9.2.5 计划-执行模式(Plan-and-Execute)
ReAct 很适合边走边看。 但当任务变长以后,它会遇到一个典型问题:
- 每一步都临场决定,容易飘
这时很多系统会换一种组织方式:
先用 planner 拆计划,再由 executor 按计划逐步完成。
这就是 Plan-and-Execute 的核心。
学习目标
- 理解 Plan-and-Execute 为什么适合长任务
- 理解 planner 和 executor 的职责分离
- 通过可运行示例看懂一个最小的“先规划再执行”系统
- 理解它和 ReAct 的差别与取舍
先建立一张地图
Plan-and-Execute 更适合按“高层先定路线,低层再跑步骤”来理解:
所以这节真正想解决的是:
- 为什么长任务不适合全程即兴
- 为什么计划层和执行层分开后,系统会更稳
为什么任务一长,就更需要“先规划”?
边走边想容易丢全局
如果任务只有一步两步, ReAct 的即兴决策通常够用。
但如果任务变成:
- 整理一周售后数据
- 统计高频问题
- 生成汇报
- 再给出改进建议
这类长任务就有更强的全局结构。
如果每一步都临时决定, 常见问题会是:
- 漏步骤
- 顺序错
- 做了重复工作
Planner 的作用:先把大任务变成小任务
Planner 最核心的价值不是“更聪明”, 而是:
- 先画路线图
它会回答:
- 一共有哪些步骤
- 步骤顺序是什么
- 哪些结果要传给后面
Executor 的作用:专心把当前步骤做好
把计划拆出来后, 执行器就可以少想一点“战略问题”, 更多关注:
- 当前步骤怎么完成
- 当前工具怎么调
- 当前结果怎么落库
这让系统更稳,也更容易调试。
一个更适合新人的总类比
你可以把 Plan-and-Execute 理解成:
- 先列施工清单,再安排工人按清单施工
如果没有施工清单,工人当然也能边做边想, 但任务一长就很容易出现:
- 漏步骤
- 顺序错
- 重复返工
这个类比很适合新人,因为它会把“planner / executor”重新拉回一个很日常的组织问题。
Plan-and-Execute 和 ReAct 的差别到底在哪里?
ReAct 更像边调查边走
它适合:
- 信息未知很多
- 下一步取决于上一轮 observation
Plan-and-Execute 更像先列施工清单
它适合:
- 任务结构比较清楚
- 步骤可以预先拆解
- 希望减少即兴漂移
两者不是敌对关系
很多真实系统其实会混用:
- 高层先 Plan-and-Execute
- 每个执行步骤内部再用 ReAct
也就是说:
- 规划负责全局
- ReAct 负责局部探索
一个很适合初学者先记的选择表
| 任务特点 | 更稳的第一反应 |
|---|---|
| 路径清楚、步骤多 | Plan-and-Execute |
| 信息未知多、边走边查 | ReAct |
| 既要全局规划,又要局部探索 | 两者混用 |
这个表很适合新人,因为它会把“该用哪种推理组织方式”变成一个能判断的问题。
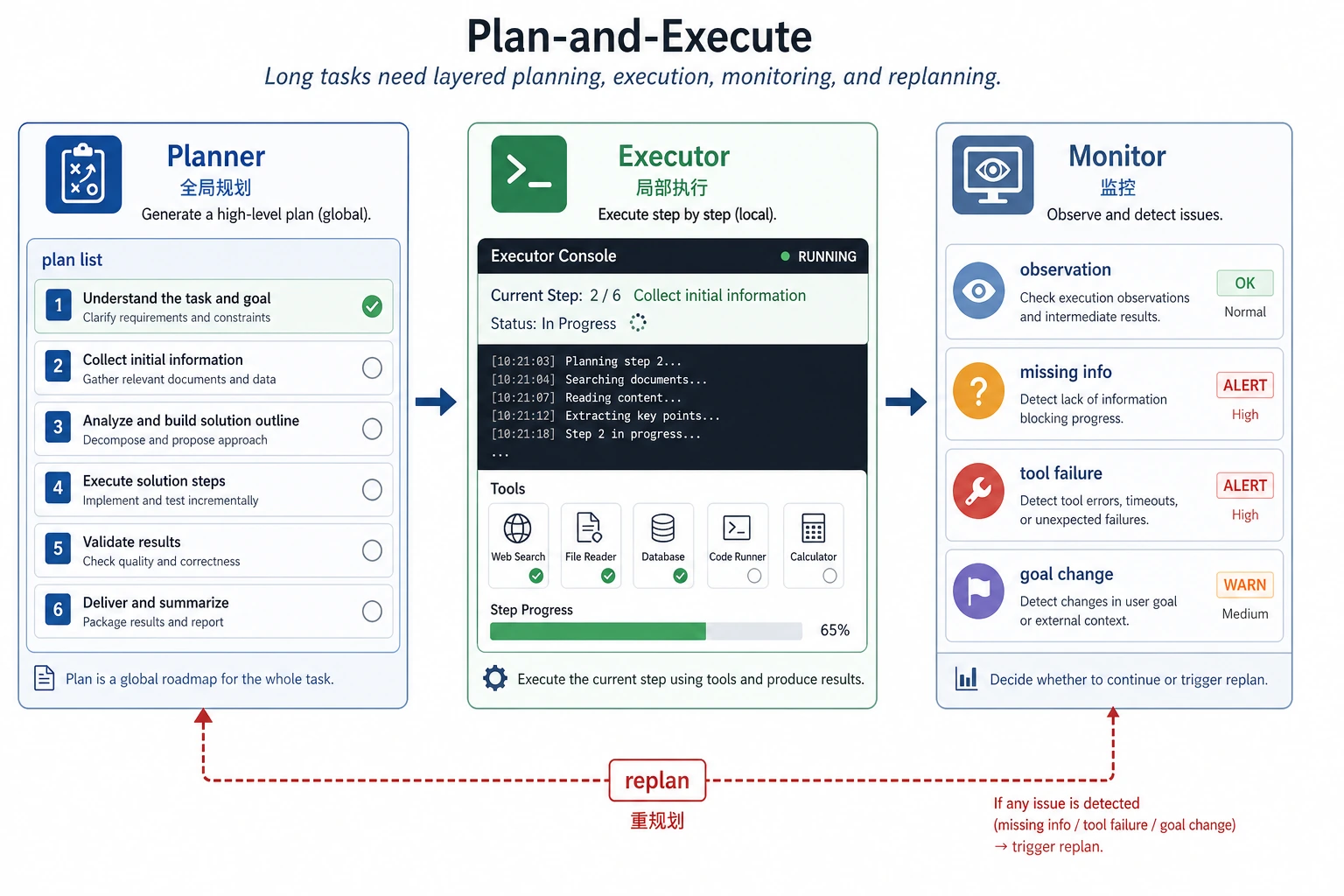
读图时注意两层职责:Planner 负责全局路线,Executor 负责当前步骤;Monitor 一旦发现缺资料、工具失败或目标变化,就触发 replan,而不是让系统硬走原计划。
先跑一个真正的最小 Plan-and-Execute 示例
下面这个例子会模拟一个“售后周报 Agent”。 用户任务是:
- 统计售后问题
- 找出高频意图
- 生成一份简短总结
我们会明确拆出:
- planner
- executor
tickets = [
{"intent": "refund", "text": "订单未发货,可以退款吗?"},
{"intent": "refund", "text": "退款多久到账?"},
{"intent": "password", "text": "忘记密码怎么办?"},
{"intent": "address", "text": "地址填错了还能改吗?"},
{"intent": "refund", "text": "退款为什么还没到账?"},
]
def planner(goal):
return [
{"step": "load_tickets", "description": "读取本周售后工单"},
{"step": "count_intents", "description": "统计各类问题数量"},
{"step": "find_top_intent", "description": "找出最高频问题"},
{"step": "draft_report", "description": "生成简短周报"},
]
def executor(task, context):
name = task["step"]
if name == "load_tickets":
context["tickets"] = tickets
return "已读取 5 条工单"
if name == "count_intents":
counts = {}
for item in context["tickets"]:
counts[item["intent"]] = counts.get(item["intent"], 0) + 1
context["intent_counts"] = counts
return counts
if name == "find_top_intent":
counts = context["intent_counts"]
top_intent = max(counts, key=counts.get)
context["top_intent"] = top_intent
return top_intent
if name == "draft_report":
counts = context["intent_counts"]
top_intent = context["top_intent"]
report = (
f"本周共处理 {len(context['tickets'])} 条售后工单。"
f"最高频问题是 {top_intent},出现 {counts[top_intent]} 次。"
f"建议优先优化 {top_intent} 流程和 FAQ 文案。"
)
context["report"] = report
return report
raise ValueError(f"Unknown step: {name}")
goal = "生成本周售后问题周报"
plan = planner(goal)
context = {}
trace = []
for task in plan:
output = executor(task, context)
trace.append({"task": task["step"], "output": output})
print("plan:")
for item in plan:
print("-", item)
print("\ntrace:")
for item in trace:
print(item)
print("\nfinal report:")
print(context["report"])
预期输出:
plan:
- {'step': 'load_tickets', 'description': '读取本周售后工单'}
- {'step': 'count_intents', 'description': '统计各类问题数量'}
- {'step': 'find_top_intent', 'description': '找出最高频问题'}
- {'step': 'draft_report', 'description': '生成简短周报'}
trace:
{'task': 'load_tickets', 'output': '已读取 5 条工单'}
{'task': 'count_intents', 'output': {'refund': 3, 'password': 1, 'address': 1}}
{'task': 'find_top_intent', 'output': 'refund'}
{'task': 'draft_report', 'output': '本周共处理 5 条售后工单。最高频问题是 refund,出现 3 次。建议优先优化 refund 流程和 FAQ 文案。'}
final report:
本周共处理 5 条售后工单。最高频问题是 refund,出现 3 次。建议优先优化 refund 流程和 FAQ 文案。

这段代码最关键的价值是什么?
它清楚分开了两件事:
- 规划 确定要做哪些步骤
- 执行 真正把步骤跑完,并把结果放进 context
这就是 Plan-and-Execute 最本质的结构。
context 在这里扮演什么角色?
它就是执行期的共享状态。
前一步产出的:
ticketsintent_countstop_intent
都会被后一步继续使用。
所以 Plan-and-Execute 的关键并不只是“有 plan”, 还包括:
- 中间产物怎样被安全传递
为什么这比单纯 for step in plan 更值得学?
因为这不是在演示一个循环, 而是在演示:
- 长任务如何拆分
- 依赖如何传递
- 最终结果如何逐步汇总
再看一个最小“计划检查表”示例
plan_quality = {
"steps_clear": True,
"order_defined": True,
"handoff_defined": False,
}
def next_fix(plan_quality):
if not plan_quality["steps_clear"]:
return "先把步骤描述写清楚。"
if not plan_quality["order_defined"]:
return "先明确执行顺序。"
if not plan_quality["handoff_defined"]:
return "先写清每一步产出怎样传给后一步。"
return "计划已经具备基本可执行性。"
print(next_fix(plan_quality))
预期输出:
先写清每一步产出怎样传给后一步。
这个示例很适合初学者,因为它会提醒你:
- 好计划不只是“列几个步骤”
- 还要考虑步骤之间的交接关系
Plan-and-Execute 什么时候特别有价值?
长任务
例如:
- 写报告
- 做研究总结
- 整理知识库
- 搭建多步骤业务流程
需要稳定复现的流程
如果你希望同类任务每次都按相近结构执行, 那显式计划会比完全即兴更稳。
需要人类审阅计划的场景
有些任务里, 你甚至会先把 plan 给人看一眼,再决定是否执行。
例如:
- 高风险操作
- 复杂数据处理
- 自动化流程变更
它最容易出什么问题?
计划一开始就拆错
如果 planner 把任务理解错了, 后面 executor 再认真也没用。
计划过死,不会根据新观察调整
这正是 Plan-and-Execute 的典型短板。
如果外部世界变化很快, 过于固定的计划可能会显得僵硬。
执行器和计划描述脱节
常见情况:
- planner 写了一个模糊步骤
- executor 却不知道怎么落地
所以计划步骤最好:
- 粒度明确
- 可以执行
- 输入输出清楚
工程上怎样让 Plan-and-Execute 更稳?
让 plan 结构化
不要只生成一串自然语言。 更好的形式通常是:
- step id
- description
- input
- output
每步执行完都写回 context
这样更利于:
- 调试
- 回放
- 重试
允许必要时 replan
Plan-and-Execute 最稳的版本往往不是:
- 一次计划,永不修改
而是:
- 大方向先规划
- 遇到重大偏差时允许重规划
如果把它做成项目或系统设计,最值得展示什么
最值得展示的通常不是:
- “系统先生成了一段计划”
而是:
- 用户目标
- Planner 拆出的步骤
- 每步执行后的 context 如何变化
- 哪些地方需要 replan
这样别人会更容易看出:
- 你理解的是长任务组织方式
- 不只是多加了一层 prompt
常见误区
误区一:有了 plan 就一定更聪明
计划能提升稳定性, 但前提是计划本身质量够好。
误区二:所有任务都要先 planner 再 executor
不一定。 短任务、强交互任务,ReAct 往往更自然。
误区三:计划只要写出步骤名就够了
真正可执行的计划,还需要:
- 步骤粒度
- 状态依赖
- 产出定义
小结
这节最重要的,不是把 Plan-and-Execute 当成另一个时髦名字,
而是理解它的核心工程价值:
当任务够长、够复杂、需要更稳定复现时,先规划再执行能显著减少即兴漂移,让系统更容易调试、审阅和维护。
只要这一层建立起来, 你后面再看 DAG 规划、多 Agent 分工和任务图调度,就会更顺。
练习
- 把示例里的“售后周报”换成“整理知识库回答”或“做竞品调研”,重新写一版 plan。
- 为什么说长任务比短任务更需要 planner?
- 如果执行到一半发现目标变了,你会如何设计 replan 机制?
- 想一想:哪些任务更适合 ReAct,哪些更适合 Plan-and-Execute?