11.7.2 项目:智能问答系统
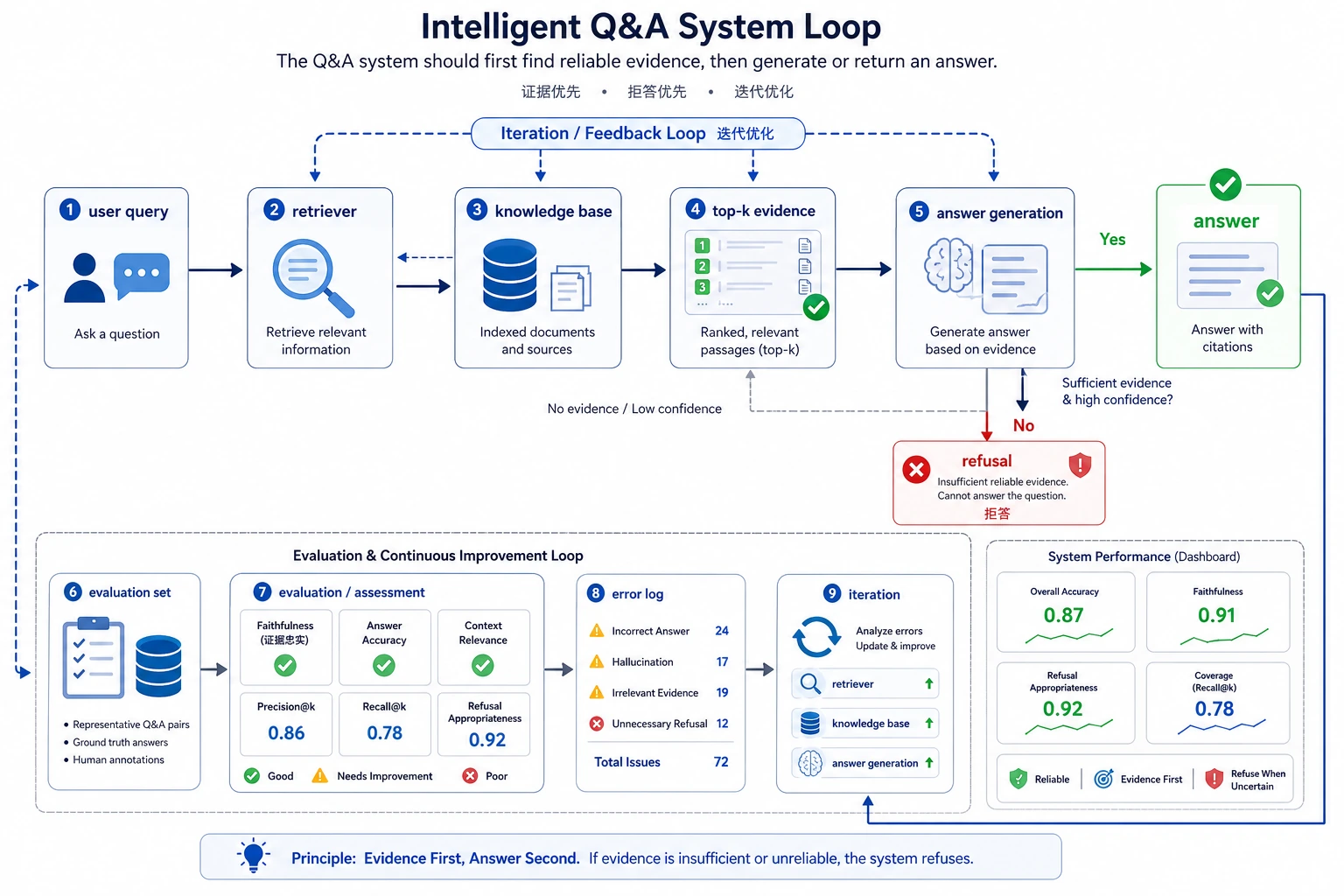
问答系统不是“生成一句像答案的话”就结束。读图时重点看 query、retrieval、evidence、answer、refusal、evaluation 和 error log 如何闭环,这也是后面 RAG 项目的核心骨架。
问答系统很适合作为 NLP 作品集项目,因为它天然能展示:
- 文本表示
- 相似度
- 检索
- 拒答策略
但要让它像“项目”,而不只是“能回答几句”的 demo,关键在于:
知识边界、检索质量、拒答机制和评估方式都要讲清楚。
学习目标
- 学会定义一个可解释的小型问答系统范围
- 学会设计知识库、检索器和拒答策略
- 学会用最小评估集做系统验证
- 学会把问答系统包装成作品集页面
一、项目题目怎么收窄?
一个很稳的起点是:
做一个课程平台 FAQ 检索式问答系统。
它适合的原因是:
- 题目范围清楚
- 知识库容易准备
- 错误原因容易分析
二、作品级问答项目最小闭环
- 定义知识范围
- 准备知识库
- 做检索基线
- 增加拒答
- 做评估集
- 展示错误分析
只要这 6 步清楚,项目就已经很有说服力。
一张更像真实系统的闭环图
这张图很重要,因为问答系统真正交付的不是:
- 一个看起来聪明的回复
而是:
- 一个知识边界清楚、错了也知道怎么复盘的系统
三、推荐推进顺序
对新人来说,更稳的顺序通常是:
- 先把知识范围收窄
- 再做最简单检索 baseline
- 再补拒答机制
- 最后再做评估和展示
这样项目会更像“可解释系统”,而不是“碰巧答对几句”的 demo。
为什么问答系统特别适合训练“系统边界感”?
因为它会逼你一直面对三个问题:
- 这个系统到底知道什么
- 它不知道什么
- 它什么时候应该停住不答
这正是很多真实产品系统最关键的一层判断。
一个更适合新人的总类比
你可以把问答系统想成:
- 图书馆前台答疑
前台不是无所不知, 而是:
- 先在馆内资料里找
- 找到再回答
- 找不到就明确说没有
这个类比很重要,因为它会帮助新人早点建立一个正确直觉:
- 问答系统首先是知识边界系统
- 不是“任何问题都尽量说点什么”的聊天系统
四、先做一个更完整的最小系统
import re
knowledge_base = [
{"question": "课程多久内可以退款?", "answer": "课程购买后 7 天内且学习进度低于 20% 可申请退款。"},
{"question": "证书怎么获得?", "answer": "完成所有必修项目并通过结课测试后,可以获得结业证书。"},
{"question": "学习顺序是什么?", "answer": "建议先学 Python、数据分析、机器学习,再进入深度学习和大模型阶段。"},
{"question": "前四阶段需要 GPU 吗?", "answer": "前四阶段不需要 GPU,普通电脑即可完成学习。"},
]
STOP_TOKENS = set("的了是吗么??和个更哪可可以怎么什么") | {"gpu", "python"}
def tokenize(text):
return {
token
for token in re.findall(r"[a-z0-9]+|[\u4e00-\u9fff]", text.lower())
if token not in STOP_TOKENS
}
def answer_question(user_query):
query_tokens = tokenize(user_query)
scored = []
for item in knowledge_base:
score = len(query_tokens & tokenize(item["question"]))
scored.append((score, item))
scored.sort(key=lambda x: x[0], reverse=True)
best_score, best_item = scored[0]
return {
"matched_question": best_item["question"],
"answer": best_item["answer"],
"score": best_score,
}
print(answer_question("退款时间是多久"))
print(answer_question("怎么拿证书"))
预期输出:
{'matched_question': '课程多久内可以退款?', 'answer': '课程购买后 7 天内且学习进度低于 20% 可申请退款。', 'score': 4}
{'matched_question': '证书怎么获得?', 'answer': '完成所有必修项目并通过结课测试后,可以获得结业证书。', 'score': 2}
这里的分数表示共享的有效 token 数。它仍然很简单,但比直接按字符粗暴匹配更稳,因为越界问题可以得到 0 分。
这个例子为什么更像项目,而不只是一个函数?
因为它已经有:
- 知识库
- 匹配逻辑
- 匹配得分
- 可解释的返回结果
为什么 matched_question 很值得展示?
因为它能帮你回答:
- 系统是答对了
- 还是只是碰巧答得像
为什么“检索命中什么”比“回答看起来顺不顺”更值得先看?
因为问答系统很多错误并不是生成层的错误, 而是:
- 一开始就命中了不对的知识
如果这一步没看清, 后面你会很难判断问题到底出在哪。
再看一个最小“命中日志”示例
把下面代码接在上一段后面,再运行同一个文件。
queries = ["退款时间是多久", "怎么拿证书"]
for query in queries:
result = answer_question(query)
print(
{
"query": query,
"matched_question": result["matched_question"],
"score": result["score"],
}
)
预期输出:
{'query': '退款时间是多久', 'matched_question': '课程多久内可以退款?', 'score': 4}
{'query': '怎么拿证书', 'matched_question': '证书怎么获得?', 'score': 2}
如果命中的问题错了,不要先调回答文案。先检查检索、分词或知识库边界。
这个日志很像真实项目里最值得先看的东西之一:
- 用户问了什么
- 系统命中了哪条知识
- 命中分数大概是多少
很多问题在这一步就已经能定位出来。
五、拒答机制为什么是作品级问答系统的关键?
没有拒答时,系统很容易:
- 任何问题都硬答
这在真实项目里很危险。
def safe_answer_question(user_query, threshold=1):
result = answer_question(user_query)
if result["score"] < threshold:
return {
"answer": "当前知识库中没有足够相关的信息。",
"matched_question": None,
"score": result["score"],
}
return result
print(safe_answer_question("DeepSeek 和 OpenAI 哪个更强?"))
预期输出:
{'answer': '当前知识库中没有足够相关的信息。', 'matched_question': None, 'score': 0}
这才是我们想要的行为:系统没有找到可支撑答案的知识,所以拒答,而不是猜。
为什么这一步特别值钱?
因为它会让系统从:
- 总想说点什么
变成:
- 知道什么时候该停
这在作品集里很加分。
六、一个最小评估集怎么设计?
eval_data = [
("退款时间是多久", "课程购买后 7 天内且学习进度低于 20% 可申请退款。"),
("证书怎么拿", "完成所有必修项目并通过结课测试后,可以获得结业证书。"),
("前四阶段需要显卡吗", "前四阶段不需要 GPU,普通电脑即可完成学习。"),
]
correct = 0
for q, gold in eval_data:
pred = safe_answer_question(q, threshold=1)["answer"]
if pred == gold:
correct += 1
accuracy = correct / len(eval_data)
print("accuracy =", accuracy)
预期输出:
accuracy = 1.0
这个评估集很小,不能代表真实产品质量,但它证明了闭环:正常问题能答对,轻微改写仍能命中正确条目,拒答可以单独测试。
还应该评估什么?
除了准确率,还值得看:
- 拒答是否合理
- 哪些问题最容易误匹配
- 近义表达是否稳定
一个很适合新人的最小评估表
你可以先只做这样一张表:
| query | matched_question | answer | should_answer | actually_answered | correct |
|---|
这张表已经足够帮你判断:
- 命中对不对
- 拒答稳不稳
- 最后答案靠不靠谱
第一次做问答项目时,最稳的默认顺序
更稳的顺序通常是:
- 先把知识库写小写清楚
- 先做最简单的检索 baseline
- 先加一层拒答
- 再补评估表和错例分析
这样会比一上来就追生成质量更容易做出一个可信系统。
七、最值得展示的失败案例
例如:
- 问题说法变化后匹配错
- 知识库没有覆盖
- 不该回答时却给出错误答案
把这些列出来,会比只展示正确样例更像项目课。
如果继续把项目往上做,最值得补什么?
更值得优先补的通常是:
- 近义表达鲁棒性测试
- 更稳的拒答策略
- 命中结果和最终回答的并排展示
这样项目会更像真正可解释的问答系统,而不是一组 FAQ 文本拼接。
项目交付时最好补上的内容
- 一张知识边界说明表
- 一张检索命中 / 拒答效果示例
- 一组典型错例
- 一段你对下一步升级路线的说明
如果把它做成作品集,最值得展示什么
最值得展示的通常不是:
- “系统答对了哪几句”
而是:
- 知识边界
- 检索命中日志
- 拒答案例
- 错例分析
- 下一步如何升级
这样别人会更容易感觉到:
- 你做的是一个系统
- 不是只拼了几条 FAQ
小结
这节最重要的是建立一个作品级判断:
问答系统的价值,不只是“能答对几题”,而是你能否把知识边界、检索逻辑、拒答策略和错误分析讲成一个完整闭环。
只要这条闭环立住,这个项目就会非常适合做作品集。
这节最该带走什么
- 问答系统首先是“知识边界系统”,其次才是“回答系统”
- 检索命中、拒答和错误分析是项目最值得展示的三块
- 如果能把“为什么答、为什么不答、为什么答错”讲清楚,这个项目就会非常像作品级项目
版本路线建议
| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。
练习
- 给知识库再加 5 条课程 FAQ,看看匹配效果如何变化。
- 为什么拒答机制会显著提升项目可信度?
- 想一想:如果两个问题很相近但答案不同,系统最容易出什么错?
- 如果做作品集展示,你最想给面试官看哪 3 块内容?