7.0 Learning Checklist: LLM Principles, Prompt, and Fine-tuning
Use this page as a printable checklist. If you need the full explanation, return to the Chapter 7 entry page.
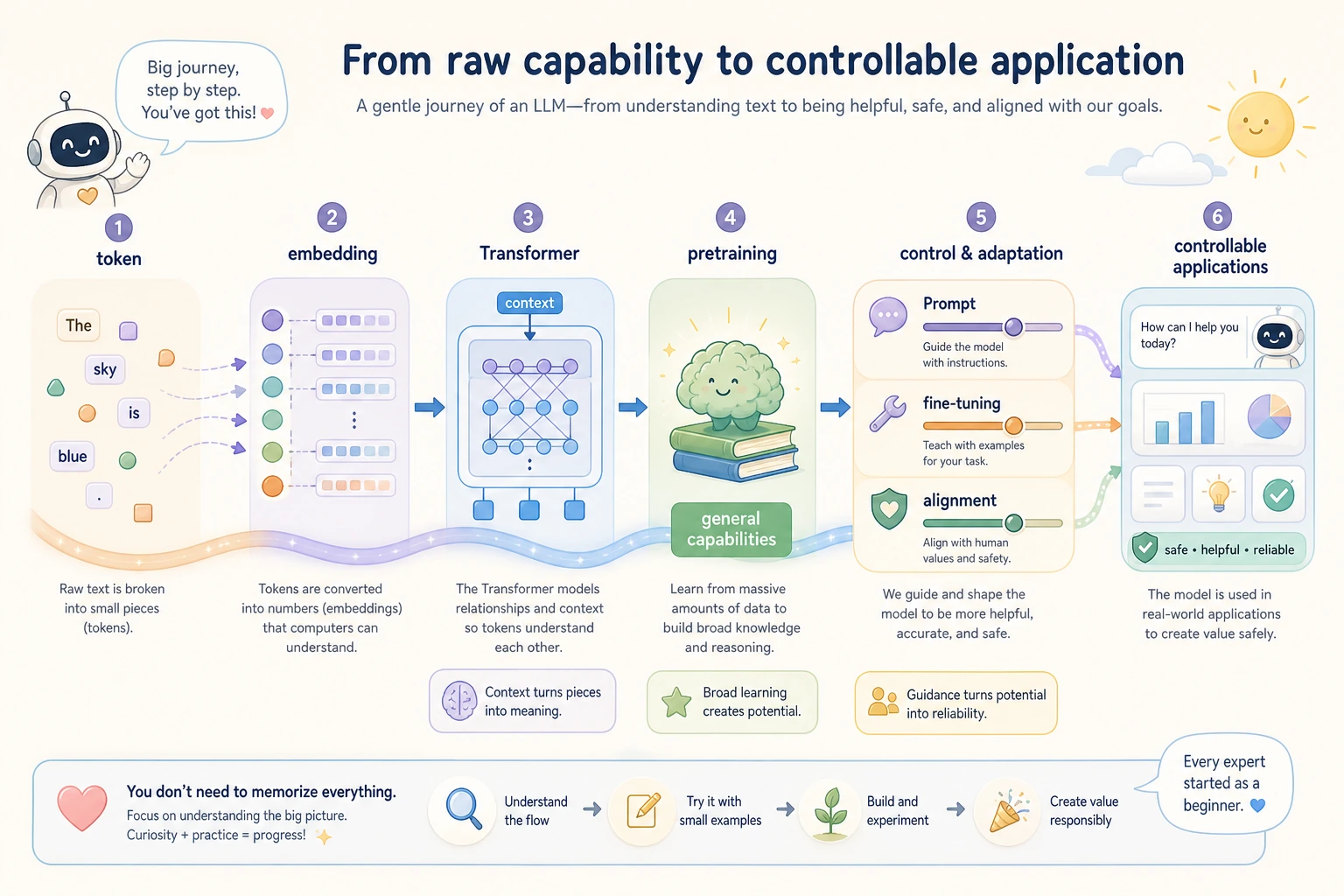
Two-Hour First Pass
| Time box | Do this | Stop when you can say |
|---|---|---|
| 20 min | Read the token-to-answer picture on the entry page | "Text becomes tokens, vectors, context, then next-token prediction." |
| 25 min | Skim 7.1 and run one tokenizer example | "Token count affects cost and context limits." |
| 25 min | Skim 7.2 and the LLM history page | "Scale, data, Transformer, and alignment changed what models can do." |
| 30 min | Run the prompt testing script from the entry page | "I can compare prompt versions with fixed cases." |
| 20 min | Read the solution-choice table | "I should not fine-tune before checking Prompt, RAG, tools, and validation." |
Required Evidence
| Evidence | Minimum version |
|---|---|
prompts/ | Three prompt versions for one task |
prompt_eval_cases.csv | At least five fixed inputs and a simple score column |
structured_output_schema.json | Required fields and allowed value types |
failure_cases.md | At least three failed outputs and the likely cause |
llm_stage_workshop_output.txt | Output from 7.8.4 Hands-on: Full Chapter 7 Workshop |
README.md | How to run, what passed, what failed, what to try next |
Quality Gates
| Gate | Pass condition |
|---|---|
| Prompt comparison | Same cases, one changed variable, saved outputs and scores. |
| Structured output | Parser rejects missing fields or wrong types. |
| Failure analysis | Each failure has a likely cause: instruction, input, schema, missing knowledge, or safety. |
| Method choice | Decision table explains why Prompt, RAG, fine-tuning, tools, or Agent comes first. |
Exit Questions
- Can you explain token, embedding, attention, context window, pretraining, Prompt, fine-tuning, and alignment without copying definitions?
- Can you change one prompt variable at a time and compare results with the same input cases?
- Can you validate JSON output instead of trusting text that only looks like JSON?
- Can you explain when missing information calls for RAG instead of a longer Prompt?
- Can you explain when repeated behavior adaptation might justify fine-tuning?
If the answer is yes, move to Chapter 8. Chapter 8 will connect these ideas to real LLM applications and RAG systems.