7.1.6 Hands-on: Tokenizer and Embedding Lab
Tokenizer and embedding are easy to understand separately, but many beginners get stuck when they have to connect them.
This lab gives you the whole mini-chain:
raw text -> tokens -> input_ids -> attention_mask -> embedding -> similarity score
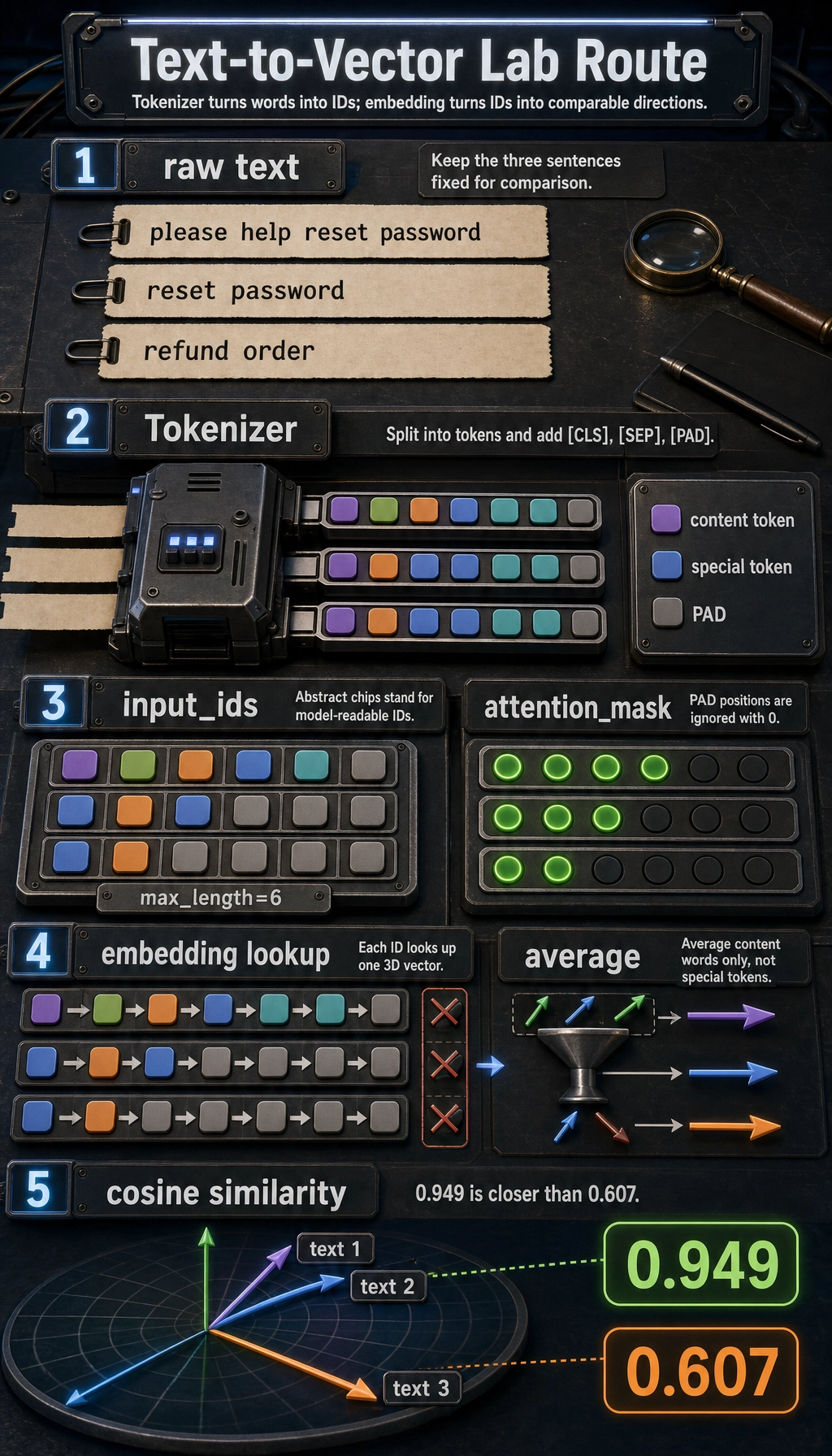
Read the picture first, then run the code, then inspect the printed output. Do not start from formulas. Start from the data flow.
What this lab adds
Earlier pages explained tokenizer and embedding separately. This lab shows how they work together.
You will see:
- how text is split into tokens
- how tokens become integer IDs
- how padding creates
attention_mask - how token IDs look up vectors from an embedding table
- how sentence vectors support similarity comparison
Terms to clarify before running
| Term | Plain meaning | Why it matters |
|---|---|---|
token | A text unit after splitting | The model never receives the raw sentence directly |
input_ids | Integer IDs for tokens | Neural networks process numbers, not text strings |
attention_mask | 1 for real tokens, 0 for padding | Tells the model which positions should be ignored |
embedding | A vector representation for a token | Turns symbolic IDs into continuous semantic features |
| cosine similarity | A score measuring vector direction similarity | Commonly used in retrieval and semantic matching |
Run the lab
Save the following code as tokenizer_embedding_lab.py, then run:
python tokenizer_embedding_lab.py
from math import sqrt
vocab = {
"[PAD]": 0,
"[UNK]": 1,
"[CLS]": 2,
"[SEP]": 3,
"reset": 4,
"password": 5,
"refund": 6,
"order": 7,
"please": 8,
"help": 9,
}
embedding_table = {
0: [0.00, 0.00, 0.00],
1: [0.10, 0.10, 0.10],
2: [0.20, 0.20, 0.20],
3: [0.20, 0.20, 0.20],
4: [0.12, 0.18, 0.92],
5: [0.10, 0.20, 0.95],
6: [0.90, 0.80, 0.10],
7: [0.75, 0.70, 0.15],
8: [0.40, 0.40, 0.40],
9: [0.42, 0.45, 0.38],
}
special_token_ids = {vocab["[PAD]"], vocab["[CLS]"], vocab["[SEP]"]}
def tokenize(text):
return text.lower().split()
def encode(text, max_length=6):
tokens = ["[CLS]"] + tokenize(text) + ["[SEP]"]
input_ids = [vocab.get(token, vocab["[UNK]"]) for token in tokens]
input_ids = input_ids[:max_length]
tokens = tokens[:max_length]
attention_mask = [1] * len(input_ids)
if len(input_ids) < max_length:
pad_count = max_length - len(input_ids)
input_ids += [vocab["[PAD]"]] * pad_count
tokens += ["[PAD]"] * pad_count
attention_mask += [0] * pad_count
return tokens, input_ids, attention_mask
def average_embedding(input_ids, attention_mask):
vectors = [
embedding_table[token_id]
for token_id, keep in zip(input_ids, attention_mask)
if keep == 1 and token_id not in special_token_ids
]
dim = len(vectors[0])
return [sum(vector[i] for vector in vectors) / len(vectors) for i in range(dim)]
def cosine(a, b):
dot = sum(x * y for x, y in zip(a, b))
norm_a = sqrt(sum(x * x for x in a))
norm_b = sqrt(sum(x * x for x in b))
return dot / (norm_a * norm_b)
texts = [
"please help reset password",
"reset password",
"refund order",
]
sentence_vectors = []
for text in texts:
tokens, input_ids, attention_mask = encode(text)
vector = average_embedding(input_ids, attention_mask)
sentence_vectors.append(vector)
print("-" * 60)
print("text :", text)
print("tokens :", tokens)
print("input_ids :", input_ids)
print("attention_mask:", attention_mask)
print("sentence_vec :", [round(x, 3) for x in vector])
print("-" * 60)
print("similarity(text 1, text 2):", round(cosine(sentence_vectors[0], sentence_vectors[1]), 3))
print("similarity(text 1, text 3):", round(cosine(sentence_vectors[0], sentence_vectors[2]), 3))
Expected output:
------------------------------------------------------------
text : please help reset password
tokens : ['[CLS]', 'please', 'help', 'reset', 'password', '[SEP]']
input_ids : [2, 8, 9, 4, 5, 3]
attention_mask: [1, 1, 1, 1, 1, 1]
sentence_vec : [0.26, 0.307, 0.662]
------------------------------------------------------------
text : reset password
tokens : ['[CLS]', 'reset', 'password', '[SEP]', '[PAD]', '[PAD]']
input_ids : [2, 4, 5, 3, 0, 0]
attention_mask: [1, 1, 1, 1, 0, 0]
sentence_vec : [0.11, 0.19, 0.935]
------------------------------------------------------------
text : refund order
tokens : ['[CLS]', 'refund', 'order', '[SEP]', '[PAD]', '[PAD]']
input_ids : [2, 6, 7, 3, 0, 0]
attention_mask: [1, 1, 1, 1, 0, 0]
sentence_vec : [0.825, 0.75, 0.125]
------------------------------------------------------------
similarity(text 1, text 2): 0.949
similarity(text 1, text 3): 0.607
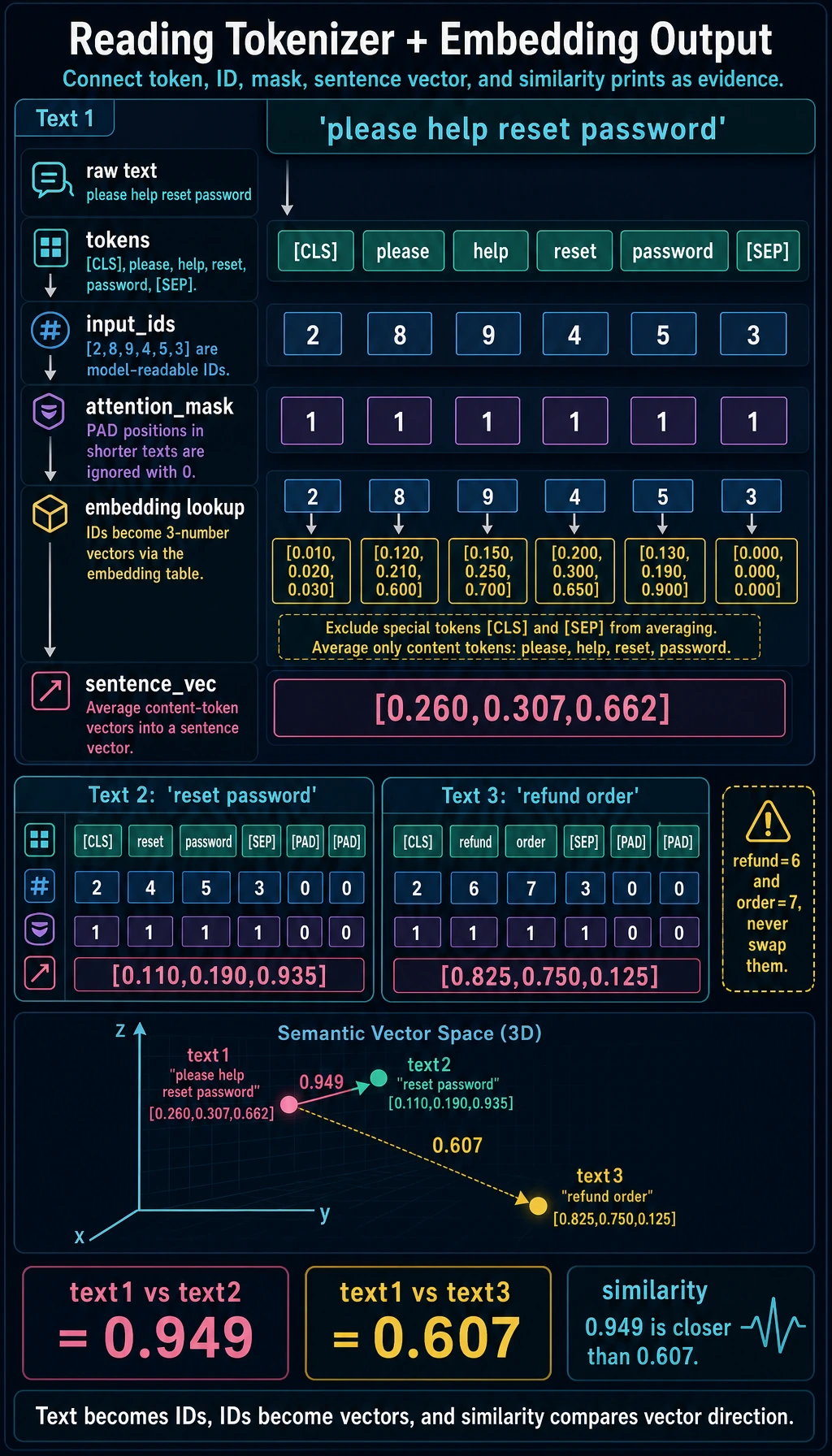
How to read the output
tokens are still human-readable
The tokenizer first creates a list such as:
["[CLS]", "please", "help", "reset", "password", "[SEP]"]
This is still readable by humans.
input_ids are model-readable
Then tokens become numbers:
[2, 8, 9, 4, 5, 3]
The model does not know the word password directly. It sees the ID 5, then looks up the vector for ID 5.
attention_mask prevents padding from becoming meaning
If a sentence is shorter than max_length, the code adds [PAD].
The mask marks padding as 0, so the model knows it is not real content.
Embedding is where IDs start to carry semantic features
input_ids alone are just identifiers.
The embedding table turns each ID into a vector.
That is why this distinction matters:
- token ID tells the model which symbol it is
- embedding vector tells the model how that symbol should be represented
- this lab excludes special tokens from the simple average so the sentence vector focuses on content words
Why similarity works in the example
please help reset password and reset password are close because they share the important password-reset vectors.
please help reset password and refund order are farther apart because they point to different semantic regions.
This is the smallest intuition behind semantic search, retrieval, and RAG.
Practice tasks
- Add a new word
invoicetovocabandembedding_table. - Add the sentence
refund invoice. - Compare it with
refund order. - Change
max_lengthfrom6to4and observe what truncation removes. - Add one unknown word and observe how
[UNK]changes the vector.
Summary
Tokenizer and embedding are the first two bridges from human language to model computation.
- tokenizer turns text into discrete IDs
- embedding turns IDs into semantic vectors
- similarity compares those vectors
Once this chain is clear, Transformer input, embedding APIs, retrieval, and RAG will all feel much less mysterious.