6.4.2 RNN 基础
本节定位
CNN 扫描空间,RNN 扫描时间。核心想法很简单:读当前一步,结合上一步压缩出来的记忆,再更新这份记忆。
学习目标
- 解释为什么顺序在序列任务里重要。
- 手算一个极小的 hidden state 更新。
- 读懂 PyTorch 中
nn.RNN的输入输出 shape。 - 搭建一个小型 many-to-one 序列分类器。
- 理解普通 RNN 为什么难处理长依赖。
先看 hidden state 循环
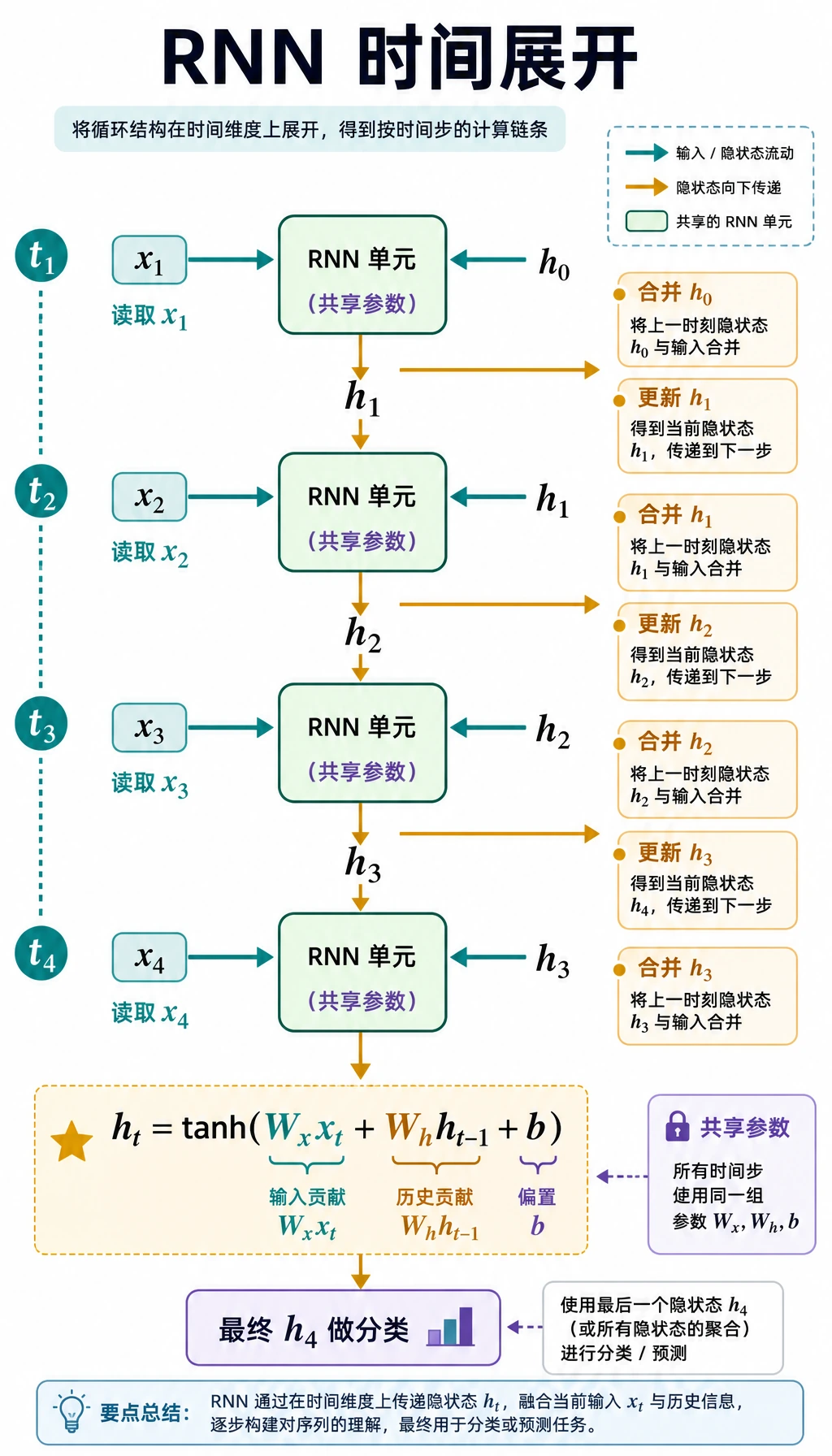
按这个方式读图:
x_t + h_{t-1} -> RNN cell -> h_t
同一个 RNN cell 会在每个时间步重复使用。所以 RNN 能处理长度为 5 或 50 的序列,而不需要给每个位置都新建一套参数。
为什么序列任务不一样
顺序本身就是信息。
| 数据 | 为什么顺序重要 |
|---|---|
| 句子 | “not good”和“good, not hard”含义不同 |
| 股票 / 传感器序列 | 趋势依赖前面的数值 |
| 用户点击 | 后续行为依赖前面的意图 |
| 日志 | 同一个事件在前面出错后可能含义不同 |
MLP 可以处理固定向量,但不会自然地把记忆从一步带到下一步。RNN 补上的就是这个状态。
实验 1:手动更新 hidden state
一个最小 RNN 更新可以写成:
h_t = tanh(W_x * x_t + W_h * h_{t-1} + b)
先运行一个标量版本:
import numpy as np
x_seq = [1.0, 0.5, -1.0, 2.0]
W_x = 0.8
W_h = 0.5
b = 0.1
h = 0.0
print("manual_rnn_lab")
for t, x_t in enumerate(x_seq, start=1):
prev_h = h
h = np.tanh(W_x * x_t + W_h * h + b)
print(f"step={t} x={x_t:4.1f} prev_h={prev_h: .4f} h={h: .4f}")
预期输出:
manual_rnn_lab
step=1 x= 1.0 prev_h= 0.0000 h= 0.7163
step=2 x= 0.5 prev_h= 0.7163 h= 0.6953
step=3 x=-1.0 prev_h= 0.6953 h=-0.3385
step=4 x= 2.0 prev_h=-0.3385 h= 0.9106
重点看这个依赖关系:
新的 h 依赖当前 x 和上一个 h
这就是 RNN 的核心。
实验 2:读懂 PyTorch RNN shape
设置 batch_first=True 后,输入 shape 更好读:
[batch, seq_len, input_size]
运行:
import torch
torch.manual_seed(42)
x = torch.randn(2, 5, 4)
rnn = torch.nn.RNN(input_size=4, hidden_size=6, batch_first=True)
out, h = rnn(x)
print("shape_lab")
print("x:", tuple(x.shape))
print("out:", tuple(out.shape))
print("h:", tuple(h.shape))
print("last_equal:", torch.allclose(out[:, -1, :], h[-1]))
预期输出:
shape_lab
x: (2, 5, 4)
out: (2, 5, 6)
h: (1, 2, 6)
last_equal: True
仔细读:
| Tensor | Shape | 含义 |
|---|---|---|
x | [2, 5, 4] | 2 条序列,每条 5 步,每步 4 个特征 |
out | [2, 5, 6] | 每个时间步的 hidden output |
h | [1, 2, 6] | 1 层 RNN 的最终 hidden state,batch 为 2,hidden size 为 6 |
对于单层 RNN,out[:, -1, :] 等于 h[-1]。
输出模式
| 模式 | 用途 | 使用哪个输出 |
|---|---|---|
| many-to-one | 情感、趋势类别、垃圾邮件类别 | final hidden state |
| many-to-many | 给每个 token 或时间步打标签 | 每个时间步的 out |
| sequence-to-sequence | 翻译、摘要 | encoder/decoder 结构 |
本页先聚焦 many-to-one,因为它是最容易上手的 RNN 任务。
实验 3:训练一个小型序列分类器
任务:判断一段短数值序列整体偏正还是偏负。
import torch
from torch import nn
torch.manual_seed(42)
X = torch.tensor(
[
[[1.0], [1.2], [1.3], [1.1], [1.0]],
[[-1.0], [-1.1], [-1.3], [-0.9], [-1.2]],
[[0.8], [0.7], [1.0], [0.9], [1.1]],
[[-0.6], [-0.7], [-0.9], [-1.0], [-0.8]],
]
)
y = torch.tensor([1, 0, 1, 0])
class SimpleRNNClassifier(nn.Module):
def __init__(self):
super().__init__()
self.rnn = nn.RNN(input_size=1, hidden_size=8, batch_first=True)
self.fc = nn.Linear(8, 2)
def forward(self, x):
out, h = self.rnn(x)
return self.fc(out[:, -1, :])
model = SimpleRNNClassifier()
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.05)
for epoch in range(1, 101):
logits = model(X)
loss = loss_fn(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch == 1 or epoch % 25 == 0:
acc = (logits.argmax(1) == y).float().mean().item()
print(f"trend epoch={epoch:03d} loss={loss.item():.4f} acc={acc:.3f}")
with torch.no_grad():
result = model(X).argmax(dim=1)
print("predictions:", result.tolist())
print("truth:", y.tolist())
预期输出:
trend epoch=001 loss=0.7726 acc=0.000
trend epoch=025 loss=0.0002 acc=1.000
trend epoch=050 loss=0.0001 acc=1.000
trend epoch=075 loss=0.0000 acc=1.000
trend epoch=100 loss=0.0000 acc=1.000
predictions: [1, 0, 1, 0]
truth: [1, 0, 1, 0]
这个例子很小,但它是完整 RNN 闭环:序列 tensor、循环层、最终 hidden 表示、分类器、loss、optimizer 和预测。
普通 RNN 卡在哪里
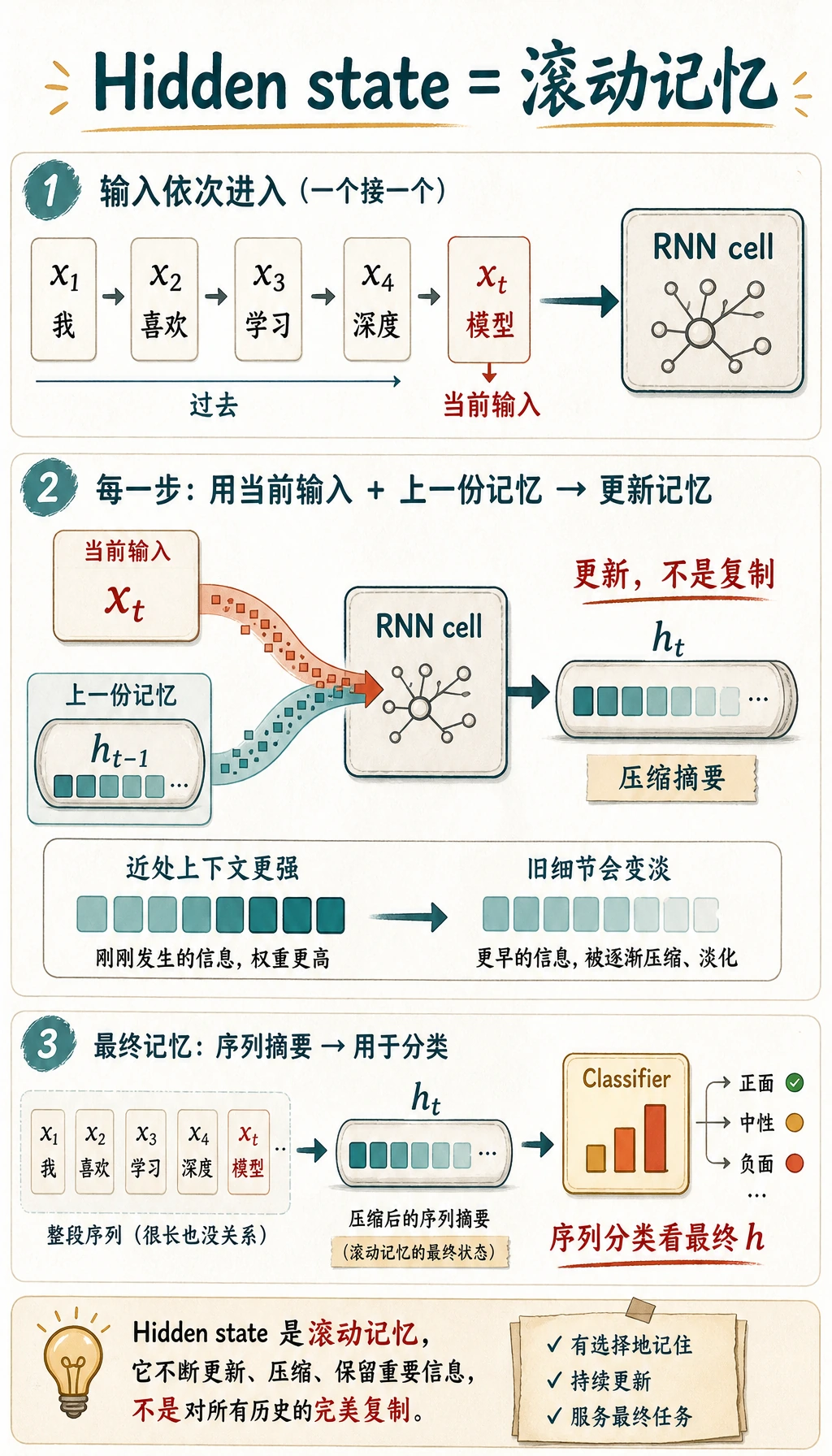
hidden state 是压缩记忆,不是精确记忆。序列变长后会出现两个问题:
| 问题 | 含义 |
|---|---|
| 信息被冲淡 | 很早的信息越来越难保留 |
| 梯度消失 | 训练信号传回早期时间步时变弱 |
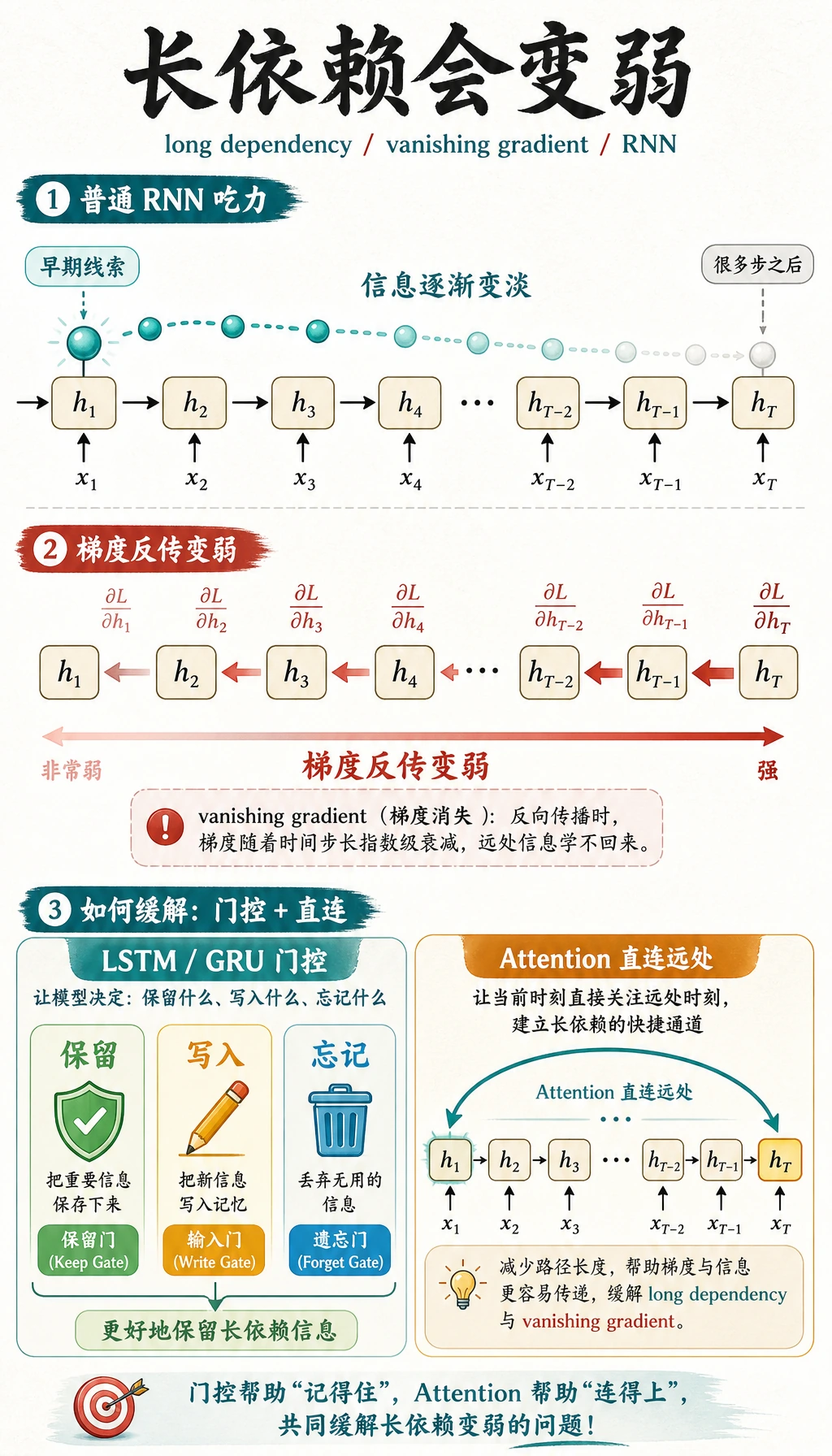
这就是 LSTM 和 GRU 要加入门控机制的原因:让模型更好地决定保留、更新或丢弃信息。
常见错误
| 错误 | 修复 |
|---|---|
| 搞混 shape 顺序 | batch_first=True 时使用 [batch, seq_len, input_size] |
搞混 out 和 h | out 有每一步;h 是每层最终 hidden state |
在 CrossEntropyLoss 前先 softmax | 把原始 logits 传给 loss |
| 期待普通 RNN 记住所有内容 | 长依赖用 LSTM/GRU 或 attention |
| 忘记序列长度 | 设计模型前先打印 tensor shape |
练习
- 把实验 1 的
W_h从0.5改成0.9,hidden state 怎么变? - 把实验 2 的
hidden_size从6改成12,哪些 shape 变了? - 在实验 3 中,把正负序列改成递增 / 递减序列。
- 在分类器中用
out.mean(dim=1)替代out[:, -1, :],还能学会吗? - 解释为什么很长的句子对普通 RNN 很难。
小结
- RNN 面向有顺序的数据,前面的步骤会影响后面的理解。
- hidden state 是一份压缩的滚动记忆。
- 同一个 RNN cell 会沿时间步反复使用。
- PyTorch RNN 在
batch_first=True时最容易读。 - 普通 RNN 很适合理解直觉,但 LSTM/GRU 更擅长处理长依赖。