6.1.3 从神经元到多层感知机
本节概览
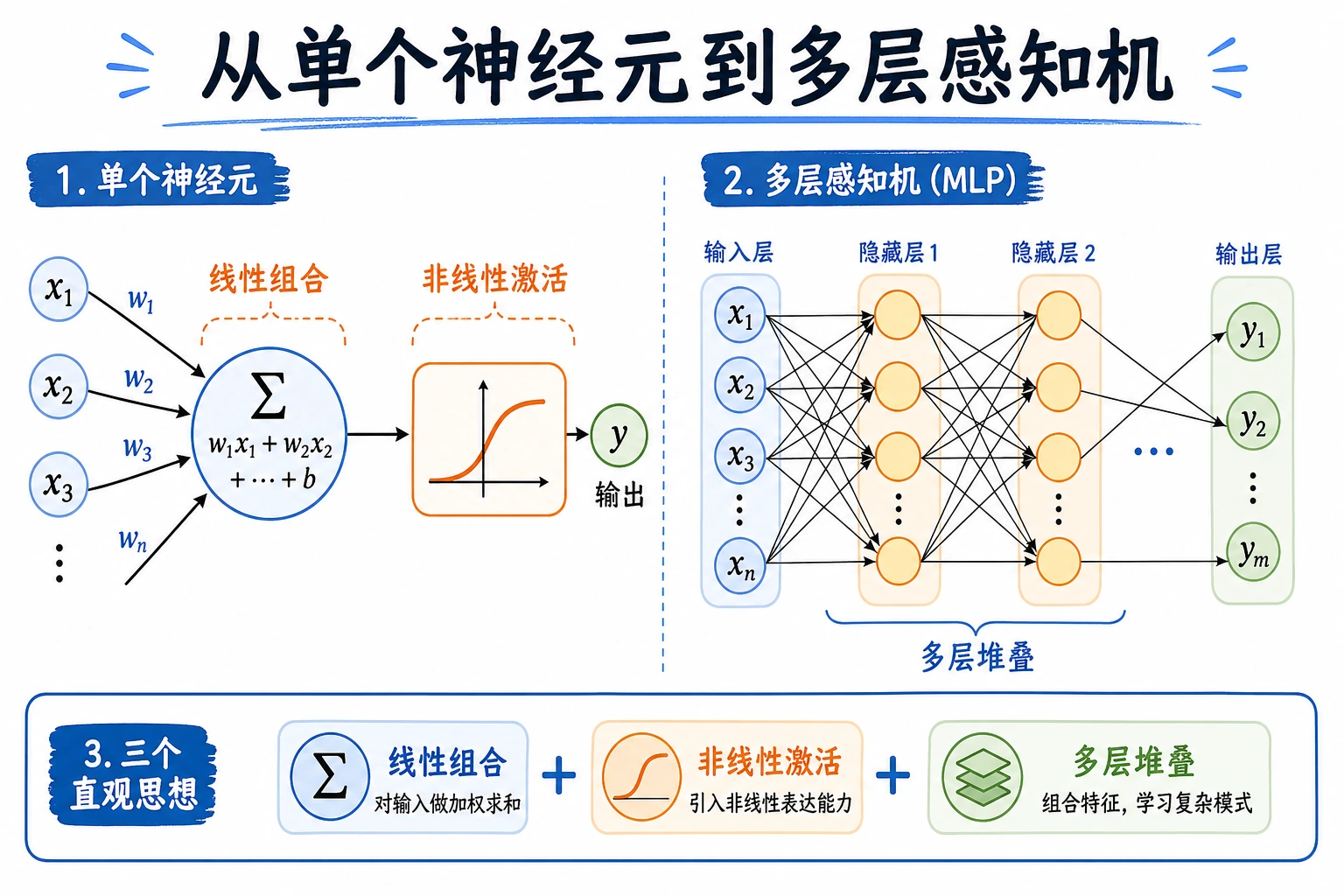
神经网络从一个简单想法开始:计算加权分数,经过非线性激活,再把许多这样的单元堆成层。
你会做出什么
这一节会运行一个小型 PyTorch 实验:
- 手动计算一个人工神经元;
- 比较
sigmoid和ReLU; - 训练一个很小的 MLP 解决 XOR;
- 解释为什么单个线性层不够。
核心路径是:
features -> weighted sum z -> activation a -> layer -> multilayer network
最小历史背景
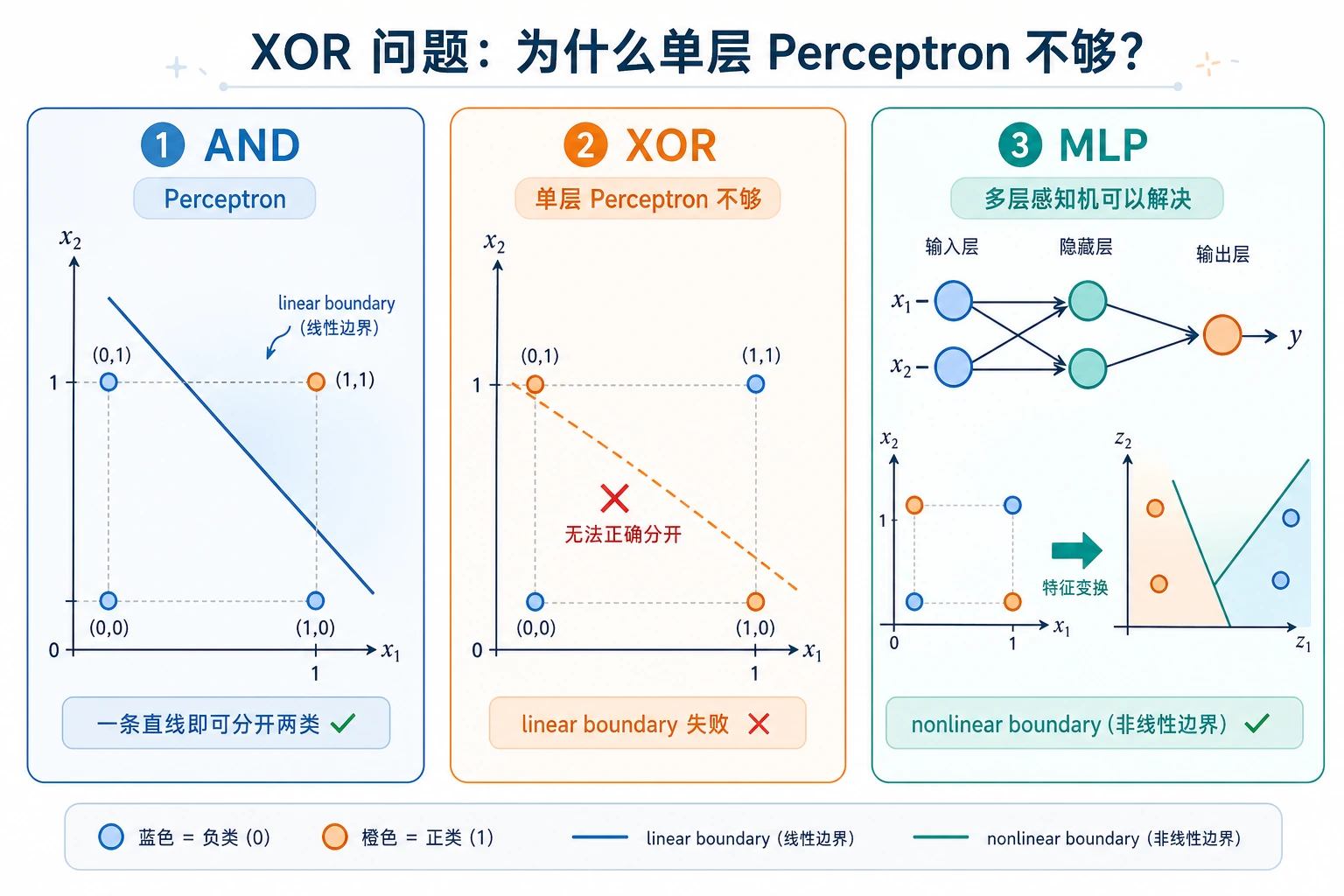
感知机曾让人兴奋,因为它证明机器可以从数据中学习规则。后来它又让人失望,因为单层感知机无法解决 XOR 这种简单非线性模式。
这段历史的重点是:
神经元本身很简单。真正带来表达能力的是带非线性激活的多层堆叠。
环境准备
python -m pip install -U torch
代码使用稳定的 PyTorch API:torch.Tensor、nn.Module、nn.Sequential、nn.Linear、激活函数、loss 和 optimizer。
运行完整实验
新建 neuron_mlp_lab.py:
import torch
import torch.nn as nn
torch.manual_seed(42)
x = torch.tensor([[0.8, 0.3, 0.5]])
w = torch.tensor([[0.2], [-0.4], [0.6]])
b = torch.tensor([0.1])
z = x @ w + b
print("single_neuron")
print("z=", round(float(z.item()), 3))
print("sigmoid=", round(float(torch.sigmoid(z).item()), 3))
print("relu=", round(float(torch.relu(z).item()), 3))
xor_x = torch.tensor([[0., 0.], [0., 1.], [1., 0.], [1., 1.]])
xor_y = torch.tensor([[0.], [1.], [1.], [0.]])
class TinyMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 4),
nn.Tanh(),
nn.Linear(4, 1),
nn.Sigmoid(),
)
def forward(self, x):
return self.net(x)
model = TinyMLP()
loss_fn = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
for step in range(2000):
pred = model(xor_x)
loss = loss_fn(pred, xor_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
prob = model(xor_x)
pred = (prob >= 0.5).float()
print("xor_mlp")
for row, p, y_hat in zip(xor_x.tolist(), prob.squeeze().tolist(), pred.squeeze().tolist()):
print(f"x={row} prob={p:.3f} pred={int(y_hat)}")
print("final_loss=", round(float(loss.item()), 4))
运行:
python neuron_mlp_lab.py
预期输出:
single_neuron
z= 0.44
sigmoid= 0.608
relu= 0.44
xor_mlp
x=[0.0, 0.0] prob=0.000 pred=0
x=[0.0, 1.0] prob=1.000 pred=1
x=[1.0, 0.0] prob=1.000 pred=1
x=[1.0, 1.0] prob=0.000 pred=0
final_loss= 0.0001

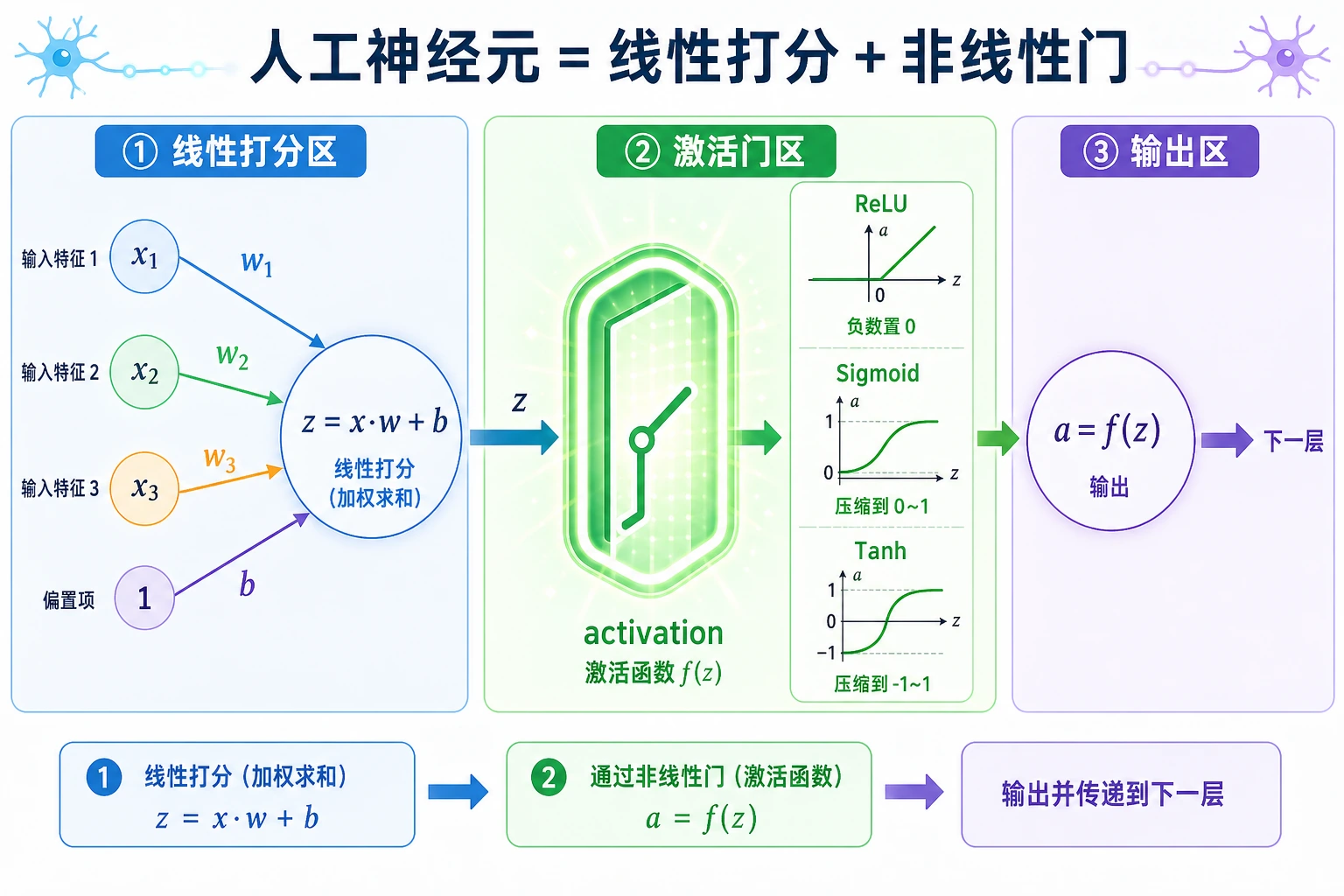
读懂一个神经元
第一段代码计算的是:
z = x @ w + b
输出里:
z= 0.44
sigmoid= 0.608
relu= 0.44
加权分数 z 仍然是线性的。激活函数决定信号如何继续传递:
| 激活函数 | 做什么 | 常见用途 |
|---|---|---|
Sigmoid | 压到 0-1 | 二分类概率输出 |
Tanh | 压到 -1 到 1 | 小实验、部分序列模型 |
ReLU | 保留正值,负值归零 | 常见隐藏层默认选择 |
为什么激活函数重要
如果只堆线性层,整个网络仍然等价于一个更大的线性层。非线性激活才让多层网络能表达弯曲边界。
所以这个 MLP 使用:
nn.Linear(2, 4),
nn.Tanh(),
nn.Linear(4, 1),
nn.Sigmoid(),
隐藏层的 Tanh 提供非线性表达能力。最后的 Sigmoid 把输出变成类似概率的二分类结果。
为什么 XOR 是经典测试
XOR 只有四行:
| x1 | x2 | y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
一条直线无法把这些标签分开,所以单层感知机会失败。小型 MLP 能成功,是因为它先创建了中间隐藏特征,再做最终判断。
常见排查清单
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| loss 不下降 | 学习率过高/过低,loss 搭配错误 | 降低 LR,检查输出激活和 loss 是否匹配 |
| 概率都接近 0.5 | 模型没有学到 | 训练更久,检查梯度,调整 hidden size |
| output shape 报错 | target shape 和 prediction 不一致 | 本例二分类 target 使用 [batch, 1] |
出现 nan | 训练不稳定 | 降低学习率,检查输入 |
| 训练集能学会但真实数据不行 | 记忆训练集 | 使用 train/validation split 和正则化 |
练习
- 把隐藏单元从
4改成2。XOR 是否仍然稳定学会? - 把
nn.Tanh()换成nn.ReLU()。结果有什么变化? - 每 200 步打印一次 loss,观察训练曲线。
- 移除隐藏层激活函数,并解释为什么模型变弱。
- 再加一层隐藏层,对比 final loss。
过关检查
你能解释下面几点,就完成本节:
- 神经元先计算
x @ w + b,再应用激活函数; - 激活函数引入非线性;
- 单层感知机不能解决 XOR;
- MLP 通过堆叠层构造中间特征;
- PyTorch 模型通常由
nn.Module、loss、optimizer、backward()和step()组成。