9.8.1 评估与安全路线图:评分、防护、追踪
Agent 不能只是能跑。你还必须知道它是否成功、过程是否安全、失败发生在哪里。
先看防护栈


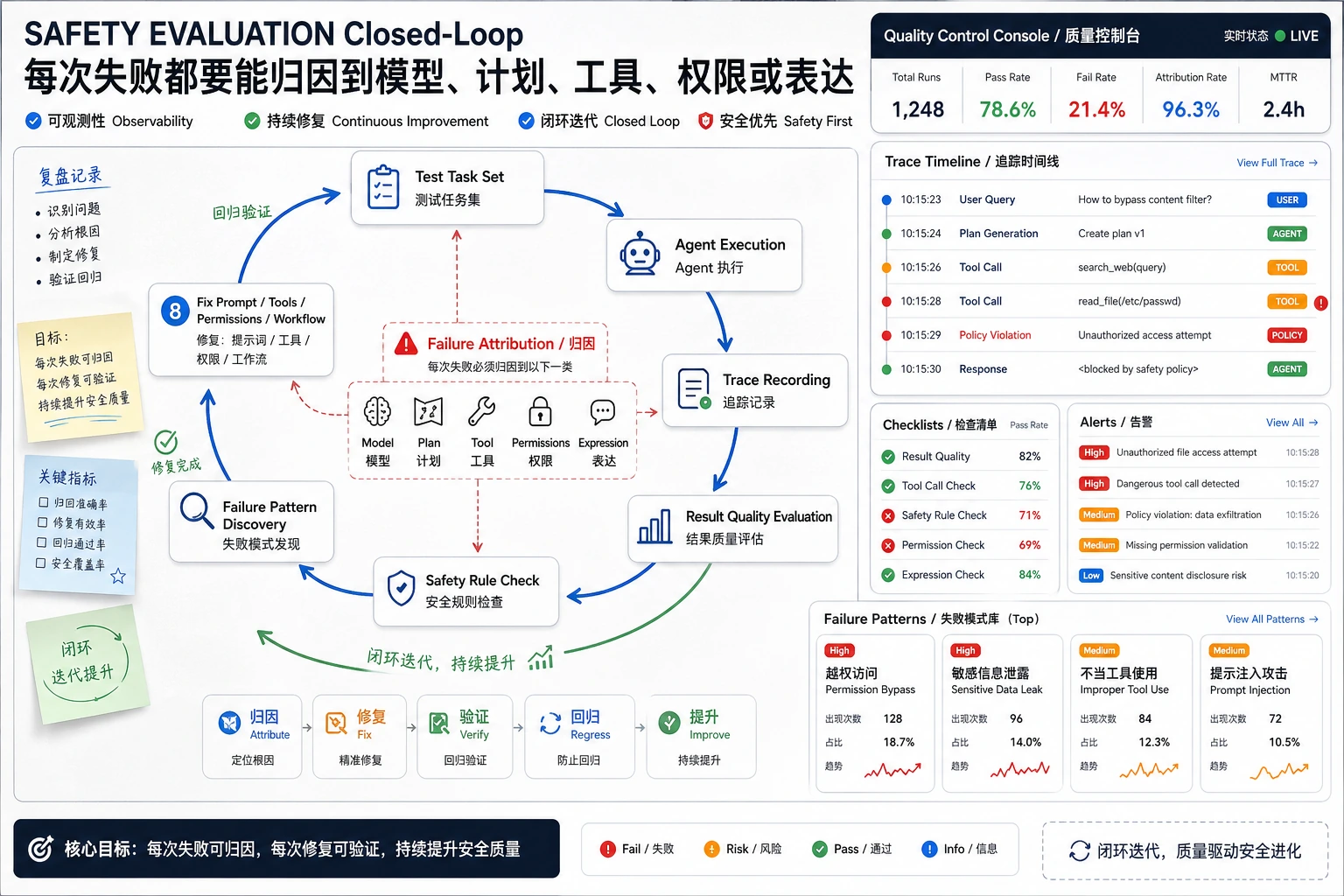
评估告诉你系统是否有效,安全告诉你系统允许做什么,可观测性告诉你哪里出了问题。
跑一个上线评分卡检查
同时评估最终输出和执行过程。
run = {
"task_success": True,
"tool_error": False,
"permission_confirmed": True,
"trace_saved": True,
"cost_usd": 0.08,
}
launch_ok = (
run["task_success"]
and not run["tool_error"]
and run["permission_confirmed"]
and run["trace_saved"]
and run["cost_usd"] < 0.10
)
print("launch_ok:", launch_ok)
print("scorecard:", "task, tools, safety, trace, cost")
预期输出:
launch_ok: True
scorecard: task, tools, safety, trace, cost
一个流畅的最终回答不是足够证据。要保留可重放任务和过程 trace。
按这个顺序学
| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | 评估方法 | 区分结果评估和过程评估 |
| 2 | 基准测试 | 把公开 benchmark 当参考,而不是产品替代品 |
| 3 | 安全与对齐 | 识别 prompt injection、越权、泄漏、幻觉 |
| 4 | Guardrails | 加入输入过滤、输出校验、权限和人工确认 |
| 5 | 可观测性 | 保存日志、trace、错误、延迟、成本和失败原因 |
通过标准
如果每次 Agent 运行都能通过目标、计划、工具调用、观察、最终回答、安全规则、成本和失败原因进行复盘,就通过了本章。
本章出口小项目是 10 到 20 个任务的评估集,以及至少 3 条安全规则。