7.1.6 实操:Tokenizer 与 Embedding 实验室
Tokenizer 和 embedding 分开看都不难,但很多新人卡在“它们到底怎么连起来”。
这一节给你一条最小链路:
原始文本 -> tokens -> input_ids -> attention_mask -> embedding -> 相似度分数

学习节奏
先看图,再跑代码,最后看打印输出。不要一开始就钻公式,先把数据流看明白。
这一节补什么
前面几页分别解释了 tokenizer 和 embedding,这一节把它们连起来。
你会看到:
- 文本怎样被切成 token
- token 怎样变成整数 ID
- padding 怎样产生
attention_mask - token ID 怎样从 embedding table 里查向量
- 句子向量怎样支持相似度比较
运行前先认识几个术语
| 术语 | 通俗解释 | 为什么重要 |
|---|---|---|
token | 切分后的文本单元 | 模型不会直接接收原始句子 |
input_ids | token 对应的整数编号 | 神经网络处理数字,不处理字符串 |
attention_mask | 真实 token 为 1,padding 为 0 | 告诉模型哪些位置要忽略 |
embedding | token 的向量表示 | 把符号 ID 变成连续语义特征 |
| cosine similarity | 衡量向量方向相似度的分数 | 常用于检索和语义匹配 |
跑实验
把下面代码保存为 tokenizer_embedding_lab.py,然后运行:
python tokenizer_embedding_lab.py
from math import sqrt
vocab = {
"[PAD]": 0,
"[UNK]": 1,
"[CLS]": 2,
"[SEP]": 3,
"reset": 4,
"password": 5,
"refund": 6,
"order": 7,
"please": 8,
"help": 9,
}
embedding_table = {
0: [0.00, 0.00, 0.00],
1: [0.10, 0.10, 0.10],
2: [0.20, 0.20, 0.20],
3: [0.20, 0.20, 0.20],
4: [0.12, 0.18, 0.92],
5: [0.10, 0.20, 0.95],
6: [0.90, 0.80, 0.10],
7: [0.75, 0.70, 0.15],
8: [0.40, 0.40, 0.40],
9: [0.42, 0.45, 0.38],
}
special_token_ids = {vocab["[PAD]"], vocab["[CLS]"], vocab["[SEP]"]}
def tokenize(text):
return text.lower().split()
def encode(text, max_length=6):
tokens = ["[CLS]"] + tokenize(text) + ["[SEP]"]
input_ids = [vocab.get(token, vocab["[UNK]"]) for token in tokens]
input_ids = input_ids[:max_length]
tokens = tokens[:max_length]
attention_mask = [1] * len(input_ids)
if len(input_ids) < max_length:
pad_count = max_length - len(input_ids)
input_ids += [vocab["[PAD]"]] * pad_count
tokens += ["[PAD]"] * pad_count
attention_mask += [0] * pad_count
return tokens, input_ids, attention_mask
def average_embedding(input_ids, attention_mask):
vectors = [
embedding_table[token_id]
for token_id, keep in zip(input_ids, attention_mask)
if keep == 1 and token_id not in special_token_ids
]
dim = len(vectors[0])
return [sum(vector[i] for vector in vectors) / len(vectors) for i in range(dim)]
def cosine(a, b):
dot = sum(x * y for x, y in zip(a, b))
norm_a = sqrt(sum(x * x for x in a))
norm_b = sqrt(sum(x * x for x in b))
return dot / (norm_a * norm_b)
texts = [
"please help reset password",
"reset password",
"refund order",
]
sentence_vectors = []
for text in texts:
tokens, input_ids, attention_mask = encode(text)
vector = average_embedding(input_ids, attention_mask)
sentence_vectors.append(vector)
print("-" * 60)
print("text :", text)
print("tokens :", tokens)
print("input_ids :", input_ids)
print("attention_mask:", attention_mask)
print("sentence_vec :", [round(x, 3) for x in vector])
print("-" * 60)
print("similarity(text 1, text 2):", round(cosine(sentence_vectors[0], sentence_vectors[1]), 3))
print("similarity(text 1, text 3):", round(cosine(sentence_vectors[0], sentence_vectors[2]), 3))
预期输出:
------------------------------------------------------------
text : please help reset password
tokens : ['[CLS]', 'please', 'help', 'reset', 'password', '[SEP]']
input_ids : [2, 8, 9, 4, 5, 3]
attention_mask: [1, 1, 1, 1, 1, 1]
sentence_vec : [0.26, 0.307, 0.662]
------------------------------------------------------------
text : reset password
tokens : ['[CLS]', 'reset', 'password', '[SEP]', '[PAD]', '[PAD]']
input_ids : [2, 4, 5, 3, 0, 0]
attention_mask: [1, 1, 1, 1, 0, 0]
sentence_vec : [0.11, 0.19, 0.935]
------------------------------------------------------------
text : refund order
tokens : ['[CLS]', 'refund', 'order', '[SEP]', '[PAD]', '[PAD]']
input_ids : [2, 6, 7, 3, 0, 0]
attention_mask: [1, 1, 1, 1, 0, 0]
sentence_vec : [0.825, 0.75, 0.125]
------------------------------------------------------------
similarity(text 1, text 2): 0.949
similarity(text 1, text 3): 0.607
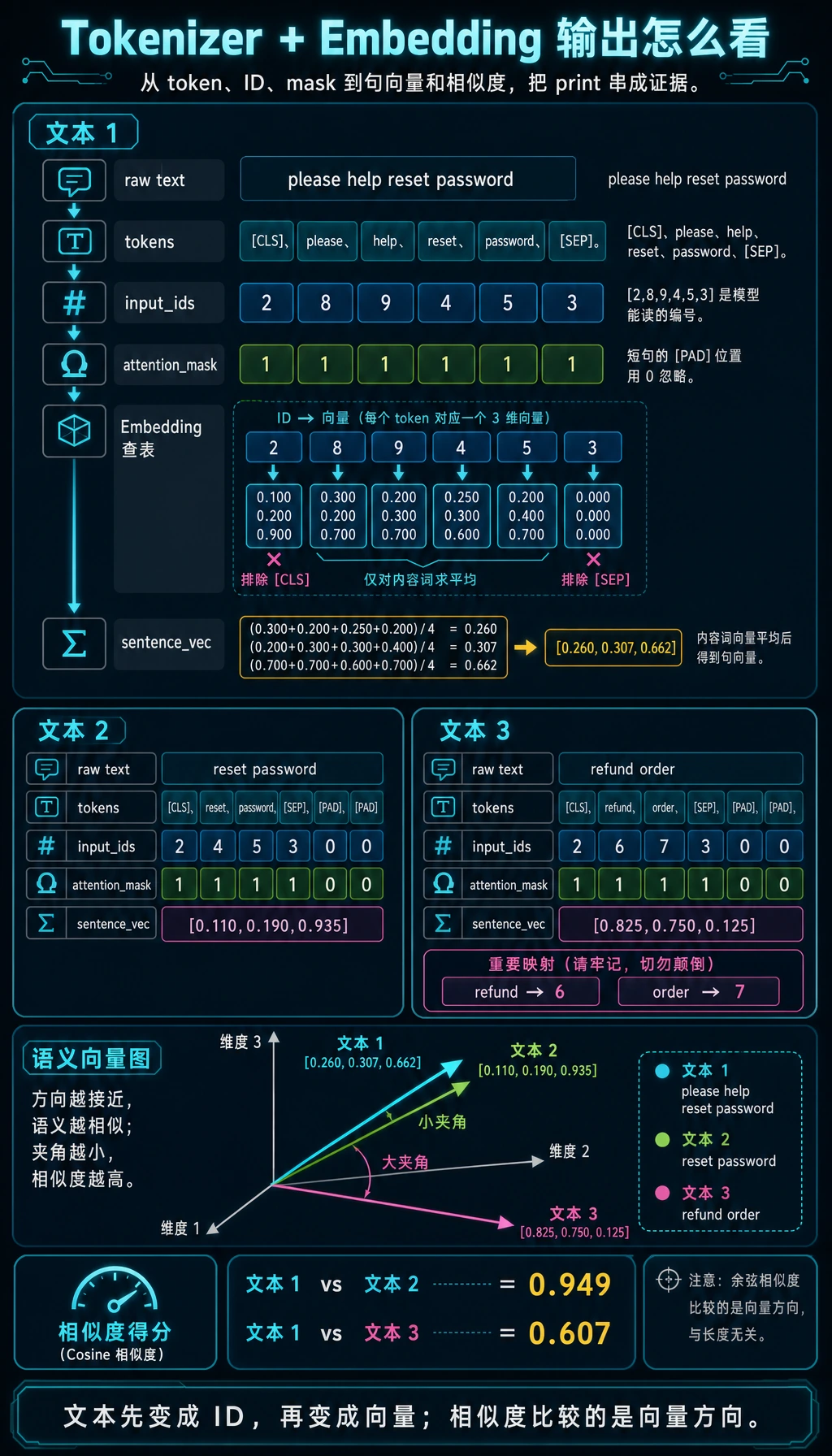
怎样读输出
tokens 仍然是人能看懂的
Tokenizer 先得到这样的列表:
["[CLS]", "please", "help", "reset", "password", "[SEP]"]
这一步人还能看懂。
input_ids 是模型能处理的
然后 token 变成数字:
[2, 8, 9, 4, 5, 3]
模型并不直接认识 password 这个词,它看到的是 ID 5,再用 ID 5 去查向量。
attention_mask 防止 padding 被当成意义
如果句子短于 max_length,代码会补 [PAD]。
mask 把 padding 标成 0,告诉模型这不是实际内容。
Embedding 是 ID 开始携带语义特征的地方
input_ids 本身只是编号。
embedding table 会把每个 ID 变成向量。
所以要分清:
- token ID 告诉模型“这是哪个符号”
- embedding vector 告诉模型“这个符号怎样被表示”
- 本实验在简单平均时排除了 special tokens,让句向量更集中在内容词上
为什么示例里的相似度有效
please help reset password 和 reset password 很接近,因为它们共享关键的密码重置向量。
please help reset password 和 refund order 更远,因为它们指向不同语义区域。
这就是语义搜索、检索和 RAG 的最小直觉。
练习任务
- 给
vocab和embedding_table增加新词invoice。 - 增加句子
refund invoice。 - 把它和
refund order做相似度比较。 - 把
max_length从6改成4,观察 truncation 截掉了什么。 - 加一个未知词,观察
[UNK]怎样影响向量。
总结
Tokenizer 和 embedding 是人类语言走向模型计算的前两座桥。
- tokenizer 把文本变成离散 ID
- embedding 把 ID 变成语义向量
- similarity 用来比较这些向量
这条链路看懂以后,Transformer 输入、embedding API、检索和 RAG 都会变得没那么神秘。