5.2.1 监督学习路线图:从有标签样本中学习
监督学习回答一个问题:当样本已经有标签时,怎样学出一个能预测新样本标签的模型?
先看模型选择地图
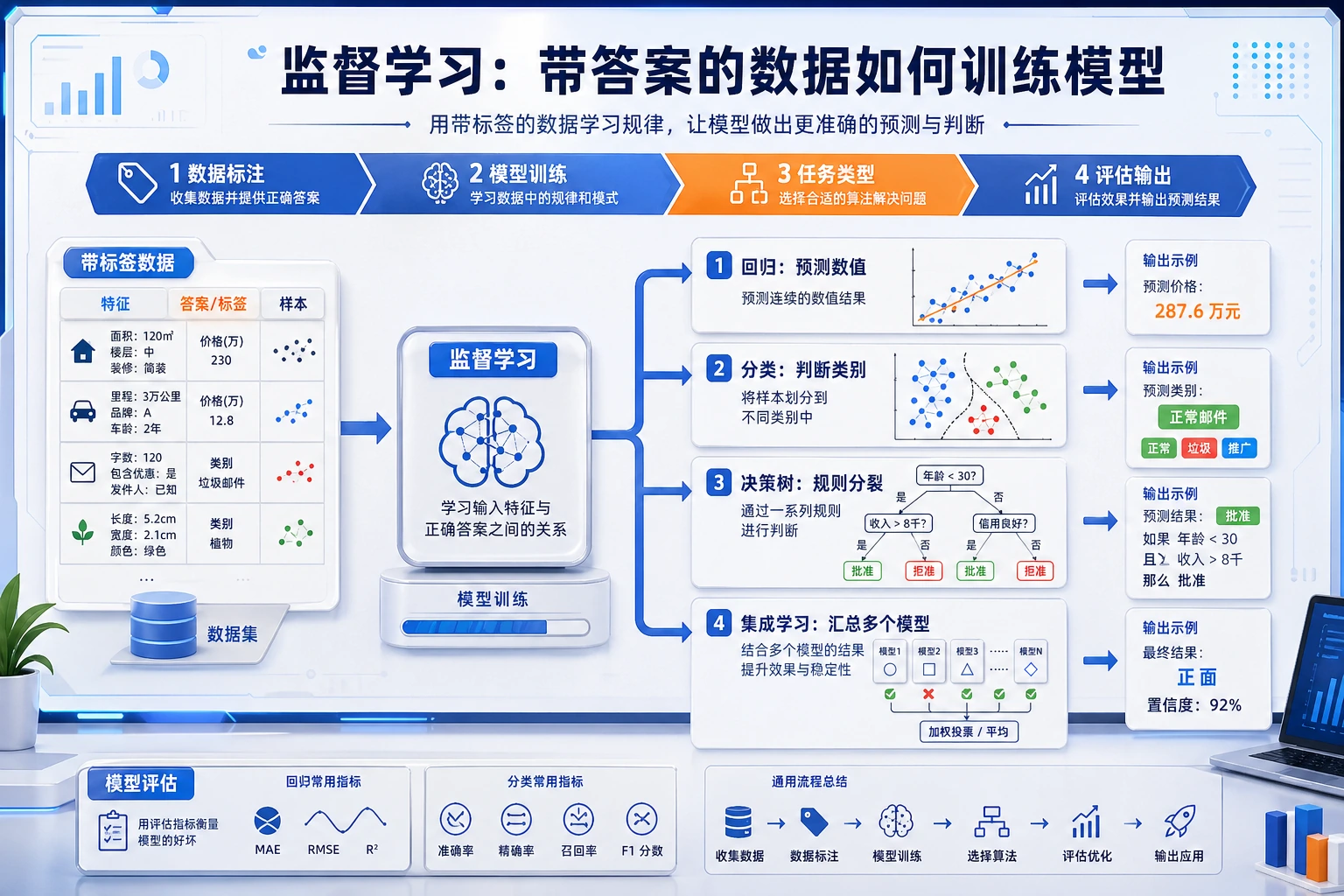
| 模型族 | 第一用途 |
|---|---|
| 线性回归 | 预测连续数值 |
| 逻辑回归 | 用简单概率模型做分类 |
| 决策树 | 用可读规则切分数据 |
| 集成模型 | 合并多个模型,做更强的表格 baseline |
| SVM | 用间隔直觉学习更稳定的边界 |
跑一个回归 baseline
创建 supervised_first_loop.py,安装 scikit-learn 后运行。
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
X, y = load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
model = LinearRegression().fit(X_train, y_train)
predictions = model.predict(X_test)
print("task: regression")
print("r2:", round(r2_score(y_test, predictions), 3))
print("first_prediction:", round(predictions[0], 1))
预期输出:
task: regression
r2: 0.485
first_prediction: 137.9
分数不完美也很有价值。baseline 告诉你后续模型或特征工程至少要超过哪里。
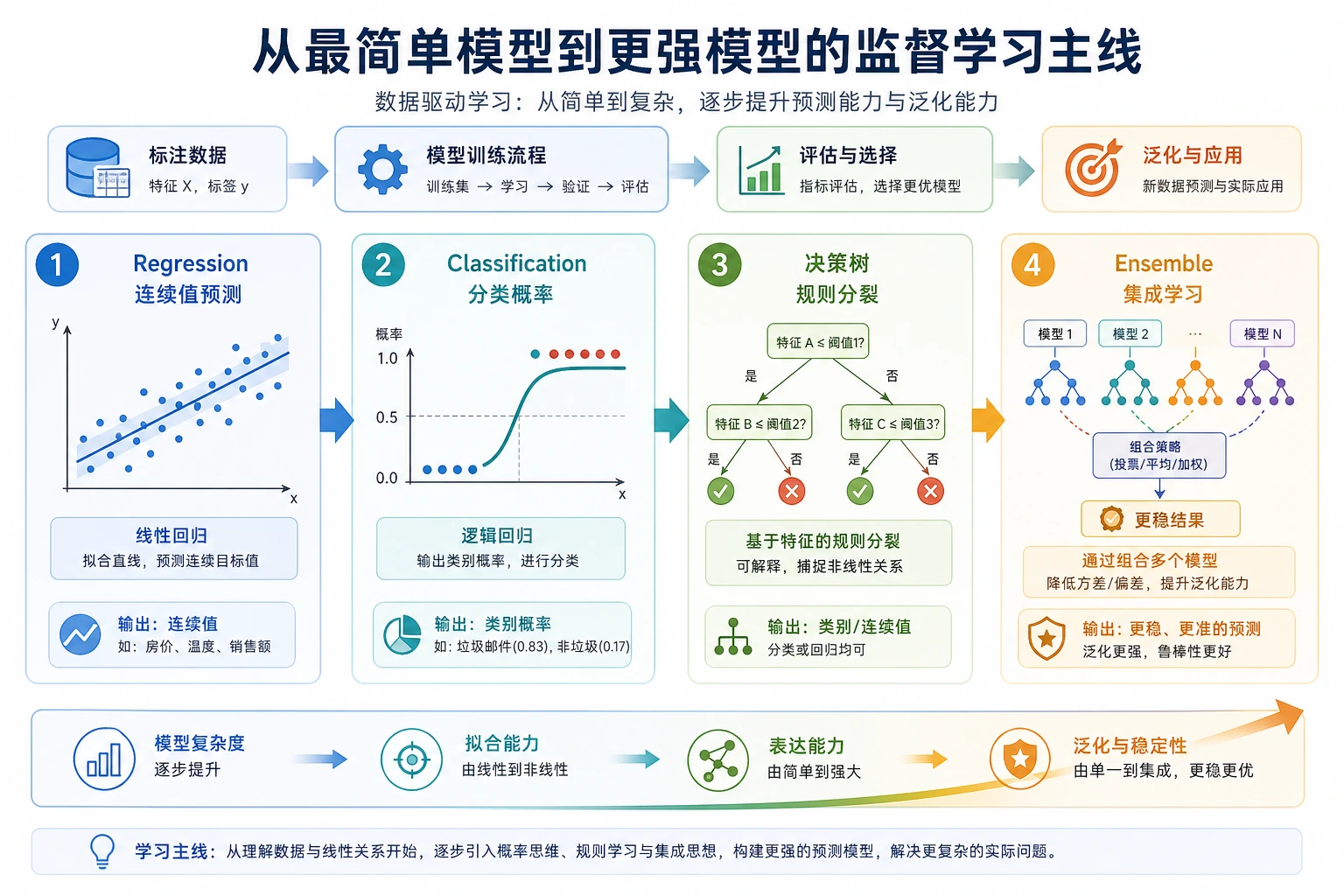
按这个顺序学
| 顺序 | 阅读 | 比较什么 |
|---|---|---|
| 1 | 5.2.2 线性回归 | 简单数值预测 |
| 2 | 5.2.3 逻辑回归 | 分类概率 |
| 3 | 5.2.4 决策树 | 规则、非线性、过拟合 |
| 4 | 5.2.5 集成学习 | bagging、boosting、更强表格模型 |
| 5 | 5.2.6 支持向量机 | 间隔、边界、经典分类器直觉 |
通过标准
能判断一个有标签任务是回归还是分类,能跑一个 baseline,并能解释模型可能失败的一个原因,就算通过。