9.4.1 记忆路线图:写入、检索、遗忘
记忆不是为了让 Agent 看起来像人,而是为了服务任务:减少重复沟通、保留有用上下文、复用经验,并避免过期信息或隐私泄露。
先看记忆闭环
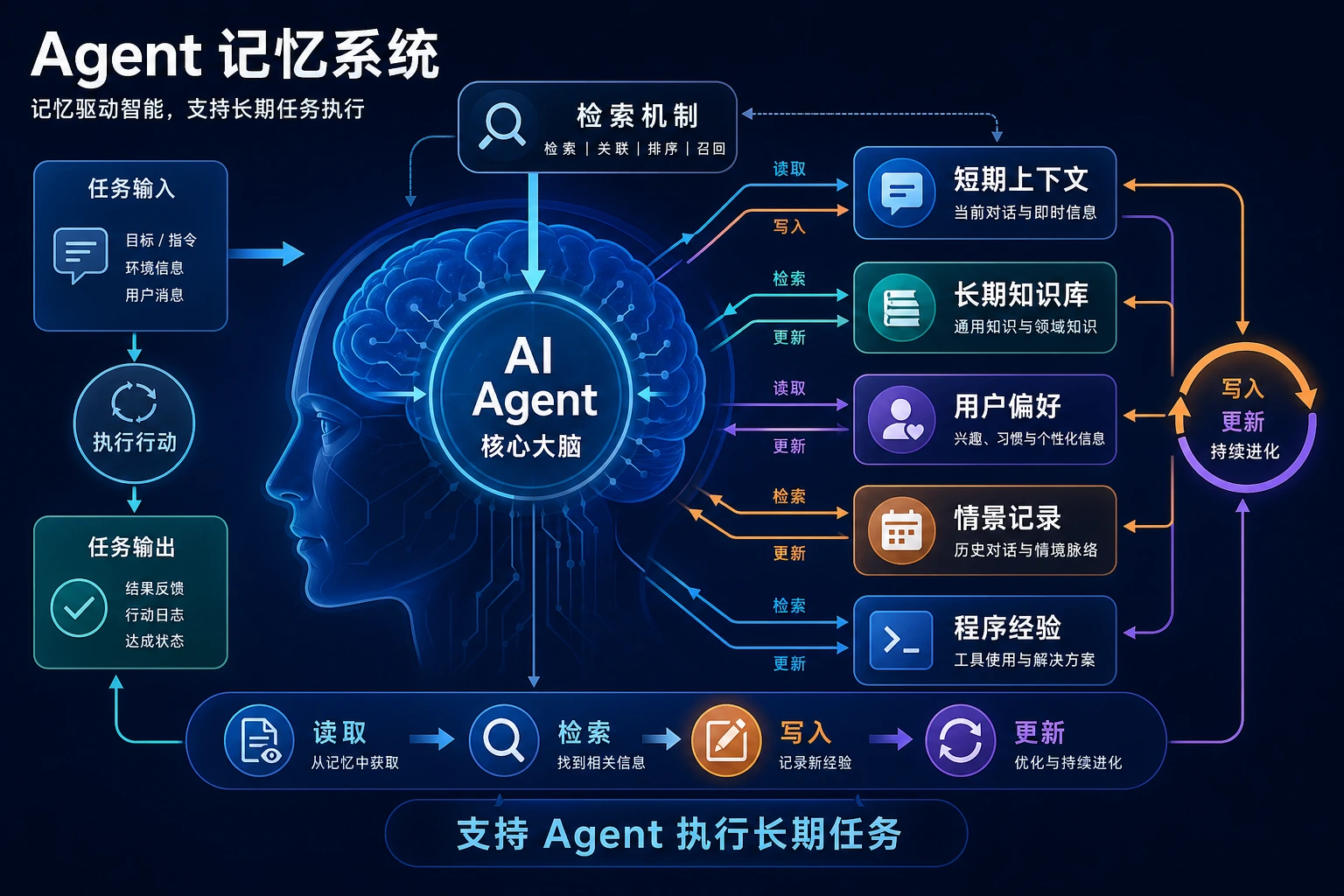
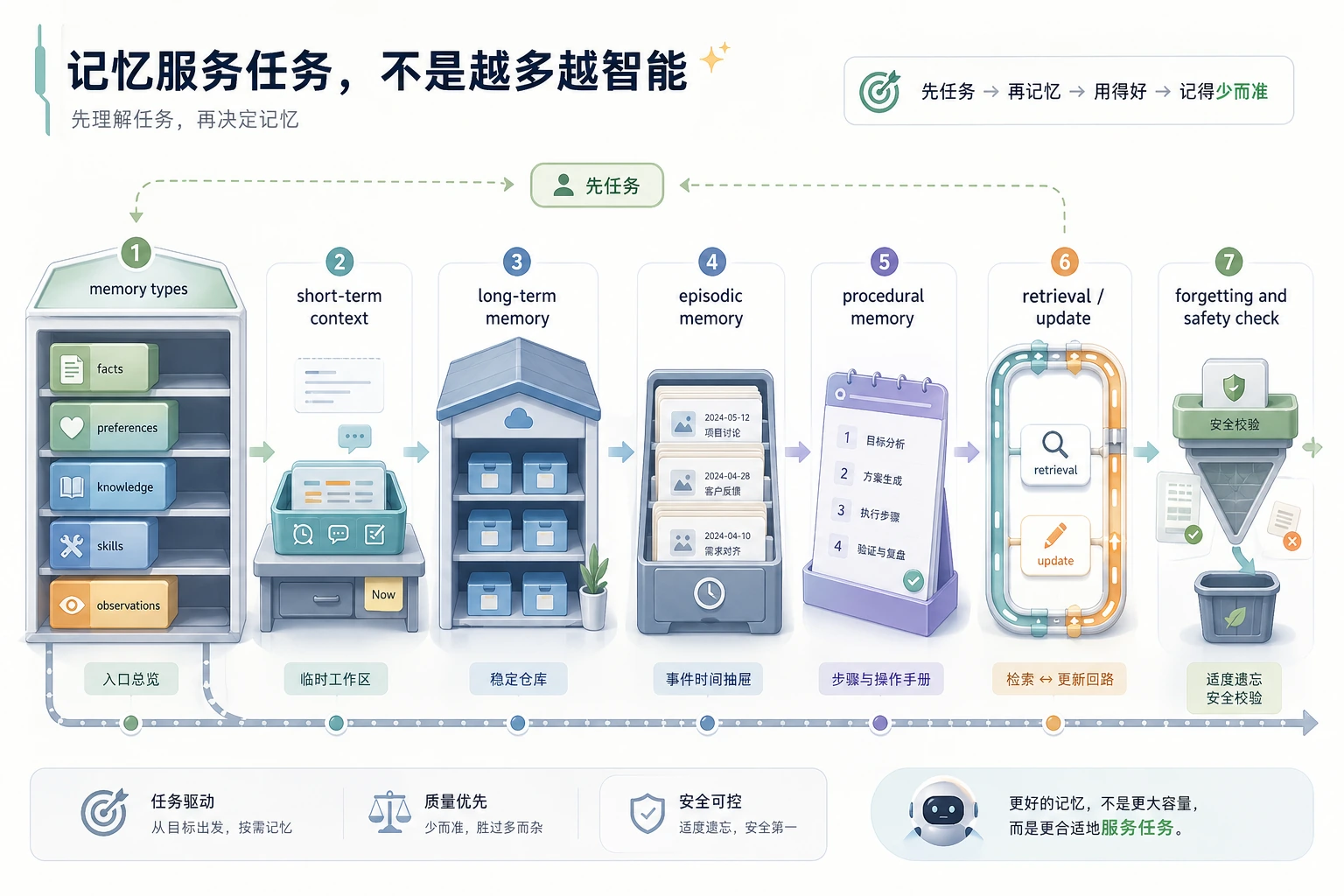
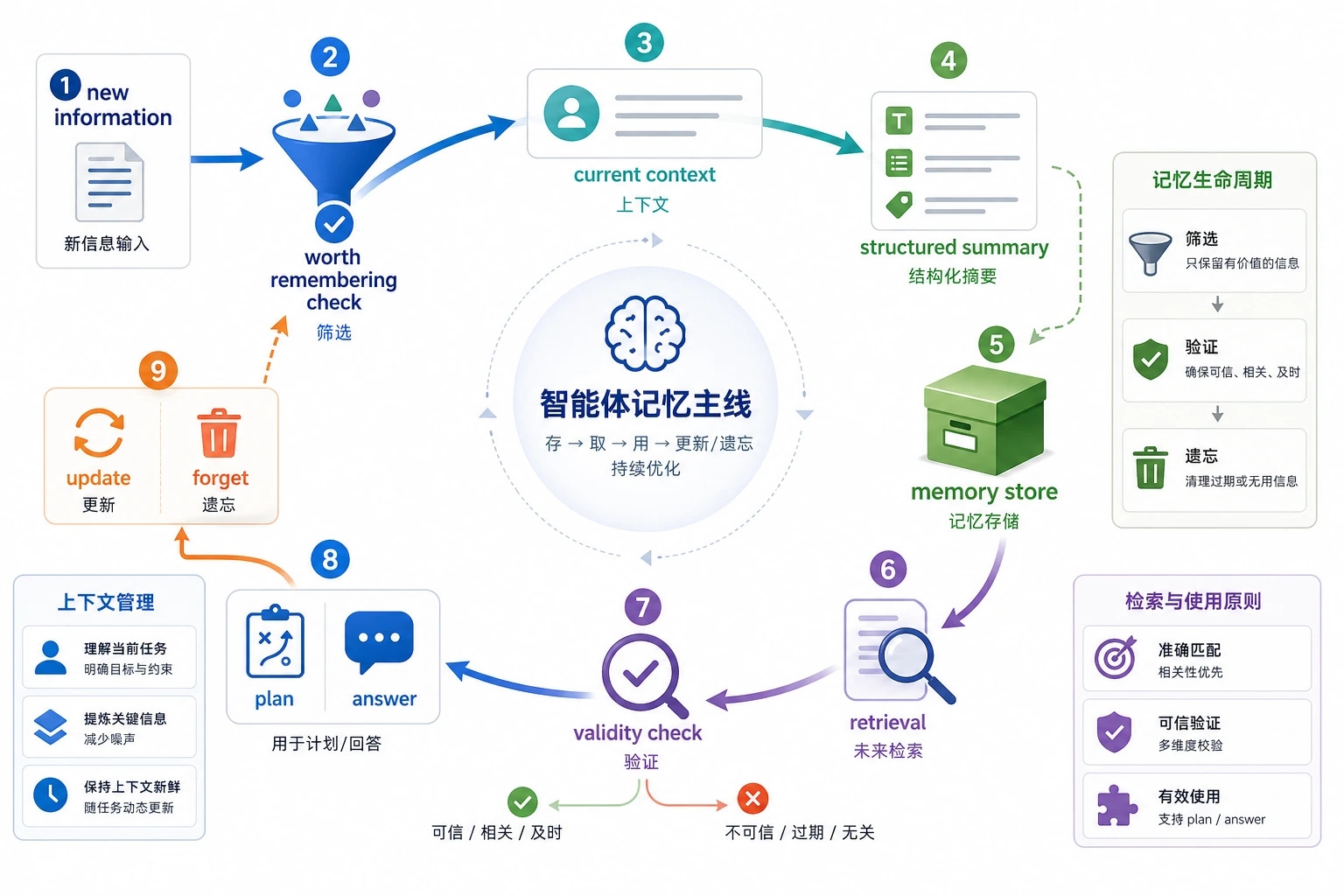
核心决策不是“全部保存”,而是什么该保存、何时检索、何时更新、何时遗忘。
跑一个记忆写入过滤器
只有稳定偏好和可复用事实才适合进入长期记忆。
events = [
{"type": "preference", "text": "prefers short examples"},
{"type": "temporary", "text": "debugging one local error"},
{"type": "fact", "text": "project uses Python"},
]
memory = []
for event in events:
if event["type"] in {"preference", "fact"}:
memory.append(event["text"])
print("saved:", memory)
print("count:", len(memory))
预期输出:
saved: ['prefers short examples', 'project uses Python']
count: 2
如果一条记忆不有用、不新鲜、没权限或检索不到,它可能比没有记忆更伤害 Agent。
按这个顺序学
| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | 记忆概览 | 区分上下文窗口、短期记忆、长期记忆 |
| 2 | 短期记忆 | 跟踪跨轮次的当前任务状态 |
| 3 | 长期记忆 | 保存稳定偏好、事实和项目背景 |
| 4 | 情节记忆与程序记忆 | 区分发生过什么和下次怎么做 |
| 5 | 记忆工程 | 设计写入、检索、更新、过期和删除规则 |
通过标准
如果你能解释为什么“记更多”不等于“表现更好”,就通过了本章。
本章出口小项目是一套学习规划助手记忆规则:什么保存、什么确认、什么临时保留、什么删除。