7.3.5 高效注意力机制
当序列长度还很短时,普通自注意力看起来几乎没有问题。 但一旦上下文长度从几百扩到几万,你很快就会发现:
- 显存开始爆
- 速度开始慢
- 推理时 KV cache 越攒越大
所以“高效注意力”并不是一个单一技巧, 而是一大类为了让 Transformer 在更长上下文、更大模型下还能跑得动的改造。
学习目标
- 理解普通注意力为什么会在长上下文下变贵
- 区分不同高效路线分别在优化什么瓶颈
- 通过一个可运行示例感受全局注意力和局部注意力的差别
- 建立训练期和推理期效率问题的第一层判断
一、普通注意力到底贵在哪里?
每个 token 都要和很多 token 比较
假设序列长度是 n。
普通自注意力里,每个位置都要和其他位置做相似度计算。
于是比较次数大约是:
n * n
也就是:
O(n^2)
当 n = 512 时还不算夸张,
但当 n = 32768 时,情况就完全不同了。
长度翻倍,开销不是翻倍
这正是很多新人最容易低估的地方。
序列长度如果从:
- 4k -> 8k
不是开销简单乘以 2, 而是很多部分接近乘以 4。
所以长上下文模型真正难的地方,不是“支持更多 token”这句话, 而是:
怎样在代价不爆炸的前提下支持更多 token。
训练和推理的痛点还不完全一样
训练时更常见的压力是:
- 注意力矩阵太大
- 中间激活太多
推理时更常见的压力是:
- KV cache 越积越大
- 长会话越聊越慢、越占内存
所以高效注意力方法也分很多路线, 不是所有方法都在解决同一个问题。
二、先把几条主流路线分开
滑动窗口 / 局部注意力:减少“谁看谁”
最直观的一条路线是:
- 不让每个 token 看全世界
- 只让它看附近一小段窗口
这相当于说:
- 远处信息不是完全不要
- 但不是每一层、每个位置都必须全量对齐
典型思路有:
- sliding window attention
- local attention
MQA / GQA:减少 KV cache 体积
另一条很重要的路线不是改 mask,
而是改多头注意力的 K / V 组织方式。
普通多头注意力里,不同 head 往往各自有一套 K/V。 这会让推理期 KV cache 体积非常大。
于是出现了:
- MQA:多个 query head 共享一组 K/V
- GQA:把 query head 分组共享 K/V
它们的核心收益更偏向:
- 推理内存更省
- 吞吐更好
FlashAttention:不是改公式,而是改算的方式
FlashAttention 很容易被误解成:
- 一种新的注意力定义
其实更准确的理解是:
注意力公式基本不变,但通过更高效的分块计算与内存读写方式,减少显存开销和访存浪费。
它优化的重点是:
- 训练和推理时的实现效率
而不是让模型突然能理解完全不同的关系。
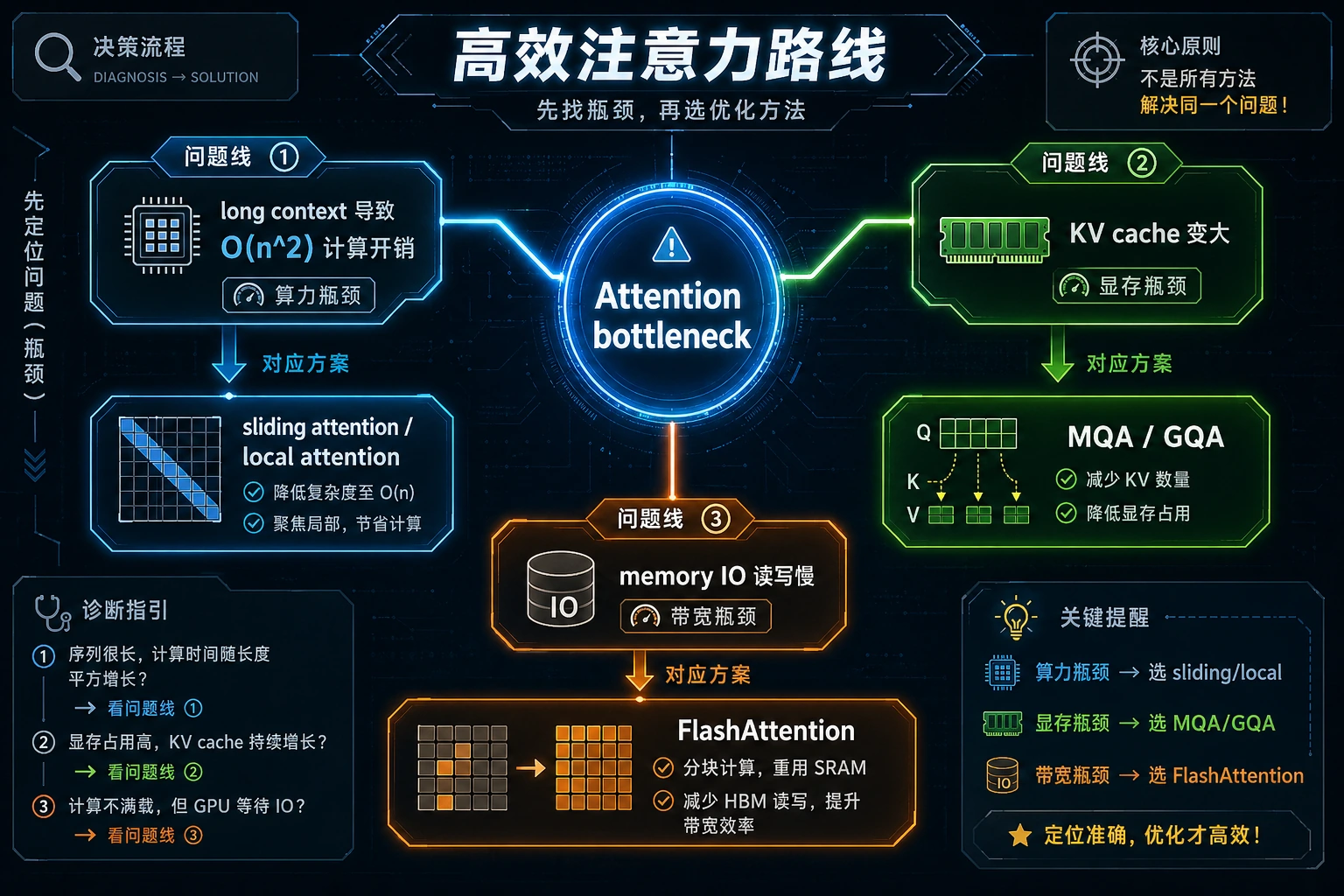
这张图不是让你背方法名,而是先分清瓶颈:上下文太长时看 sliding/local attention,KV cache 太大时看 MQA/GQA,显存读写太贵时看 FlashAttention。高效注意力是一组工程取舍,不是一种万能公式。
线性注意力:尝试从公式层面降复杂度
还有一类方法更激进, 它会直接改写注意力计算形式,希望把复杂度从平方级降下来。
这类方法通常会在:
- 理论复杂度
- 表达能力
- 实际效果
之间做权衡。
三、先跑一个真正说明问题的示例
下面这个例子会比较两件事:
- 全局注意力:每个位置都能看所有位置
- 局部注意力:每个位置只能看附近窗口
我们不仅会比较“能看谁”, 还会比较需要处理的 pair 数量。
from math import exp
values = [0.2, 0.1, 0.0, 0.8, 0.9, 0.7, 0.1, 0.0]
def softmax(scores):
m = max(scores)
exps = [exp(x - m) for x in scores]
total = sum(exps)
return [x / total for x in exps]
def attention_outputs(sequence, window=None):
outputs = []
pairs = 0
neighborhoods = []
for i in range(len(sequence)):
if window is None:
neighbors = list(range(len(sequence)))
else:
left = max(0, i - window)
right = min(len(sequence), i + window + 1)
neighbors = list(range(left, right))
neighborhoods.append(neighbors)
pairs += len(neighbors)
scores = [sequence[i] * sequence[j] for j in neighbors]
weights = softmax(scores)
output = sum(w * sequence[j] for w, j in zip(weights, neighbors))
outputs.append(output)
return outputs, pairs, neighborhoods
full_outputs, full_pairs, full_neighbors = attention_outputs(values, window=None)
local_outputs, local_pairs, local_neighbors = attention_outputs(values, window=2)
print("full pairs :", full_pairs)
print("local pairs:", local_pairs)
print("token 4 full neighbors :", full_neighbors[4])
print("token 4 local neighbors:", local_neighbors[4])
print("full outputs :", [round(x, 3) for x in full_outputs])
print("local outputs:", [round(x, 3) for x in local_outputs])
预期输出:
full pairs : 64
local pairs: 34
token 4 full neighbors : [0, 1, 2, 3, 4, 5, 6, 7]
token 4 local neighbors: [2, 3, 4, 5, 6]
full outputs : [0.376, 0.363, 0.35, 0.457, 0.47, 0.443, 0.363, 0.35]
local outputs: [0.101, 0.285, 0.4, 0.604, 0.615, 0.592, 0.44, 0.267]
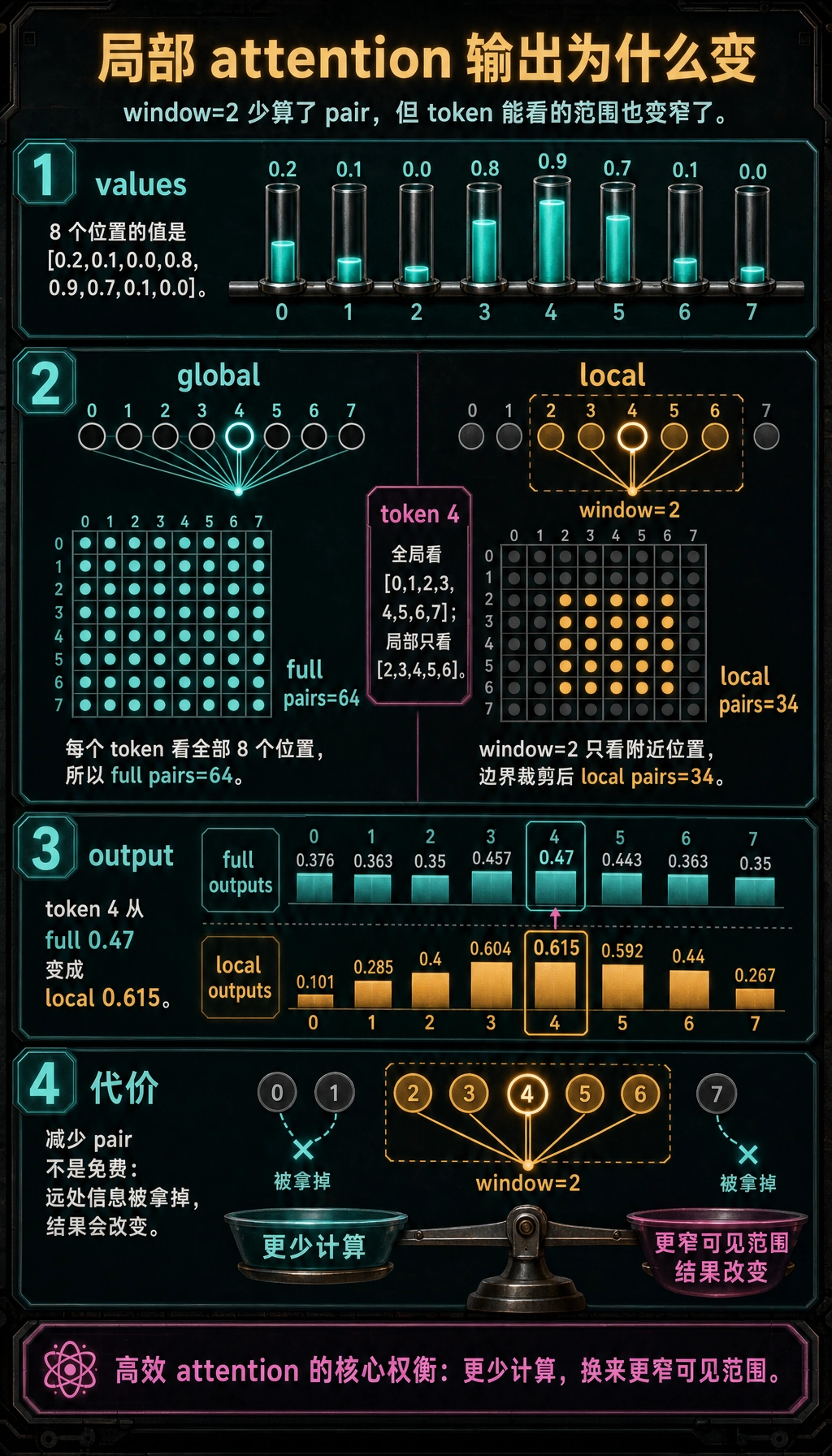
这段代码到底对应了什么直觉?
它告诉你两件特别关键的事:
- 如果限制每个位置只看局部,pair 数量会明显下降
- 但输出也会变,因为模型失去了远处信息
这正是高效注意力最核心的现实:
你不是在免费提速,而是在效率和可见范围之间做权衡。
为什么 full pairs 和 local pairs 差很多?
因为全局注意力里每个位置都看全部位置。 局部注意力里,每个位置只看窗口附近。
当序列长度很长时,这种差距会迅速放大。
为什么局部注意力不一定就更差?
因为很多信息本来就具有局部性。 例如语言里:
- 最近几个 token 往往最相关
- 远程依赖虽然重要,但不一定每一层都要全量建模
所以很多长上下文模型会采用:
- 部分层全局
- 部分层局部
- 或者带稀疏模式的混合方案
四、推理期另一个大头:KV cache
为什么聊天越长,推理越吃内存?
因为 decoder-only 模型在生成时,
前面每一步的 K / V 都会缓存下来,供后续 token 重用。
这就是:
- KV cache
它能显著减少重复计算, 但代价是:
- 会话越长,缓存越大
MQA / GQA 到底在省什么?
它们省的不是注意力矩阵本身, 而是每层每步要保存的 K/V 体积。
简单理解:
- 普通 MHA:每个 head 都有自己的 K/V
- MQA:很多 query head 共用一组 K/V
- GQA:一组 query head 共用一组 K/V
所以它们尤其适合:
- 大模型推理
- 长对话
- 高吞吐服务
一个简单的“谁更省”的估算
def kv_units(num_query_heads, num_kv_heads, head_dim, seq_len):
return num_kv_heads * head_dim * seq_len * 2
seq_len = 8192
head_dim = 128
print("MHA units =", kv_units(32, 32, head_dim, seq_len))
print("GQA units =", kv_units(32, 8, head_dim, seq_len))
print("MQA units =", kv_units(32, 1, head_dim, seq_len))
预期输出:
MHA units = 67108864
GQA units = 16777216
MQA units = 2097152
这里的数字不是完整显存公式, 但足够建立第一层直觉:
num_kv_heads越少- KV cache 越小
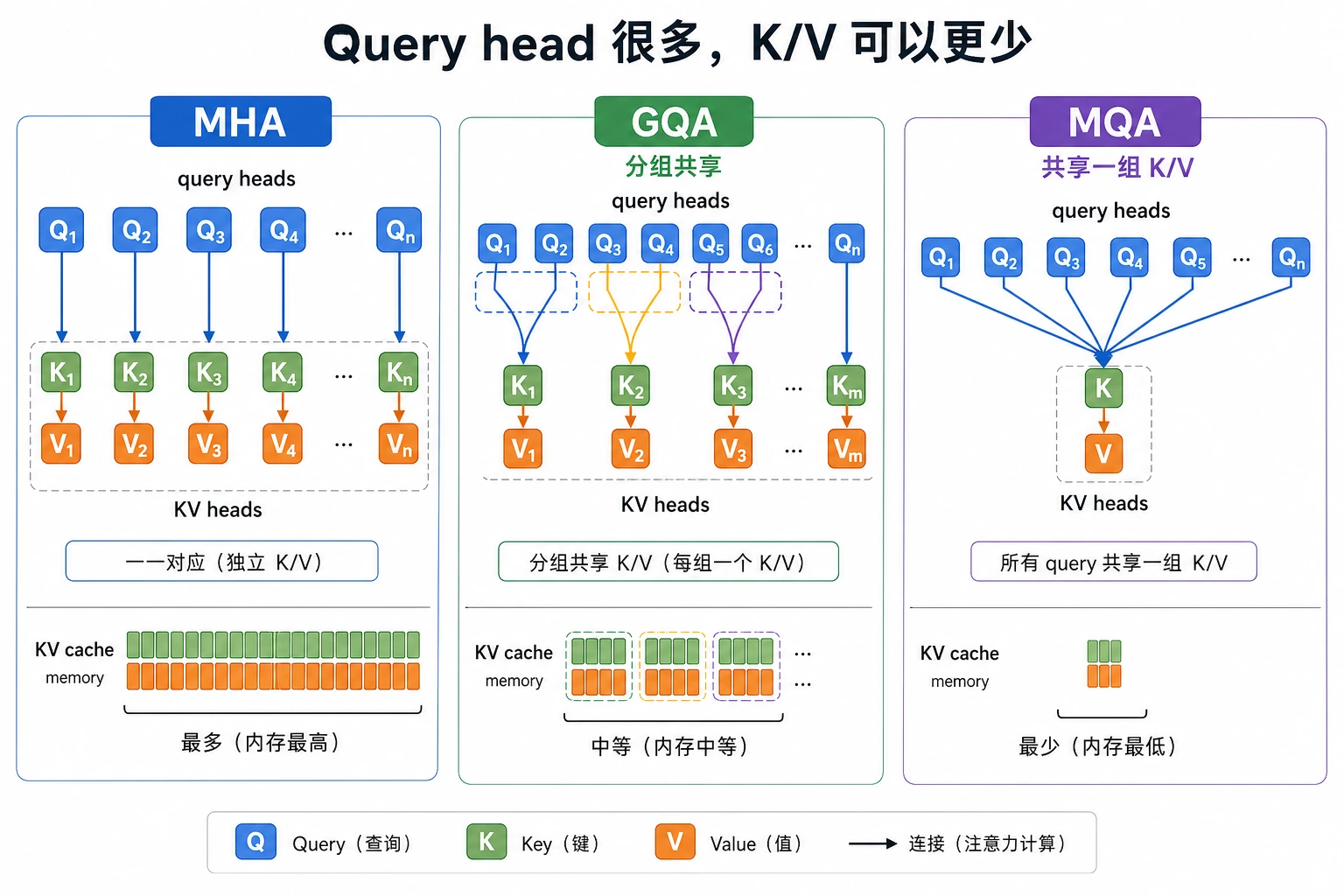
这张图建议从推理角度看:普通 MHA 每个 query head 往往各有 K/V,GQA 让一组 query heads 共享 K/V,MQA 则让更多 heads 共享同一组 K/V。共享越多,KV cache 越小,但也要接受一定表达能力取舍。
五、FlashAttention 为什么这么常被提?
因为很多瓶颈不在“算不出来”,而在“搬数据太贵”
注意力实现里,一个常见问题是:
- 中间矩阵太大
- GPU 显存读写频繁
FlashAttention 的关键思路是:
- 把计算分块
- 尽量减少中间结果落回高开销内存
所以它常常能带来:
- 更高吞吐
- 更低显存占用
它和滑动窗口不是同一类东西
这一点非常重要。
- 滑动窗口是在改“看谁”
- FlashAttention 是在改“怎么算”
所以它们甚至可以组合使用, 并不是互斥关系。
六、什么时候该优先想哪条路线?
如果你主要卡在长上下文训练显存
优先会想到:
- FlashAttention
- activation checkpointing
- 序列并行
如果你主要卡在推理时 KV cache 太大
优先会想到:
- MQA
- GQA
- KV cache 量化
如果你主要卡在超长上下文的平方复杂度
优先会想到:
- 滑动窗口
- 稀疏注意力
- 分块或混合注意力
- 线性注意力类方法
也就是说:
高效注意力不是一把锤子,而是一组针对不同瓶颈的工具。
七、常见误区
误区一:高效注意力 = 更快而且一定更好
很多方法本质上是在交换:
- 速度
- 内存
- 感受野
- 实现复杂度
不可能所有指标都白赚。
误区二:只要支持长上下文,模型就一定“会用长上下文”
支持 128k 上下文,不等于模型真的能稳定利用 128k 里的关键信息。
这是两件不同的事:
- 工程支持长度
- 模型有效利用长度
误区三:FlashAttention 是一种新模型架构
不是。 它更像一种高效实现技术。
小结
这节最重要的不是记住一串方法名, 而是先分清问题:
你到底是在被平方复杂度卡住、被 KV cache 卡住,还是被显存读写效率卡住。
只有先把瓶颈分清楚,你才知道该看:
- 滑动窗口
- GQA / MQA
- FlashAttention
中的哪一类方案。
练习
- 把示例中的
window=2改成window=1或window=3,观察 pair 数量怎么变化。 - 用自己的话解释:为什么说滑动窗口是在改“看谁”,FlashAttention 是在改“怎么算”?
- 如果你做的是长对话推理服务,为什么 GQA / MQA 往往比滑动窗口更先进入视野?
- 想一想:支持很长上下文,和真正能有效利用长上下文,为什么不是一回事?