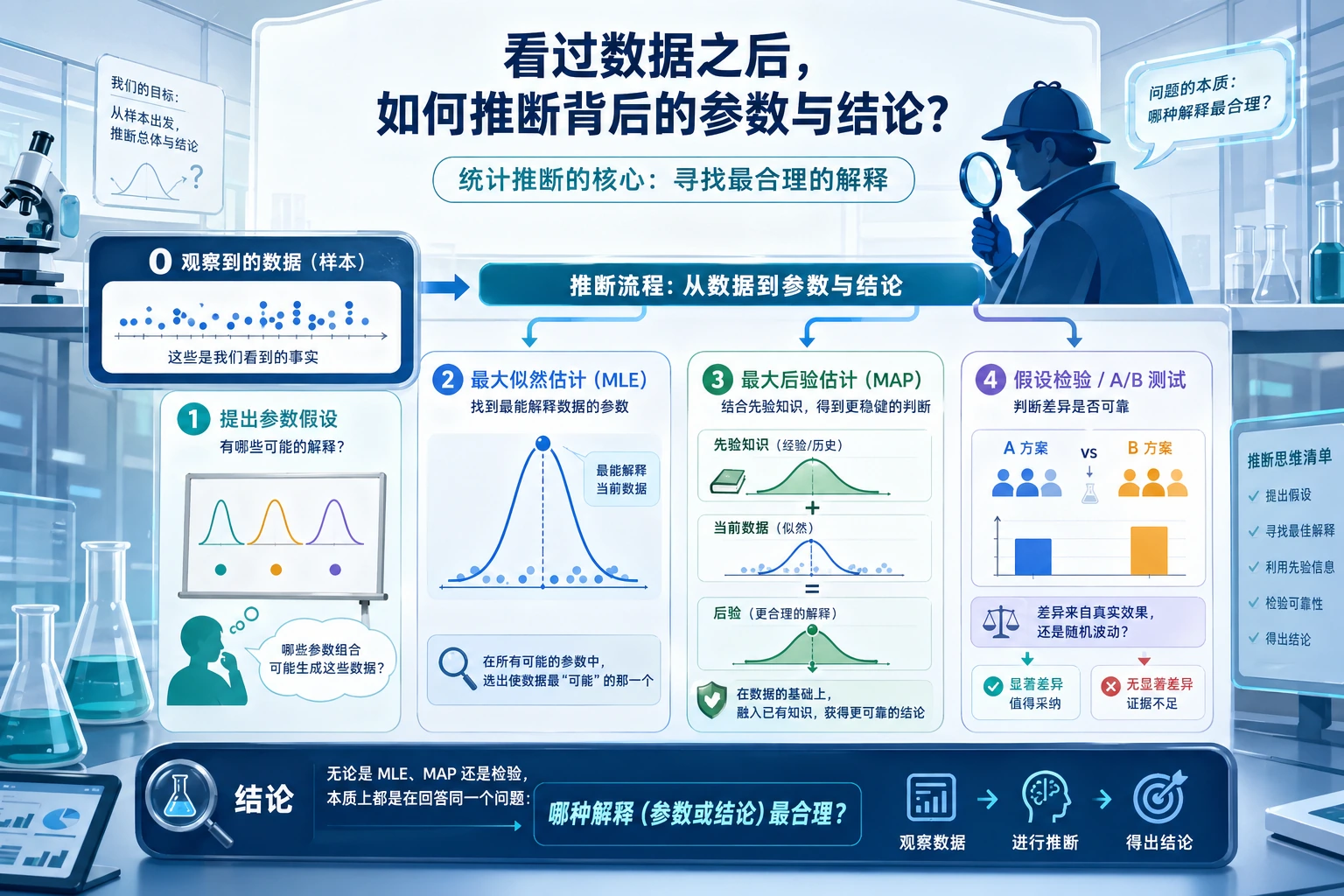
这节课最重要的不是记名词,而是先抓住:
- MLE:什么参数最能解释这些数据
- MAP:在数据之外,再把先验常识也考虑进去
- 假设检验:看到差异后,怎样判断它是不是偶然
一、最大似然估计(MLE)
直觉:什么参数最能解释数据?
你捡到一枚硬币,不知道它公不公平。你抛了 10 次:正正反正正正反正正正(8 次正面,2 次反面)。
问题:这枚硬币正面朝上的概率 p 最可能是多少?
直觉告诉你:p ≈ 0.8。MLE 就是把这个直觉数学化——找到那个让观测数据出现概率最大的参数值。
一个更适合新人的类比
你可以把 MLE 先想成“最像侦探在还原案情”的过程:
- 已经看到了一串线索(观测数据)
- 现在要倒推:哪种参数设定最像真的发生过这件事
所以 MLE 的核心不是“为了最大化而最大化”,而是:
找出最能解释眼前这批数据的参数。
用代码理解
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 观测数据:10 次抛掷,8 正 2 反
n_heads = 8
n_tails = 2
n_total = n_heads + n_tails
# 对于不同的 p 值,计算产生这组数据的概率(似然函数)
p_values = np.linspace(0.01, 0.99, 1000)
# 似然函数:L(p) = C(n,k) * p^k * (1-p)^(n-k)
# 我们可以忽略 C(n,k)(它不依赖于 p)
likelihood = p_values**n_heads * (1 - p_values)**n_tails
# MLE:似然最大的 p
p_mle = p_values[np.argmax(likelihood)]
print(f"MLE 估计: p = {p_mle:.3f}")
# 可视化
plt.figure(figsize=(10, 5))
plt.plot(p_values, likelihood, color='steelblue', linewidth=2)
plt.axvline(x=p_mle, color='red', linestyle='--', linewidth=2, label=f'MLE: p = {p_mle:.2f}')
plt.fill_between(p_values, likelihood, alpha=0.1, color='steelblue')
plt.xlabel('p(正面概率)')
plt.ylabel('似然 L(p)')
plt.title(f'似然函数:抛 10 次硬币,{n_heads} 正 {n_tails} 反')
plt.legend(fontsize=12)
plt.grid(True, alpha=0.3)
plt.show()
预期输出:
MLE 估计: p = 0.800
MLE 的数学直觉
MLE 的答案其实很简单:p = 正面次数 / 总次数 = 8/10 = 0.8
但 MLE 的价值在于它是一个通用框架——对于任何分布,都可以用同样的思路找参数。
为什么这一点对 AI 特别重要?
因为很多损失函数表面看起来是在“做优化”, 但更底层的视角其实是:
- 我们在找一组参数
- 让这组参数最能解释训练数据
也就是说,MLE 是很多训练目标背后的共同语言。
更多数据 = 更准确的估计
# 真实的 p = 0.6
rng = np.random.default_rng(seed=42)
true_p = 0.6
n_experiments = [10, 50, 100, 500, 2000]
fig, axes = plt.subplots(1, len(n_experiments), figsize=(20, 4))
for ax, n in zip(axes, n_experiments):
# 抛 n 次硬币
heads = rng.binomial(n, true_p)
# 似然函数
p_vals = np.linspace(0.01, 0.99, 500)
ll = heads * np.log(p_vals) + (n - heads) * np.log(1 - p_vals)
ll = np.exp(ll - ll.max()) # 归一化
p_mle = heads / n
print(f"n={n:4d}, 正面={heads:4d}, MLE={p_mle:.3f}")
ax.plot(p_vals, ll, color='steelblue', linewidth=2)
ax.axvline(x=true_p, color='green', linestyle='--', label=f'真实 p={true_p}')
ax.axvline(x=p_mle, color='red', linestyle='--', label=f'MLE={p_mle:.3f}')
ax.set_title(f'n = {n}')
ax.set_xlabel('p')
ax.legend(fontsize=8)
plt.suptitle('数据越多,MLE 越准、越确定(曲线越窄)', fontsize=13)
plt.tight_layout()
plt.show()
使用 seed=42 时,预期输出:
n= 10, 正面= 5, MLE=0.500
n= 50, 正面= 31, MLE=0.620
n= 100, 正面= 69, MLE=0.690
n= 500, 正面= 318, MLE=0.636
n=2000, 正面=1212, MLE=0.606
解读:数据越多,似然函数的峰越窄、越接近真实值。这就是"大数据"的力量。
二、最大后验估计(MAP)
MLE 的问题
如果你只抛了 3 次硬币,全是正面,MLE 会告诉你 p = 3/3 = 1.0——"这枚硬币永远正面朝上"。
这显然不合理。我们的常识告诉我们,大多数硬币的 p 应该接近 0.5。
MAP:加入先验知识
MAP 在 MLE 的基础上加了一个"先验"——你对参数的事先信念:
MAP = 似然 × 先验
一个更好记的说法
如果 MLE 是:
- 只看眼前证据
那 MAP 更像:
- 眼前证据 + 你原本对世界的常识
所以它很适合解释很多 AI 里的现象:
- 为什么“约束一下参数别太大”会更稳
- 为什么正则化不只是技巧,而是某种先验假设
# 数据:3 次全正面
n, k = 3, 3
p_values = np.linspace(0.01, 0.99, 1000)
# 似然函数
likelihood = p_values**k * (1 - p_values)**(n - k)
# 先验:我们相信 p 大概率在 0.5 附近(用 Beta 分布表示)
prior = stats.beta.pdf(p_values, a=5, b=5) # 以 0.5 为中心的先验
# 后验 ∝ 似然 × 先验
posterior = likelihood * prior
posterior = posterior / np.trapezoid(posterior, p_values) # 归一化
# 找最大值
p_mle = p_values[np.argmax(likelihood)]
p_map = p_values[np.argmax(posterior)]
print(f"MLE: p = {p_mle:.3f}")
print(f"MAP: p = {p_map:.3f}")
# 可视化
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(p_values, likelihood / np.trapezoid(likelihood, p_values),
'--', color='coral', linewidth=2, label='似然函数')
ax.plot(p_values, prior / np.trapezoid(prior, p_values),
'--', color='green', linewidth=2, label='先验')
ax.plot(p_values, posterior, color='steelblue', linewidth=2, label='后验')
ax.axvline(x=p_mle, color='coral', linestyle=':', alpha=0.7, label=f'MLE = {p_mle:.2f}')
ax.axvline(x=p_map, color='steelblue', linestyle=':', alpha=0.7, label=f'MAP = {p_map:.2f}')
ax.set_xlabel('p')
ax.set_ylabel('概率密度')
ax.set_title('MLE vs MAP(只有 3 次数据时)')
ax.legend()
ax.grid(True, alpha=0.3)
plt.show()
预期输出:
MLE: p = 0.990
MAP: p = 0.637
解读:
- MLE 给出接近 p=1.0 的结果(完全被少量数据带偏)
- MAP 给出 p≈0.64(在数据和先验之间折中)
- 随着数据增多,MAP 和 MLE 会趋于一致
MLE vs MAP
| MLE | MAP | |
|---|---|---|
| 使用先验? | 否 | 是 |
| 数据少时 | 容易过拟合 | 更稳定 |
| 数据多时 | 和 MAP 趋同 | 和 MLE 趋同 |
| AI 中的对应 | 普通训练 | 正则化(如 L2 正则化 = 高斯先验) |
L2 正则化(又叫 weight decay)本质上就是 MAP——它假设权重的先验是均值为 0 的正态分布,鼓励权重不要太大。这就是为什么正则化能防止过拟合。
三、假设检验与 A/B 测试
日常场景
你改了网站的按钮颜色(A 版用蓝色,B 版用绿色),B 版的点击率高了 2%。
问题:这个差异是真实的,还是只是随机波动?
假设检验的思路
p 值的直觉
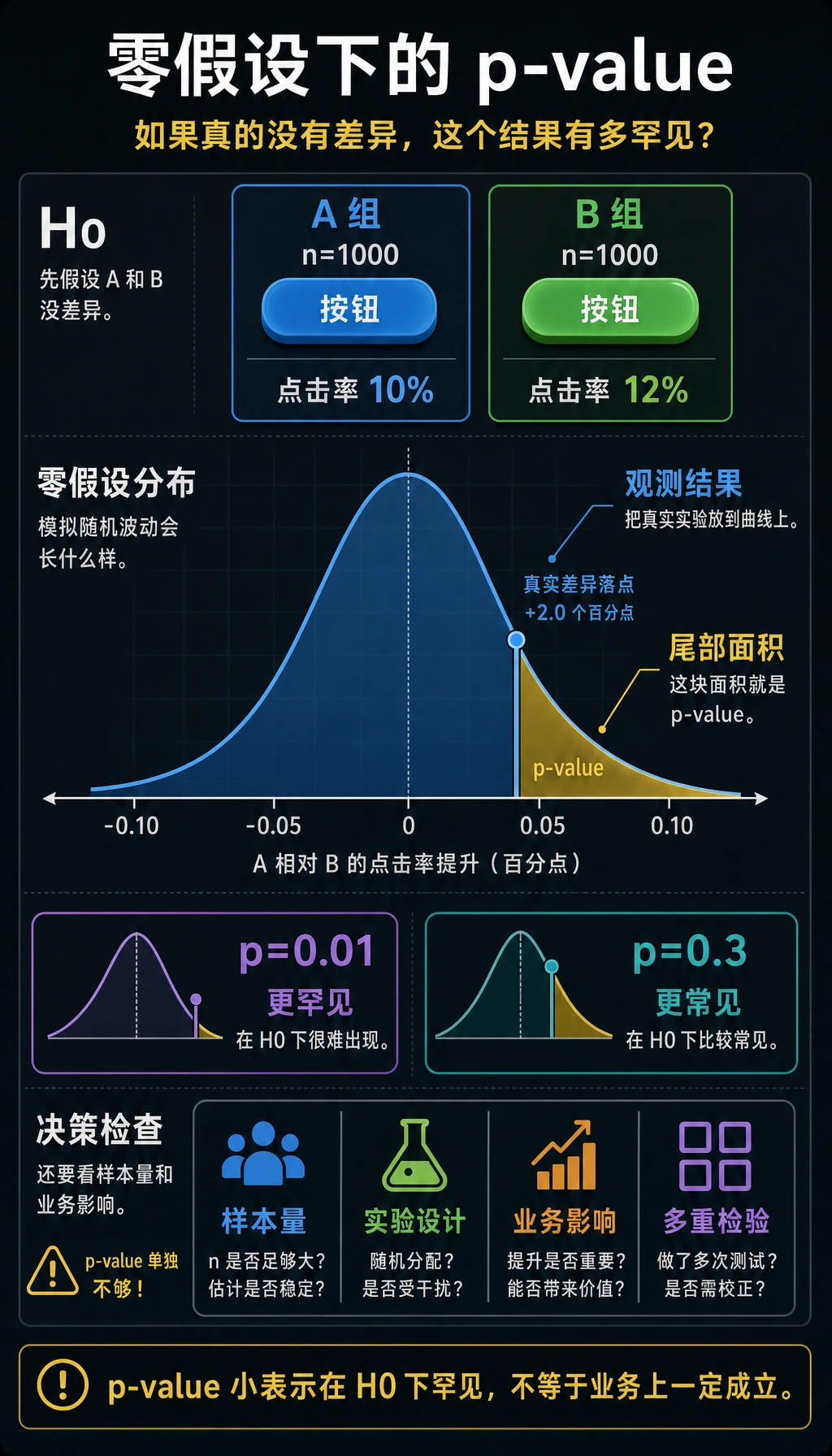
p 值 = 假设没有真实差异,仅靠随机波动产生这么大(或更大)差异的概率。
- p 值小(比如 0.01)→ "如果真没差异,这种结果几乎不可能出现" → 差异是真实的
- p 值大(比如 0.3)→ "就算没有真实差异,这种结果也很常见" → 可能只是随机波动
措辞上要小心:p 值并不能证明备择假设一定为真。它只是在告诉你,在零假设成立时,当前结果是否“不寻常”。真实产品里还要同时检查样本量、实验设计、业务收益,以及有没有一次性跑太多检验。
A/B 测试实战
# 模拟 A/B 测试
rng = np.random.default_rng(seed=2)
# A 组:蓝色按钮,真实点击率 10%
n_a = 1000
clicks_a = rng.binomial(n_a, 0.10)
rate_a = clicks_a / n_a
# B 组:绿色按钮,真实点击率 12%(真的更好)
n_b = 1000
clicks_b = rng.binomial(n_b, 0.12)
rate_b = clicks_b / n_b
print(f"A 组点击率: {rate_a:.1%} ({clicks_a}/{n_a})")
print(f"B 组点击率: {rate_b:.1%} ({clicks_b}/{n_b})")
print(f"差异: {rate_b - rate_a:.1%}")
# 使用 z 检验
from scipy.stats import norm
# 合并比例
p_pool = (clicks_a + clicks_b) / (n_a + n_b)
# 标准误
se = np.sqrt(p_pool * (1 - p_pool) * (1/n_a + 1/n_b))
# z 统计量
z = (rate_b - rate_a) / se
# p 值(单侧)
p_value = 1 - norm.cdf(z)
print(f"\nz 统计量: {z:.3f}")
print(f"p 值: {p_value:.4f}")
if p_value < 0.05:
print("→ p < 0.05,差异显著!B 版确实更好。")
else:
print("→ p >= 0.05,差异不显著,可能是随机波动。")
使用 seed=2 时,预期输出:
A 组点击率: 10.3% (103/1000)
B 组点击率: 12.9% (129/1000)
差异: 2.6%
z 统计量: 1.816
p 值: 0.0347
→ p < 0.05,差异显著!B 版确实更好。
用模拟理解 p 值
# 模拟:如果 A 和 B 真的没有差异(都是 10%),会看到多大的差异?
rng = np.random.default_rng(seed=2)
n_simulations = 10000
simulated_diffs = []
for _ in range(n_simulations):
# 两组用同样的概率 10%
sim_a = rng.binomial(1000, 0.10) / 1000
sim_b = rng.binomial(1000, 0.10) / 1000
simulated_diffs.append(sim_b - sim_a)
simulated_diffs = np.array(simulated_diffs)
# 画分布
observed_diff = rate_b - rate_a
plt.figure(figsize=(10, 5))
plt.hist(simulated_diffs, bins=50, density=True, color='steelblue',
edgecolor='white', alpha=0.7, label='零假设下的差异分布')
plt.axvline(x=observed_diff, color='red', linewidth=2, linestyle='--',
label=f'观测到的差异: {observed_diff:.3f}')
# p 值 = 红线右边的面积
p_sim = (simulated_diffs >= observed_diff).mean()
plt.fill_between(np.linspace(observed_diff, 0.08, 100),
0, 30, alpha=0.3, color='red', label=f'p 值 ≈ {p_sim:.4f}')
plt.xlabel('点击率差异 (B - A)')
plt.ylabel('密度')
plt.title('p 值的直觉:观测到的差异有多"不寻常"?')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
如果想做数值检查,可以加一行:
print(f"模拟 p 值: {p_sim:.4f}")
使用 seed=2 时,预期输出:
模拟 p 值: 0.0262
四、MLE 与损失函数的联系
MLE = 最小化交叉熵
这是一个非常重要的联系——分类问题中,最大化似然等价于最小化交叉熵损失。
# 二分类问题
# 模型预测:p_hat = 模型认为标签为 1 的概率
# 真实标签:y ∈ {0, 1}
# 似然函数
# L = ∏ p_hat^y * (1-p_hat)^(1-y)
# 取对数(对数似然)
# log L = Σ [y * log(p_hat) + (1-y) * log(1-p_hat)]
# 最大化 log L = 最小化 -log L = 最小化交叉熵!
# 示例
y_true = np.array([1, 0, 1, 1, 0])
p_pred = np.array([0.9, 0.2, 0.8, 0.7, 0.3])
# 交叉熵(手算)
cross_entropy = -np.mean(
y_true * np.log(p_pred) + (1 - y_true) * np.log(1 - p_pred)
)
print(f"交叉熵损失: {cross_entropy:.4f}")
# 对数似然(手算)
log_likelihood = np.mean(
y_true * np.log(p_pred) + (1 - y_true) * np.log(1 - p_pred)
)
print(f"对数似然: {log_likelihood:.4f}")
print(f"交叉熵 = -对数似然: {-log_likelihood:.4f}")
预期输出:
交叉熵损失: 0.2530
对数似然: -0.2530
交叉熵 = -对数似然: 0.2530
当你看到 PyTorch 中的 nn.CrossEntropyLoss() 或 nn.BCELoss(),现在你知道了——它们本质上是在做最大似然估计。损失函数不是随便定义的,它有深刻的概率论基础。
学到这里,下一节该带着什么问题走?
看完这节以后,最值得带去下一节的是:
- 如果模型预测的是一个分布,那“分布和分布差多少”到底怎么量?
- 为什么交叉熵能同时像信息论概念,又像训练损失?
- KL 散度为什么会反复出现在 VAE、RLHF 和蒸馏里?
这几个问题,正好会把你自然带到:
- 下一节:信息论——从另一个角度理解交叉熵
- 第 5 站:逻辑回归的损失函数就是交叉熵(来自 MLE)
- 第 5 站:正则化(L1/L2)的概率解释是 MAP
- 第 6 站:神经网络训练 = 最小化损失函数 = 做 MLE/MAP
小结
| 概念 | 直觉 | 公式/代码 |
|---|---|---|
| MLE | 找最能解释数据的参数 | 最大化似然函数 |
| MAP | MLE + 先验知识 | 最大化 似然 × 先验 |
| p 值 | 差异有多"不寻常" | 零假设下观测到该差异的概率 |
| A/B 测试 | 比较两组是否有真实差异 | scipy.stats |
| 交叉熵 | 最小化交叉熵 = MLE | nn.CrossEntropyLoss() |
动手练习
练习 1:抛硬币 MLE
抛一枚硬币 100 次,得到 62 次正面。
- 用 MLE 估计 p
- 画出似然函数
- 如果先验是 Beta(10, 10),MAP 估计是多少?
参考实现:
n = 100
k = 62
p_vals = np.linspace(0.01, 0.99, 1000)
likelihood = p_vals**k * (1 - p_vals)**(n - k)
p_mle = p_vals[np.argmax(likelihood)]
prior = stats.beta.pdf(p_vals, 10, 10)
posterior = likelihood * prior
posterior = posterior / np.trapezoid(posterior, p_vals)
p_map = p_vals[np.argmax(posterior)]
print(f"MLE 估计: {p_mle:.3f}")
print(f"Beta(10, 10) 先验下的 MAP 估计: {p_map:.3f}")
预期输出:
MLE 估计: 0.620
Beta(10, 10) 先验下的 MAP 估计: 0.602
练习 2:A/B 测试
模拟一个 A/B 测试:A 组(n=500)真实转化率 8%,B 组(n=500)真实转化率 8%(没有差异)。运行 1000 次实验,统计有多少次 p 值小于 0.05(这就是"假阳率",理论上应该约 5%)。
参考实现:
rng = np.random.default_rng(seed=42)
false_positives = 0
n_runs = 1000
for _ in range(n_runs):
clicks_a = rng.binomial(500, 0.08)
clicks_b = rng.binomial(500, 0.08)
rate_a = clicks_a / 500
rate_b = clicks_b / 500
p_pool = (clicks_a + clicks_b) / 1000
se = np.sqrt(p_pool * (1 - p_pool) * (1/500 + 1/500))
if se == 0:
continue
z = (rate_b - rate_a) / se
p_value = 2 * (1 - norm.cdf(abs(z))) # 双侧检验
false_positives += p_value < 0.05
print(f"假阳率: {false_positives / n_runs:.1%} ({false_positives}/{n_runs})")
使用 seed=42 时,预期输出:
假阳率: 3.9% (39/1000)
练习 3:MLE 估计正态分布
从 N(5, 2) 生成 200 个样本,用 MLE 估计均值和标准差(正态分布的 MLE:均值=样本均值,标准差=样本标准差),和真实值对比。
参考实现:
rng = np.random.default_rng(seed=42)
samples = rng.normal(5, 2, 200)
mu_hat = samples.mean()
sigma_hat = np.sqrt(((samples - mu_hat) ** 2).mean())
print(f"估计均值: {mu_hat:.3f}(真实均值: 5)")
print(f"估计标准差: {sigma_hat:.3f}(真实标准差: 2)")
预期输出:
估计均值: 4.939(真实均值: 5)
估计标准差: 1.759(真实标准差: 2)