5.1.1 机器学习基础路线图:任务、数据、模型、分数
机器学习从不再手写所有规则开始,而是让模型从数据中学习规律。第一习惯不是背算法,而是跑通小项目闭环。
先看地图
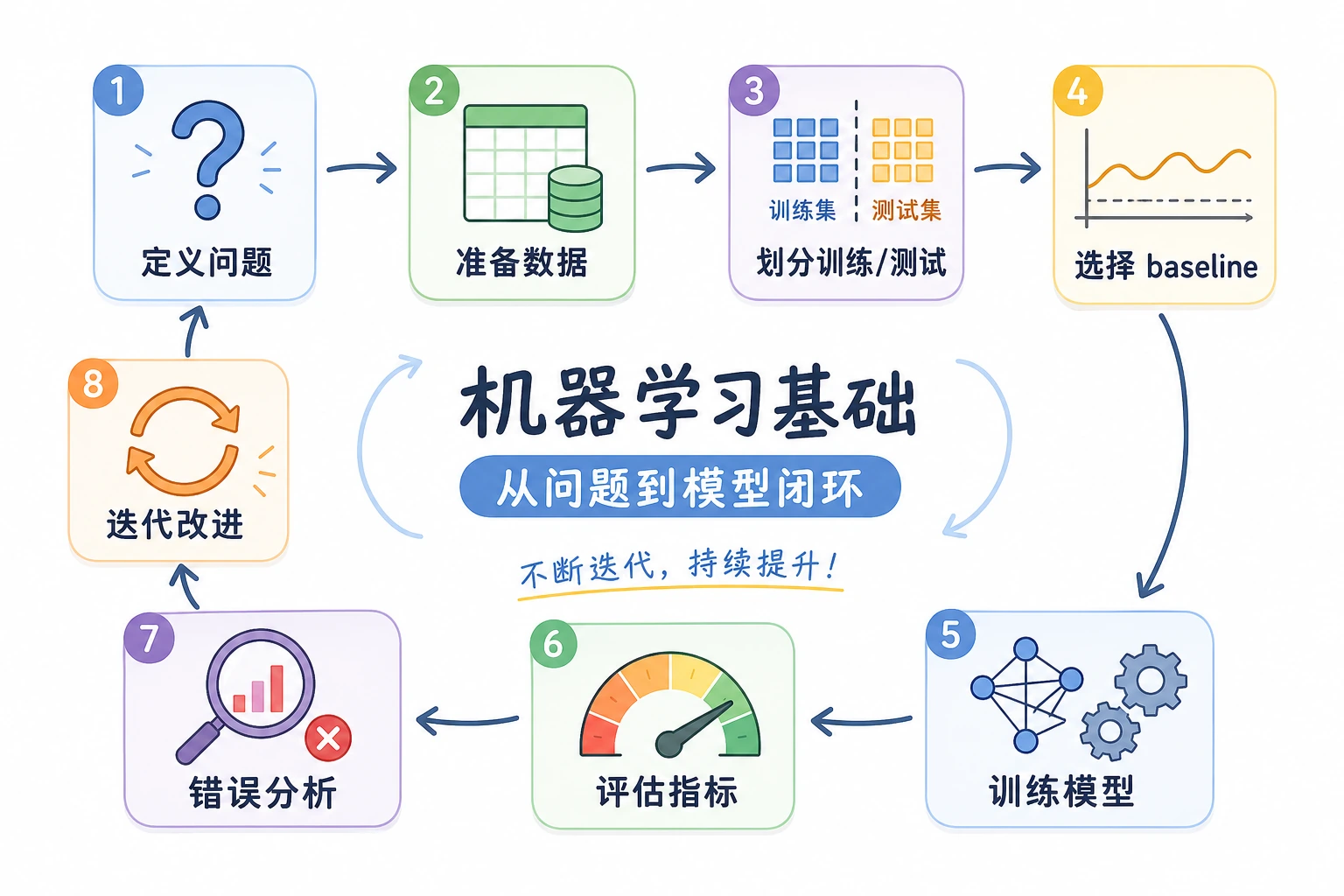
记住这个闭环:
定义任务 -> 划分数据 -> 训练模型 -> 预测 -> 评分 -> 决定下一步
| 词 | 第一层意思 |
|---|---|
| feature | 模型使用的输入列 |
| label / target | 模型要预测的答案 |
| train set | 用来学习的数据 |
| test set | 留出来检查泛化的数据 |
| baseline | 用来比较的简单首版模型 |
跑最小 sklearn 闭环
创建 ml_first_loop.py,安装 scikit-learn 后运行。
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print("task: classification")
print("test_accuracy:", round(model.score(X_test, y_test), 3))
print("prediction_count:", len(predictions))
预期输出:
task: classification
test_accuracy: 0.967
prediction_count: 30
这就是最小有用机器学习闭环:先划分数据,只用训练集训练,再用测试集评估。
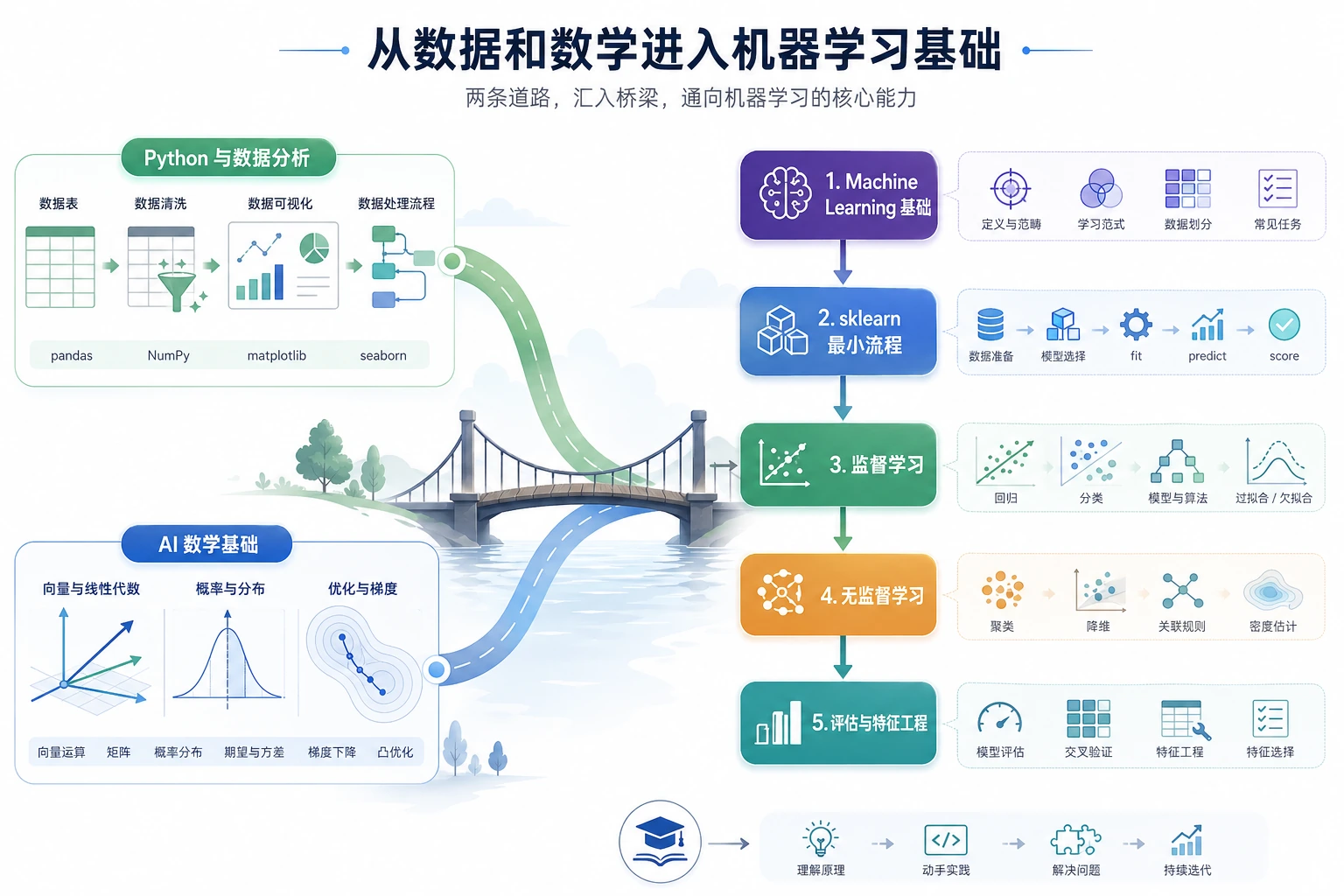
按这个顺序学
| 顺序 | 阅读 | 练什么 |
|---|---|---|
| 1 | 5.1.2 什么是机器学习 | 任务类型、特征、标签 |
| 2 | 5.1.3 Scikit-learn 入门 | fit、predict、score |
| 3 | 5.1.4 数学如何进入机器学习 | 向量、概率、loss、优化 |
| 4 | 5.1.5 机器学习发展史 | 主要算法为什么出现 |
| 5 | 5.1.6 sklearn 与 Matplotlib 工作坊 | 运行、画图、解释 baseline |
通过标准
能说出任务类型,识别 X 和 y,解释为什么要划分训练集/测试集,并保留一个 baseline 分数作为证据,就算通过。