6.8.3 プロジェクト:テキスト感情分析
この節の位置づけ
Sentiment analysis は、最初の NLP project として向いています。難しい部分が見えやすいからです。label boundaries、tokenization、negation、sarcasm、mixed sentiment、error analysis がすべて表に出ます。
学習目標
- model を選ぶ前に sentiment labels を定義できる。
- explainable な keyword baseline を作れる。
- simple negation rule で 1 つの既知 error type を改善できる。
- wrong predictions を error buckets に整理できる。
- 小さな NLP project を reproducible deliverable としてまとめられる。
まず Project Loop を見る
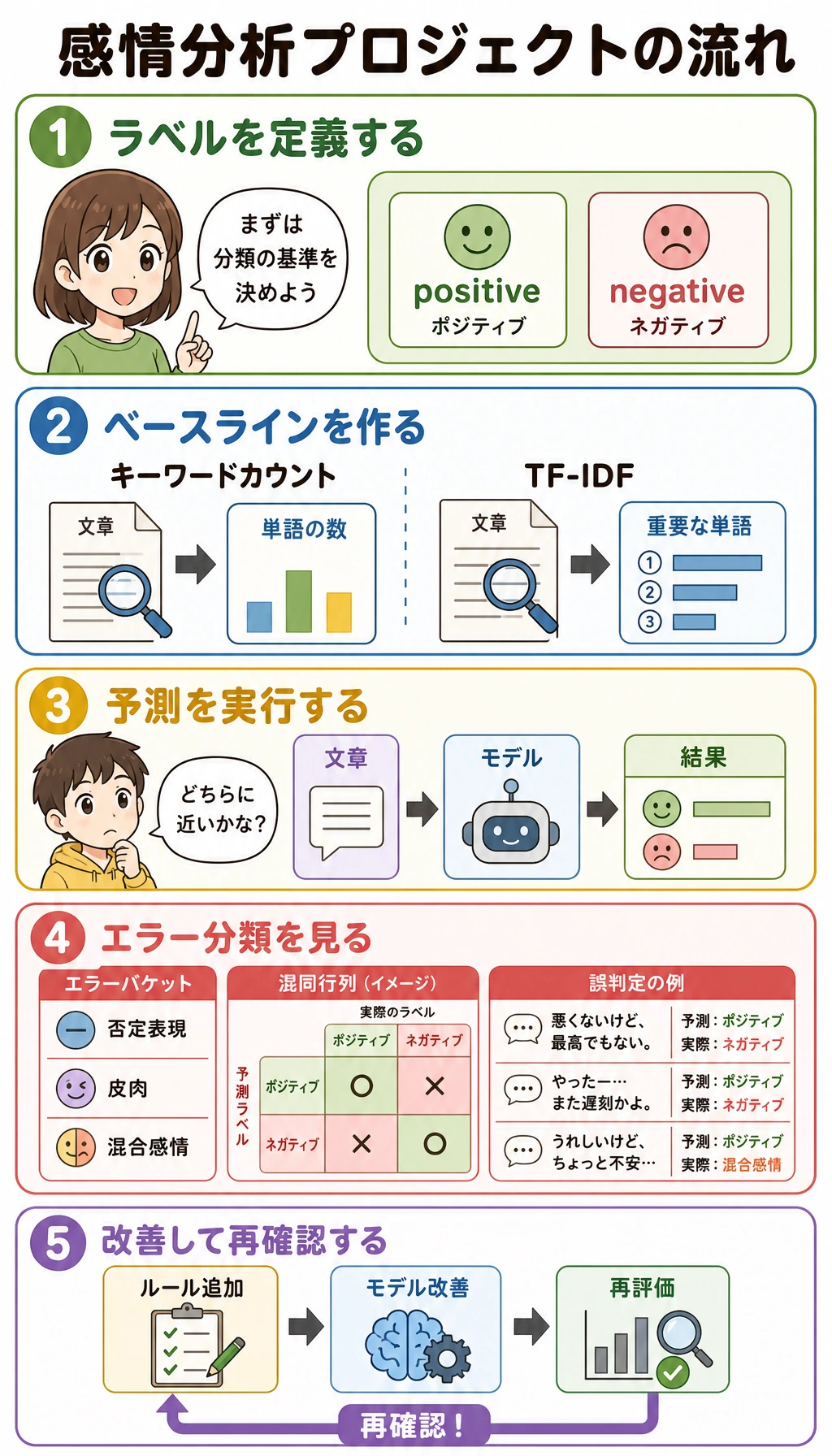
label boundary -> baseline -> predictions -> error buckets -> targeted upgrade
まずは binary labels から始めます。
positive:明確に推薦、称賛、満足を表す。negative:明確に不満、拒否、苦情を表す。
basic loop が安定する前に、neutral、mixed、irony、unclear などを増やしすぎないでください。
実験:Keyword Baseline と Negation Fix
sentiment_project_baseline.py を作成します。
from collections import Counter
def tokenize(text):
text = text.lower()
for ch in ",.!?":
text = text.replace(ch, "")
return text.split()
train = [
("clear examples and practical pace", "positive"),
("recommended and systematic course", "positive"),
("messy confusing and too fast", "negative"),
("unclear examples and weak structure", "negative"),
]
val = [
("clear and practical course", "positive"),
("messy and confusing pace", "negative"),
("not recommended", "negative"),
]
positive_words = Counter()
negative_words = Counter()
for text, label in train:
if label == "positive":
positive_words.update(tokenize(text))
else:
negative_words.update(tokenize(text))
positive_words.update(["recommended"] * 2)
negative_words.update(["messy"] * 2)
def predict(text):
score = sum(positive_words[t] - negative_words[t] for t in tokenize(text))
return ("positive" if score >= 0 else "negative"), score
def predict_with_negation(text):
score = 0
flip = False
for token in tokenize(text):
if token in {"not", "no", "never"}:
flip = True
continue
token_score = positive_words[token] - negative_words[token]
if flip and token_score != 0:
token_score *= -1
flip = False
score += token_score
return ("positive" if score >= 0 else "negative"), score
print("sentiment_baseline")
for text, gold in val:
pred, score = predict(text)
print({"gold": gold, "pred": pred, "score": score, "text": text})
print("with_negation")
for text, gold in val:
pred, score = predict_with_negation(text)
print({"gold": gold, "pred": pred, "score": score, "text": text})
実行します。
python sentiment_project_baseline.py
期待される出力:
sentiment_baseline
{'gold': 'positive', 'pred': 'positive', 'score': 3, 'text': 'clear and practical course'}
{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'messy and confusing pace'}
{'gold': 'negative', 'pred': 'positive', 'score': 3, 'text': 'not recommended'}
with_negation
{'gold': 'positive', 'pred': 'positive', 'score': 3, 'text': 'clear and practical course'}
{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'messy and confusing pace'}
{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'not recommended'}
この code で学ぶこと:
- baseline は、各 token が score を変えるので説明しやすい。
not recommendedは negation rule の前では失敗する。- targeted rule は 1 つの error type を直せるが、言語理解全体を解いたわけではない。
Error Buckets
wrong cases は隠さず、type ごとにまとめます。
error_buckets = {
"negation": [],
"sarcasm": [],
"mixed_sentiment": [],
"other": [],
}
examples = [
("Not recommended for this course", "negative", "positive"),
("Great, it got stuck again", "negative", "positive"),
("The content is great, but the pace is too fast", "negative", "positive"),
]
for text, gold, pred in examples:
lower = text.lower()
if "not" in lower:
error_buckets["negation"].append(text)
elif "great" in lower and "again" in lower:
error_buckets["sarcasm"].append(text)
elif "but" in lower:
error_buckets["mixed_sentiment"].append(text)
else:
error_buckets["other"].append(text)
for name, rows in error_buckets.items():
print(name, len(rows), rows)
これは project evidence です。model がどこで失敗し、次に何を改善すべきかを示します。
Upgrade Path
| Version | 追加するもの | 理由 |
|---|---|---|
| rule baseline | keyword counts と negation rule | explainable starting point |
| traditional ML | TF-IDF + LogisticRegression | 低コストで強い baseline |
| neural baseline | embedding + pooling または小さな Transformer | representation features を学ぶ |
| portfolio version | error buckets、comparison table、demo command | engineering judgment を示す |
README に見せるもの
README は具体的にします。
- label definitions。
- dataset source と split。
- run command。
- baseline comparison table。
- error buckets。
- model が正解した例と間違えた例。
- next-step plan。
よくある間違い
| 間違い | 直し方 |
|---|---|
| labels が曖昧 | training 前に label rules を書く |
| accuracy だけ報告する | error buckets と examples を含める |
| negation を無視する | not、never、no cases を test する |
| deep model を早く入れすぎる | rule または TF-IDF baseline を残す |
| sarcasm/mixed sentiment errors を隠す | known limitations として記録する |
練習
"not clear"と"never useful"を validation examples に追加してください。- rule では分類できない
otherbucket example を追加してください。 - project plan で keyword counts を TF-IDF に置き換えてください。
neutralの label rule を書いてください。ただし model にはまだ追加しないでください。- この project の README outline を作ってください。
まとめ
- Sentiment project は label boundaries と error analysis で決まります。
- Simple baseline は explainable なので有用です。
- Negation は古典的な最初の failure type です。
- Error buckets は単一の accuracy score より project value を見せられます。