E.B.3 并发编程(含 asyncio)
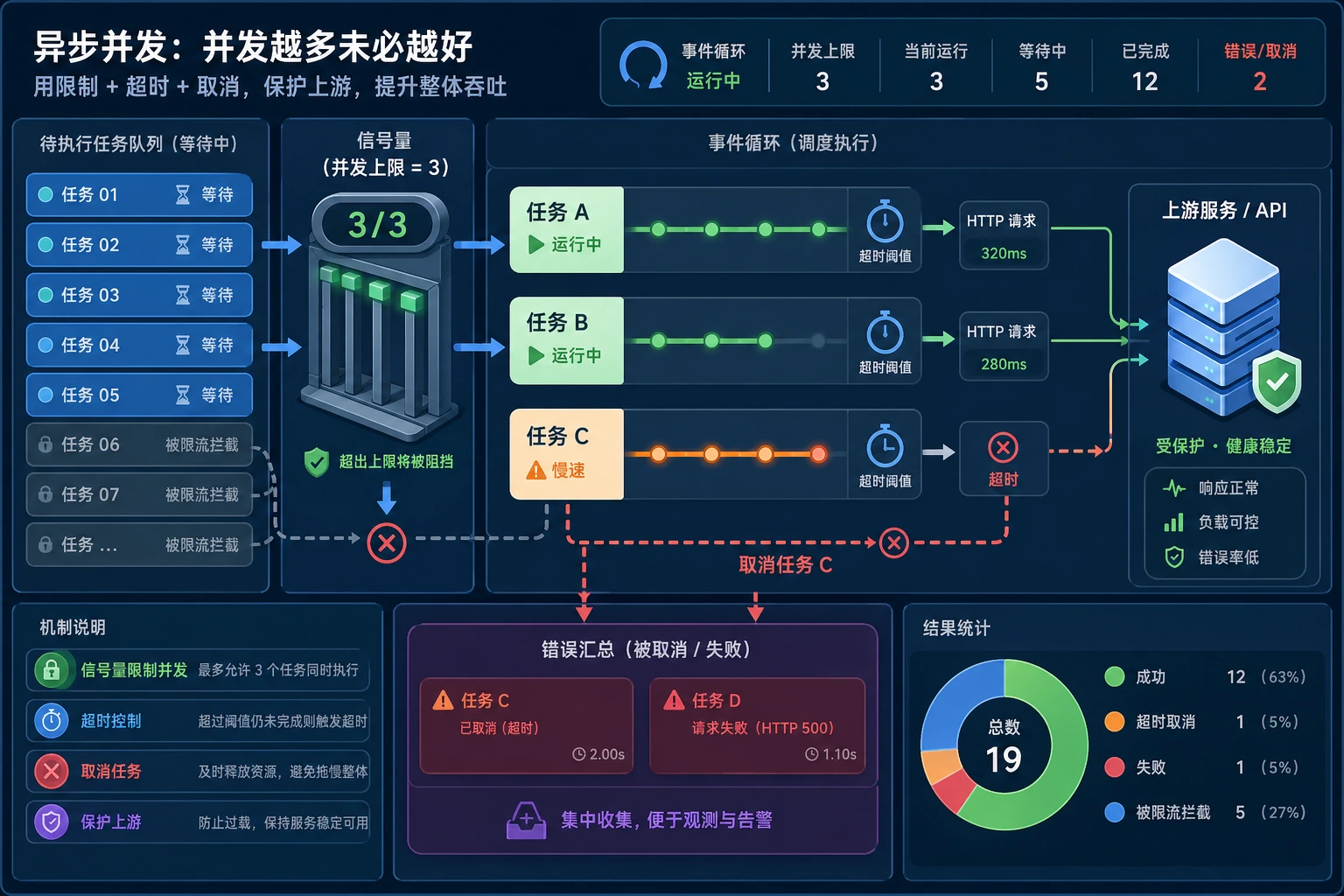
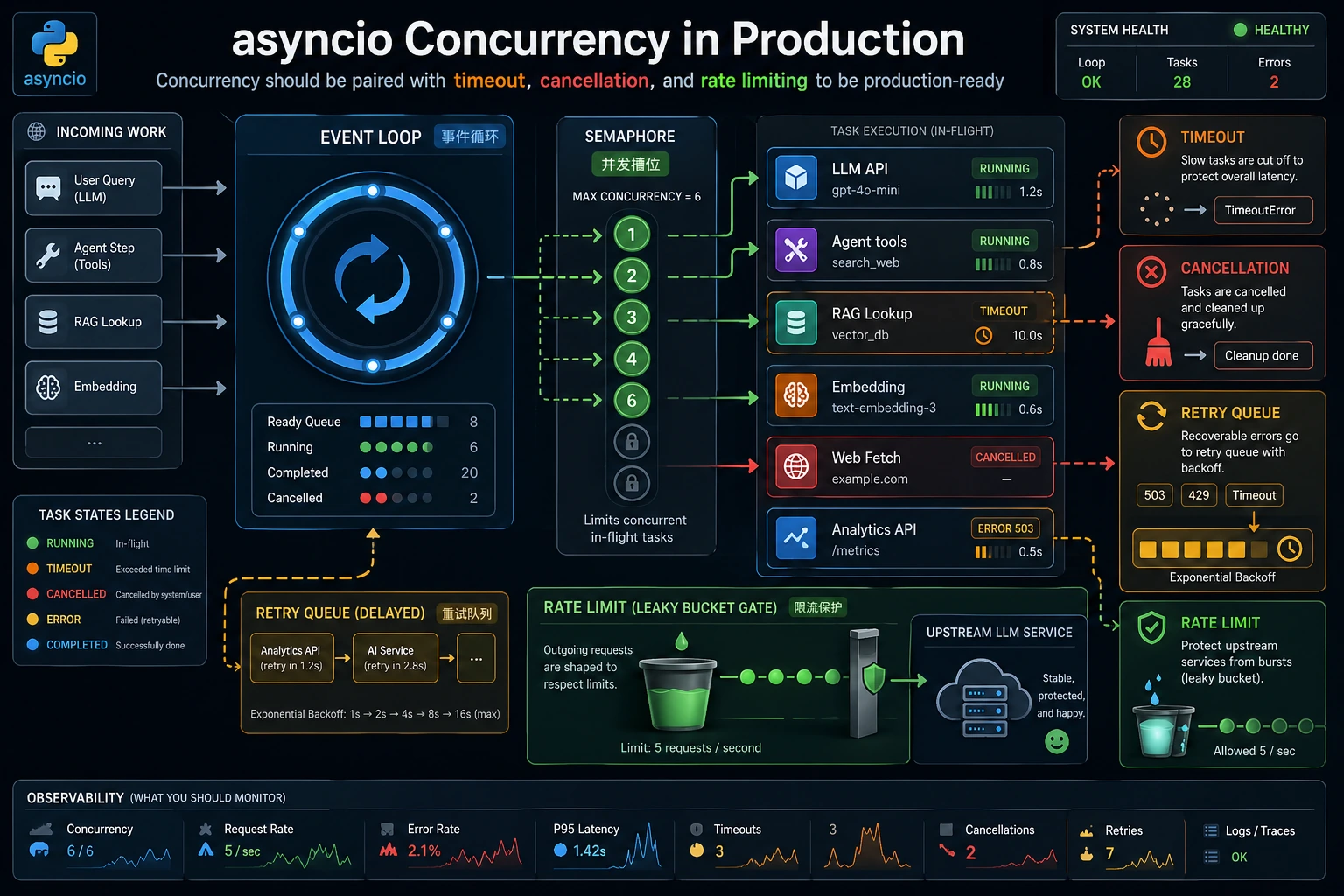
并发适合程序大部分时间都在“等”的场景:HTTP 调用、数据库调用、文件 I/O、爬取、RAG 检索或 Agent 工具调用。它不是 CPU 重任务的万能加速按钮。
准备内容
- Python 3.10+
- 不需要第三方包
- 能运行
python的终端
关键术语
- I/O-bound(I/O 密集):大部分时间在等待外部系统。
- CPU-bound(CPU 密集):大部分时间在做计算。
- Coroutine(协程):可以用
await暂停的异步函数。 asyncio.gather:同时运行多个 awaitable 并收集结果。- Semaphore(信号量):限制同时运行的任务数量。
- Timeout(超时):超过固定时间就停止等待。
运行受控异步批处理
创建 async_batch.py:
import asyncio
async def call_tool(name, delay):
await asyncio.sleep(delay)
return f"{name}:ok"
async def guarded_call(semaphore, name, delay, timeout):
async with semaphore:
try:
return await asyncio.wait_for(call_tool(name, delay), timeout=timeout)
except asyncio.TimeoutError:
return f"{name}:timeout"
async def main():
semaphore = asyncio.Semaphore(2)
results = await asyncio.gather(
guarded_call(semaphore, "search", 0.1, 0.5),
guarded_call(semaphore, "database", 0.2, 0.5),
guarded_call(semaphore, "slow_tool", 1.0, 0.3),
)
print(results)
asyncio.run(main())
运行:
python async_batch.py
预期输出:
['search:ok', 'database:ok', 'slow_tool:timeout']
重点不只是 gather,而是 gather 加并发上限,再加超时处理。
改变并发上限
运行这个小检查,看看两种并发上限:
import asyncio
for limit in [2, 1]:
semaphore = asyncio.Semaphore(limit)
print("limit:", limit, "semaphore:", type(semaphore).__name__)
预期输出:
limit: 2 semaphore: Semaphore
limit: 1 semaphore: Semaphore
最终结果不变,但任务会更保守地执行。真实服务中,这可以保护上游 API 不被突发请求压垮。
什么时候用 asyncio
适合:
- 很多网络请求
- 多个工具调用
- 从多个来源做 RAG 检索
- 等待数据库或队列
不优先:
- 大量数值计算
- 大图像变换
- 没有明显等待瓶颈、且必须保持简单的代码
常见错误
- 没判断任务是否 I/O 密集,就到处加
async。 - 用
gather却没有并发上限。 - 忘记超时,导致一个慢上游卡住整个流程。
- 吞掉异常,却没有记录哪个任务失败。
练习
再加 5 个工具调用,并设置 Semaphore(3)。然后把超时降到 0.15,统计有多少返回 :timeout。