11.3.1 文本分类路线图:文本输入、标签输出
文本分类接收一段文本,预测一个标签,例如情感、主题、意图或风险类型。
先看分类流水线
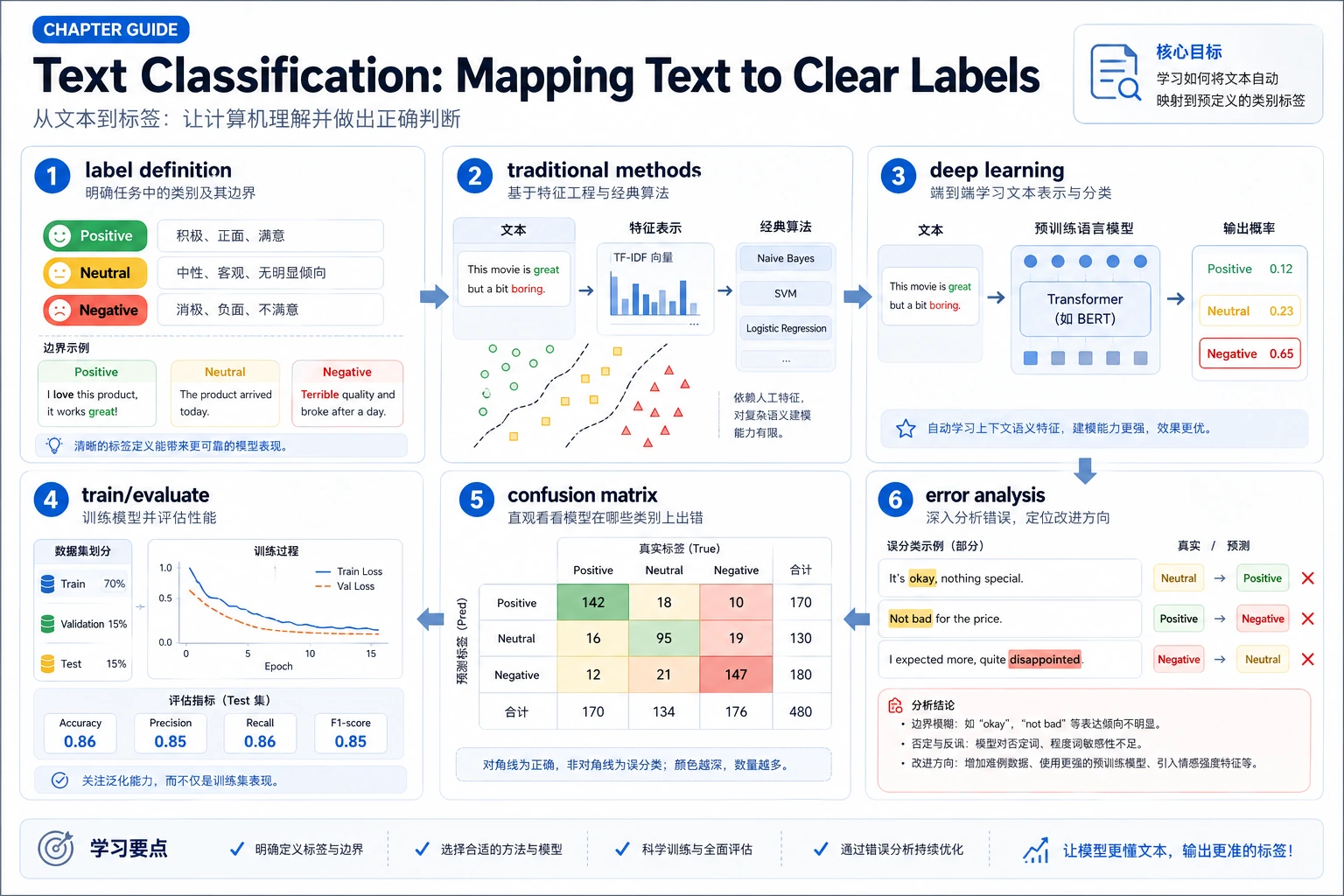
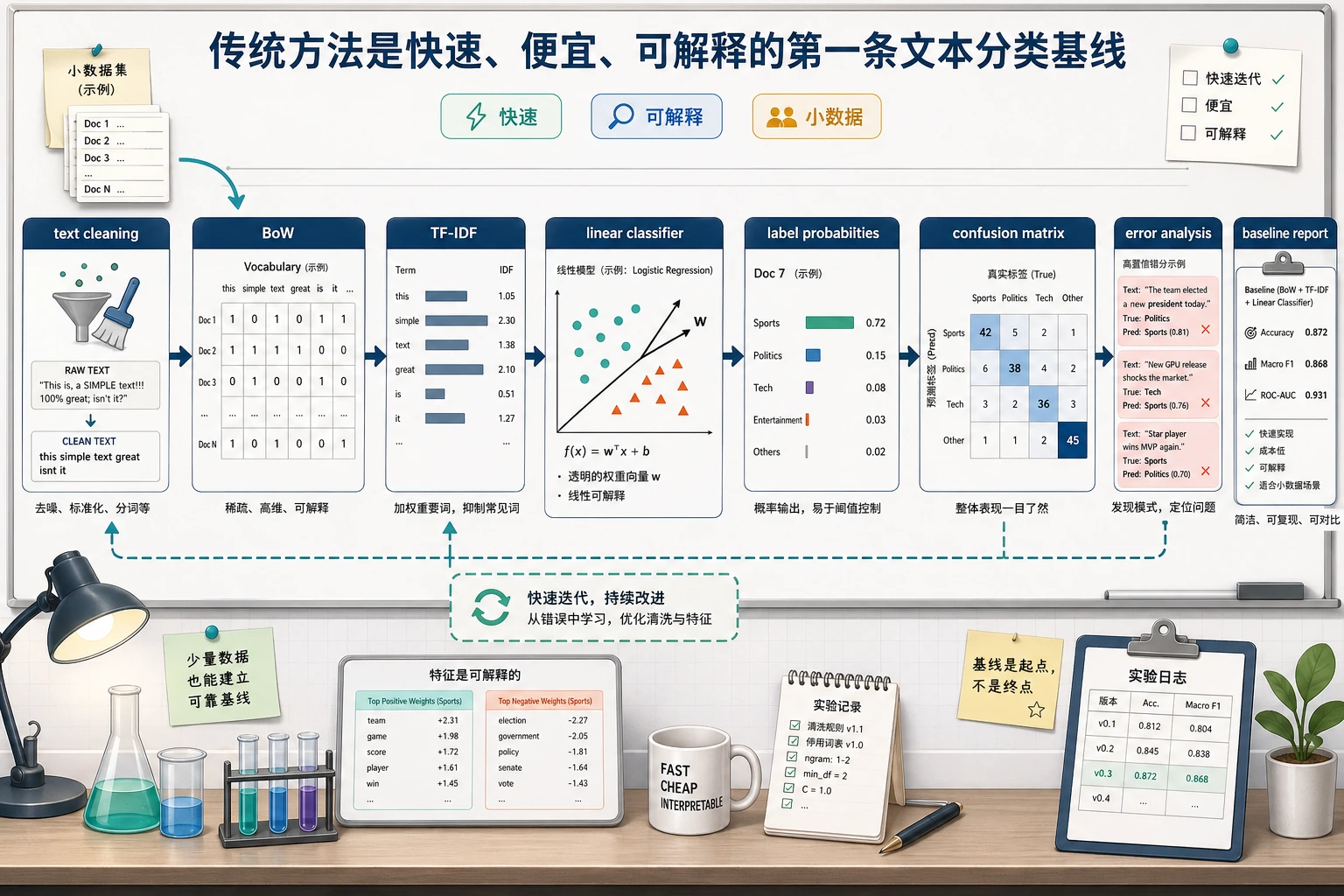
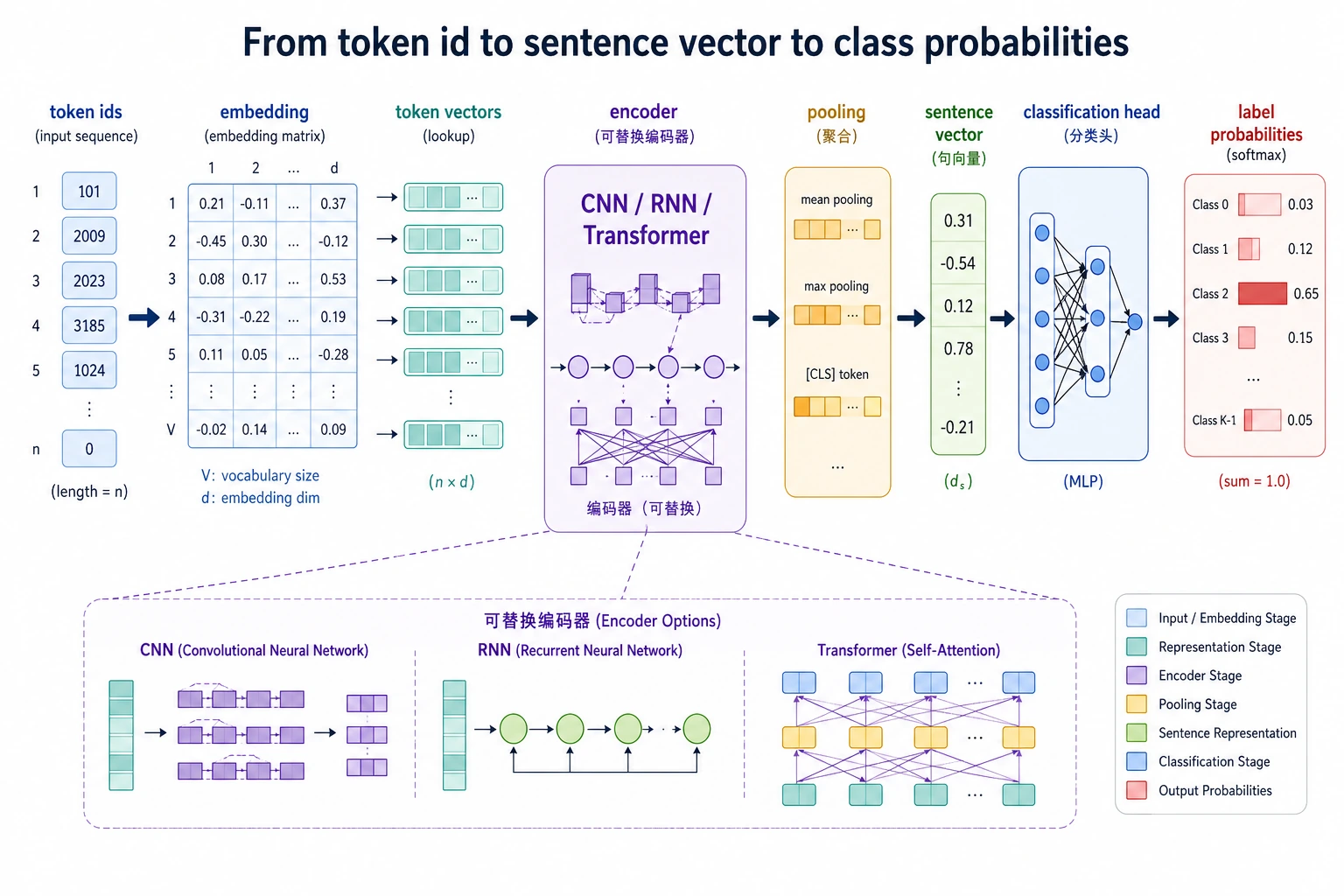
复杂模型之前先做 baseline。大多数分类问题不是模型不够强,而是标签模糊或样本分布偏。
跑一个关键词 Baseline
texts = ["great course and clear examples", "confusing setup error"]
positive_words = {"great", "clear", "good", "useful"}
for text in texts:
score = sum(word in positive_words for word in text.split())
label = "positive" if score > 0 else "needs_review"
print(label, "-", text)
预期输出:
positive - great course and clear examples
needs_review - confusing setup error
简单 baseline 不是最终模型,但能快速暴露标签规则和失败案例。
按这个顺序学
| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | 传统方法 | 构建 TF-IDF 或关键词 baseline |
| 2 | 深度学习方法 | 比较 embeddings、pooling、CNN/RNN/Transformer 特征 |
| 3 | 项目实战 | 追踪划分、指标、标签歧义和错误样例 |
通过标准
如果你能训练或模拟一个分类器,报告 accuracy/F1,并解释至少一个标签模糊案例,就通过了本章。