11.3.1 Text Classification Roadmap: Text In, Label Out
Text classification takes one piece of text and predicts one label, such as sentiment, topic, intent, or risk type.
See the Classification Pipeline First
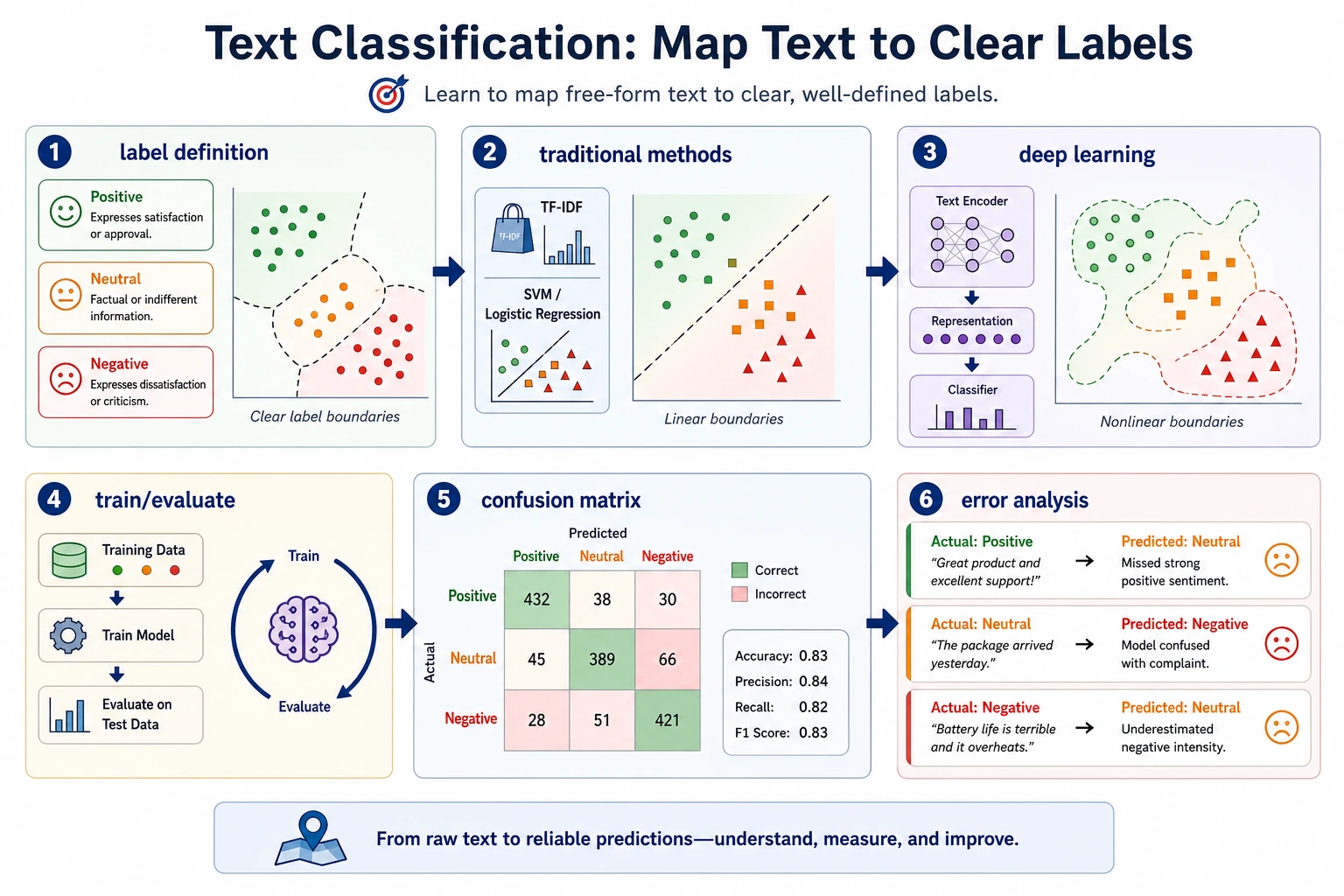

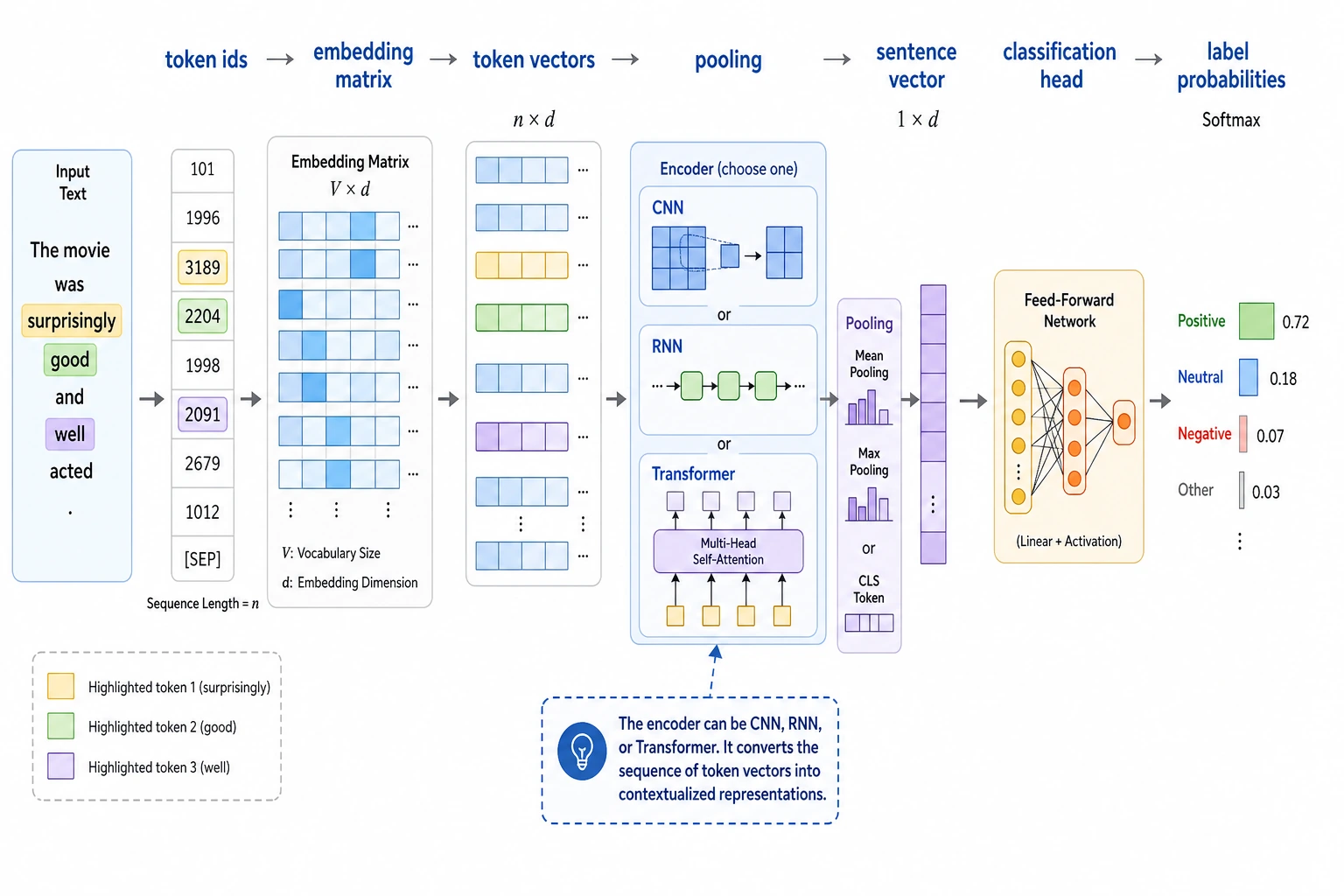
Always build a baseline before a complex model. Most classification problems fail because labels are vague or examples are skewed.
Run a Keyword Baseline
texts = ["great course and clear examples", "confusing setup error"]
positive_words = {"great", "clear", "good", "useful"}
for text in texts:
score = sum(word in positive_words for word in text.split())
label = "positive" if score > 0 else "needs_review"
print(label, "-", text)
Expected output:
positive - great course and clear examples
needs_review - confusing setup error
Simple baselines are not the final model, but they expose label rules and failure cases quickly.
Learn in This Order
| Step | Read | Practice Output |
|---|---|---|
| 1 | Traditional methods | Build TF-IDF or keyword baseline |
| 2 | Deep learning methods | Compare embeddings, pooling, CNN/RNN/Transformer features |
| 3 | Project practice | Track split, metrics, label ambiguity, and error samples |
Pass Check
You pass this chapter when you can train or simulate a classifier, report accuracy/F1, and explain at least one ambiguous label case.