9.7.5 多 Agent 实战模式
本节定位
前面我们已经讲了:
- 多 Agent 架构模式
- Agent 间通信
- 任务分配与协调
这一节要把这些东西落到更像“真实项目”的场景上:
多 Agent 在实际任务里,最常怎么组合?
学习目标
- 理解几种高频多 Agent 实战模式
- 学会根据任务目标选择更合适的协作方式
- 看懂一个小型多 Agent 工作流示例
- 理解“模式”为什么比“多开几个 Agent”更重要
为什么要讲“实战模式”?
因为真实系统通常不是纯理论架构
很多项目不会说:
- “我要一个 peer-to-peer 多 Agent 系统”
它更常说:
- “我要一个研究助理团队”
- “我要一个写作 + 审核工作流”
- “我要一个代码开发小组”
也就是说,真实项目更像“任务组织形态”,而不只是抽象架构名。
所以学实战模式的意义是什么?
它能帮你从:
- 抽象结构理解
走向:
- 具体产品落地
模式一:研究型协作
典型分工
- Planner:拆问题
- Researcher:检索资料
- Synthesizer:整合结果
适合什么任务?
- 做背景调研
- 收集材料
- 输出结构化报告
一个最小示例
def planner(query):
return ["收集退款政策", "整理时间条件", "形成结论"]
def researcher(task):
docs = {
"收集退款政策": "课程购买后 7 天内且学习进度低于 20% 可退款。",
"整理时间条件": "关键条件包括时间范围和学习进度。"
}
return docs.get(task, "未找到资料")
def synthesizer(items):
return "结论:" + " ".join(items)
plan = planner("退款政策是什么")
materials = [researcher(task) for task in plan[:-1]]
answer = synthesizer(materials)
print(plan)
print(materials)
print(answer)
预期输出:
['收集退款政策', '整理时间条件', '形成结论']
['课程购买后 7 天内且学习进度低于 20% 可退款。', '关键条件包括时间范围和学习进度。']
结论:课程购买后 7 天内且学习进度低于 20% 可退款。 关键条件包括时间范围和学习进度。
这个模式的关键是:
先发散搜集,再统一收敛。
模式二:写作 + 审核
最经典也最实用的模式之一
分工通常是:
- Writer:先写初稿
- Reviewer:检查问题
- Reviser:按意见修订
为什么这个模式特别常见?
因为很多任务天然就适合:
- 生成
- 检查
- 再修正
例如:
- 报告撰写
- 答案生成
- 代码文档
一个最小示例
def writer(topic):
return f"初稿:{topic} 的核心是 7 天内可退款。"
def reviewer(draft):
if "7 天内" in draft:
return "建议补充学习进度条件。"
return "时间条件缺失。"
def reviser(draft, review):
return draft + " " + review
draft = writer("退款政策")
review = reviewer(draft)
final = reviser(draft, review)
print(draft)
print(review)
print(final)
预期输出:
初稿:退款政策 的核心是 7 天内可退款。
建议补充学习进度条件。
初稿:退款政策 的核心是 7 天内可退款。 建议补充学习进度条件。
这个模式最大的好处是:
它把“生成能力”和“纠错能力”分开了。
模式三:开发团队模式
一个很常见的 AI 开发团队抽象
例如:
- PM / Planner:定义需求
- Coder:写实现
- Reviewer:做代码检查
- Tester:验证结果
为什么这个模式在 AI coding 场景里很常见?
因为软件开发天然就已经有这种角色分工。 多 Agent 只是把它程序化、自动化了。
一个最小示例
workflow = [
{"agent": "planner", "task": "定义要实现的功能"},
{"agent": "coder", "task": "写出实现代码"},
{"agent": "reviewer", "task": "检查逻辑问题"},
{"agent": "tester", "task": "验证输出是否符合预期"}
]
for step in workflow:
print(step["agent"], "->", step["task"])
预期输出:
planner -> 定义要实现的功能
coder -> 写出实现代码
reviewer -> 检查逻辑问题
tester -> 验证输出是否符合预期
这个模式的关键不是“角色好听”,而是:
每一层都能捕捉不同类型的问题。
模式四:双重核验 / 高风险审核模式
什么时候需要?
如果任务风险较高,比如:
- 法律建议
- 医疗辅助
- 金融判断
那么很多时候不能只让一个 Agent 单独产出结论。
常见做法
- 一个 Agent 生成答案
- 另一个 Agent 做事实核查
- 还有一个 Agent 检查风险与合规
这类模式虽然更慢,但更稳。
一个小型多 Agent 工作流示例
def planner(query):
return ["retrieve", "write", "review"]
def retriever(query):
return "检索结果:退款需满足时间与进度条件。"
def writer(material):
return f"回答草稿:{material}"
def reviewer(draft):
if "进度条件" in draft:
return {"approved": True, "comment": "信息较完整"}
return {"approved": False, "comment": "遗漏关键条件"}
query = "退款政策是什么?"
steps = planner(query)
material = retriever(query)
draft = writer(material)
review = reviewer(draft)
print("steps :", steps)
print("draft :", draft)
print("review :", review)
预期输出:
steps : ['retrieve', 'write', 'review']
draft : 回答草稿:检索结果:退款需满足时间与进度条件。
review : {'approved': True, 'comment': '信息较完整'}
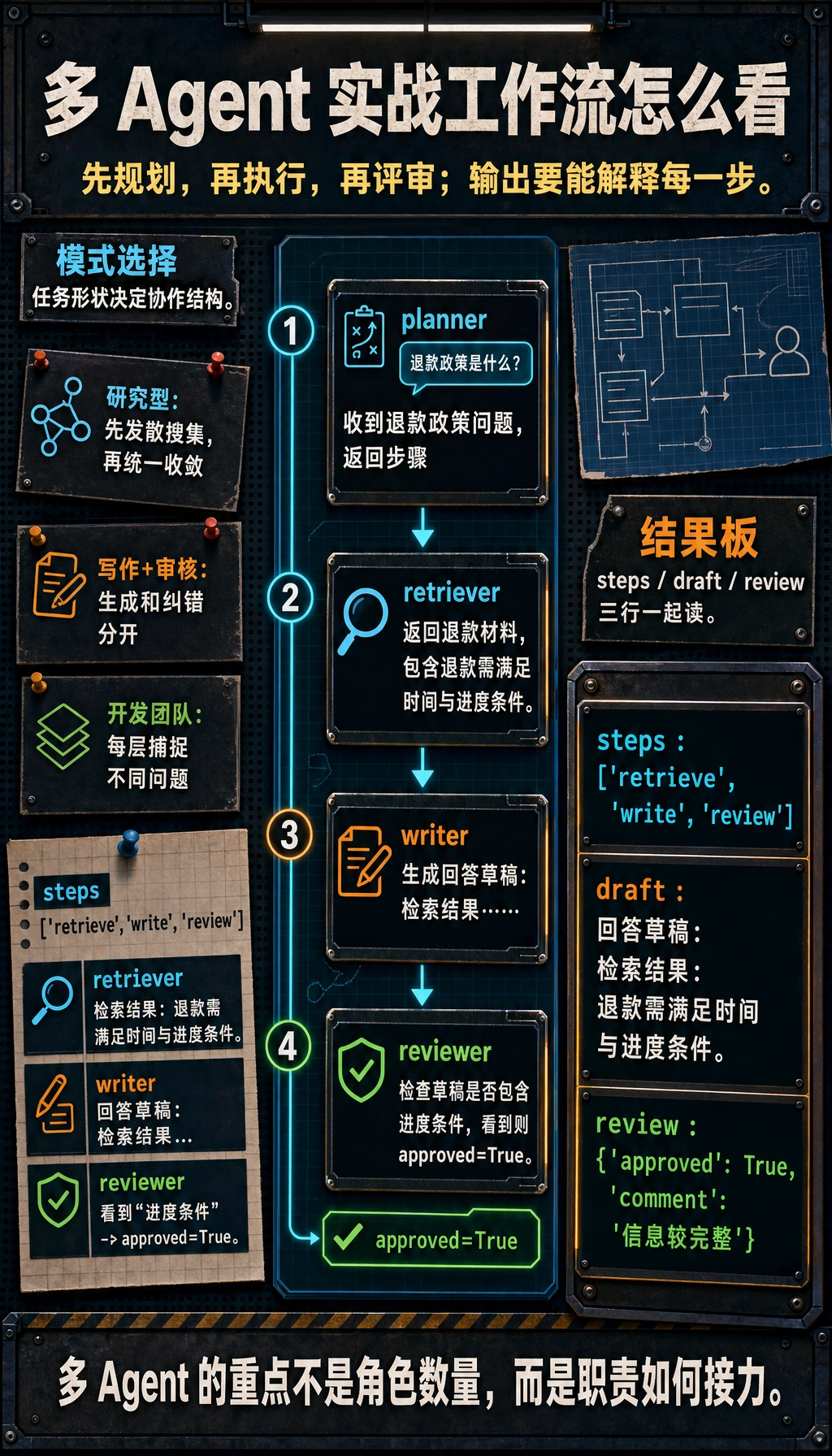
看职责接力,不只是看角色名
这段 trace 的价值在于每一行回答一个问题:planner 选了什么步骤,retriever 找到了什么材料,reviewer 为什么批准这个草稿。
这段代码虽然很小,但已经体现了实战模式最核心的味道:
- 先规划
- 再执行
- 再评审
怎样选合适的实战模式?
如果任务重点在搜资料
优先考虑:
- 研究型协作
如果任务重点在内容质量
优先考虑:
- 写作 + 审核
如果任务重点在工程落地
优先考虑:
- 开发团队模式
如果任务风险高
优先考虑:
- 双重核验 / 高风险审核模式
所以真正重要的问题不是:
“哪个模式最酷?”
而是:
“哪个模式最符合当前任务的失败风险和目标结构?”
初学者最常踩的坑
把模式和角色数量绑定死
不是“3 个 Agent 就一定是某模式”。 关键是职责关系,不是数量。
为了看起来复杂而堆模式
很多任务用单 Agent 或两 Agent 已经足够。
没有明确评价标准
如果你不知道“这个模式为什么比另一个模式更好”,那系统迭代会很难推进。
小结
这一节最重要的不是背“研究型”“开发型”这些标签,而是理解:
多 Agent 实战模式的价值,在于把抽象协作结构映射到真实任务目标。
当你能把任务形状和协作模式对应起来,多 Agent 才会真正从概念走向产品。
练习
- 选一个你熟悉的任务,判断它更像研究型、写作审核型还是开发团队型。
- 给本节的小型工作流再加一个
reviserAgent,让它根据 review 修改 draft。 - 想一想:高风险任务为什么更需要“生成 + 核查 + 风险审查”的组合?
- 用自己的话解释:为什么说多 Agent 的重点不是角色数量,而是协作结构?