6.8.3 项目:文本情感分析
本节定位
情感分析是很适合入门的 NLP 项目,因为难点都看得见:标签边界、tokenization、否定词、讽刺、混合情绪和错误分析。
学习目标
- 先定义情感标签,再选择模型。
- 构建可解释的关键词 baseline。
- 用简单否定词规则修复一个已知错误类型。
- 把错误预测整理成 error buckets。
- 把一个小 NLP 项目包装成可复现交付物。
先看项目闭环
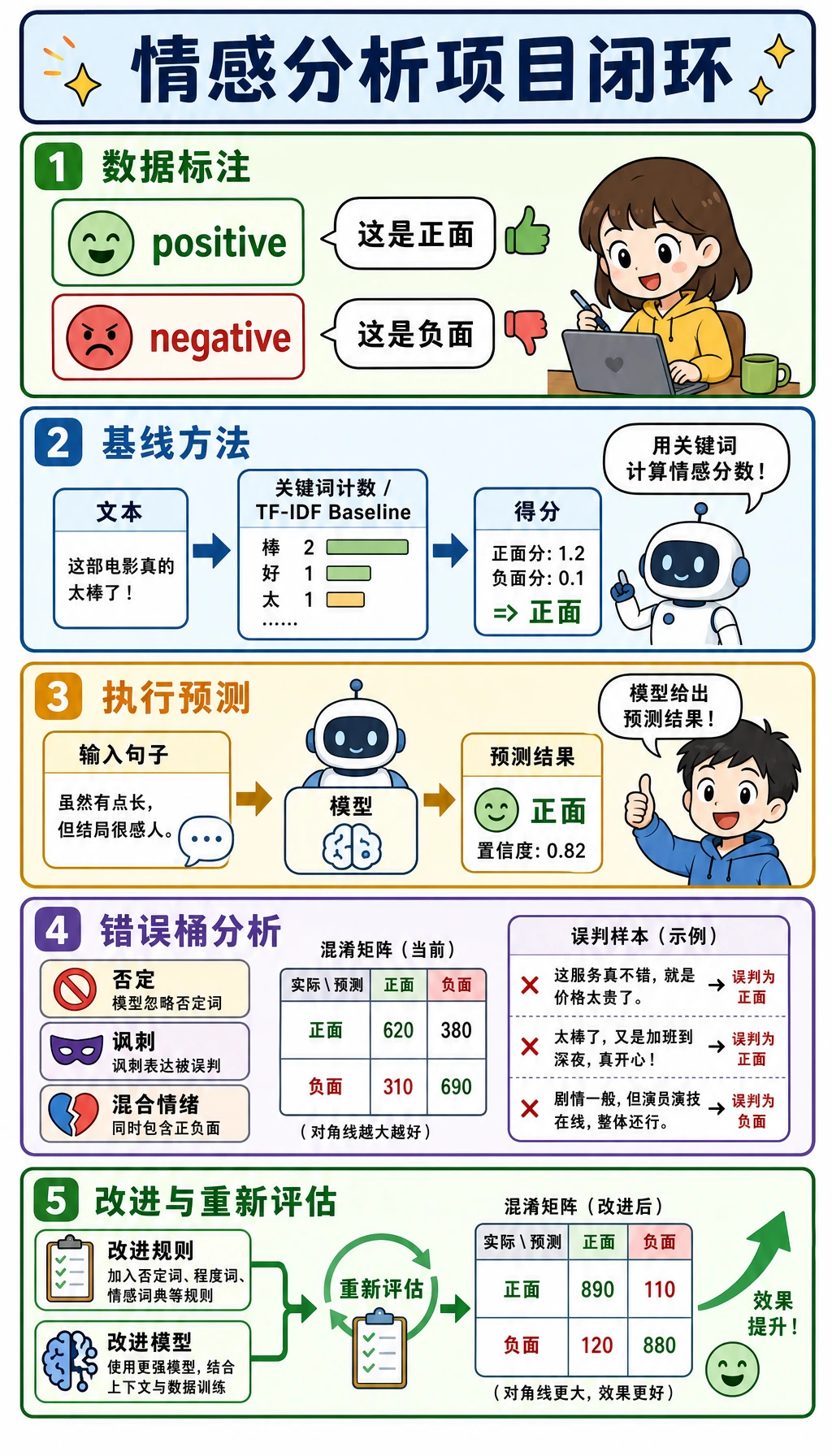
label boundary -> baseline -> predictions -> error buckets -> targeted upgrade
先从二分类开始:
positive:明确推荐、赞扬或表达满意。negative:明确抱怨、拒绝或表达不满。
不要一开始就加太多标签,比如 neutral、mixed、irony、unclear。等基础闭环稳定后再扩展。
实验:关键词 Baseline 与否定词修复
创建 sentiment_project_baseline.py:
from collections import Counter
def tokenize(text):
text = text.lower()
for ch in ",.!?":
text = text.replace(ch, "")
return text.split()
train = [
("clear examples and practical pace", "positive"),
("recommended and systematic course", "positive"),
("messy confusing and too fast", "negative"),
("unclear examples and weak structure", "negative"),
]
val = [
("clear and practical course", "positive"),
("messy and confusing pace", "negative"),
("not recommended", "negative"),
]
positive_words = Counter()
negative_words = Counter()
for text, label in train:
if label == "positive":
positive_words.update(tokenize(text))
else:
negative_words.update(tokenize(text))
positive_words.update(["recommended"] * 2)
negative_words.update(["messy"] * 2)
def predict(text):
score = sum(positive_words[t] - negative_words[t] for t in tokenize(text))
return ("positive" if score >= 0 else "negative"), score
def predict_with_negation(text):
score = 0
flip = False
for token in tokenize(text):
if token in {"not", "no", "never"}:
flip = True
continue
token_score = positive_words[token] - negative_words[token]
if flip and token_score != 0:
token_score *= -1
flip = False
score += token_score
return ("positive" if score >= 0 else "negative"), score
print("sentiment_baseline")
for text, gold in val:
pred, score = predict(text)
print({"gold": gold, "pred": pred, "score": score, "text": text})
print("with_negation")
for text, gold in val:
pred, score = predict_with_negation(text)
print({"gold": gold, "pred": pred, "score": score, "text": text})
运行:
python sentiment_project_baseline.py
预期输出:
sentiment_baseline
{'gold': 'positive', 'pred': 'positive', 'score': 3, 'text': 'clear and practical course'}
{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'messy and confusing pace'}
{'gold': 'negative', 'pred': 'positive', 'score': 3, 'text': 'not recommended'}
with_negation
{'gold': 'positive', 'pred': 'positive', 'score': 3, 'text': 'clear and practical course'}
{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'messy and confusing pace'}
{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'not recommended'}
这段代码教你:
- baseline 可解释,因为每个 token 都会改变分数;
not recommended在否定词规则前会失败;- 针对性规则能修复一种错误,但不要假装它解决了全部语言理解问题。
错误分桶
错误样本要按类型整理,而不是藏起来。
error_buckets = {
"negation": [],
"sarcasm": [],
"mixed_sentiment": [],
"other": [],
}
examples = [
("Not recommended for this course", "negative", "positive"),
("Great, it got stuck again", "negative", "positive"),
("The content is great, but the pace is too fast", "negative", "positive"),
]
for text, gold, pred in examples:
lower = text.lower()
if "not" in lower:
error_buckets["negation"].append(text)
elif "great" in lower and "again" in lower:
error_buckets["sarcasm"].append(text)
elif "but" in lower:
error_buckets["mixed_sentiment"].append(text)
else:
error_buckets["other"].append(text)
for name, rows in error_buckets.items():
print(name, len(rows), rows)
这是项目证据。它说明模型失败在哪里,也说明你下一步想改什么。
升级路线
| 版本 | 增加什么 | 为什么 |
|---|---|---|
| rule baseline | keyword counts 和 negation rule | 可解释起点 |
| traditional ML | TF-IDF + LogisticRegression | 低成本强 baseline |
| neural baseline | embedding + pooling 或小 Transformer | 学习表示特征 |
| portfolio version | error buckets、comparison table、demo command | 展示工程判断 |
README 要展示什么
README 要具体:
- 标签定义;
- 数据来源和划分;
- 运行命令;
- baseline 对比表;
- error buckets;
- 模型做对和做错的例子;
- 下一步计划。
常见错误
| 错误 | 修复 |
|---|---|
| 标签含糊 | 训练前写清标签规则 |
| 只报告 accuracy | 加入 error buckets 和例子 |
| 忽略否定词 | 测试 not、never、no |
| 太早加深度模型 | 保留 rule 或 TF-IDF baseline |
| 隐藏讽刺/混合情绪错误 | 作为已知限制记录下来 |
练习
- 把
"not clear"和"never useful"加入验证样本。 - 增加一个规则无法分类的
otherbucket 示例。 - 在项目计划中用 TF-IDF 替换关键词计数。
- 为
neutral写一条标签规则,但暂时不要加入模型。 - 为这个项目写一个 README 大纲。
小结
- 情感分析项目的关键在标签边界和错误分析。
- 简单 baseline 很有用,因为它可解释。
- 否定词是经典的第一类错误。
- Error buckets 比单个 accuracy 分数更能体现项目价值。