9.8.1 Evaluation and Safety Roadmap: Score, Guard, Trace
An Agent should not only run. You must know whether it succeeded, whether the process was safe, and where the failure happened.
See the Guardrail Stack First

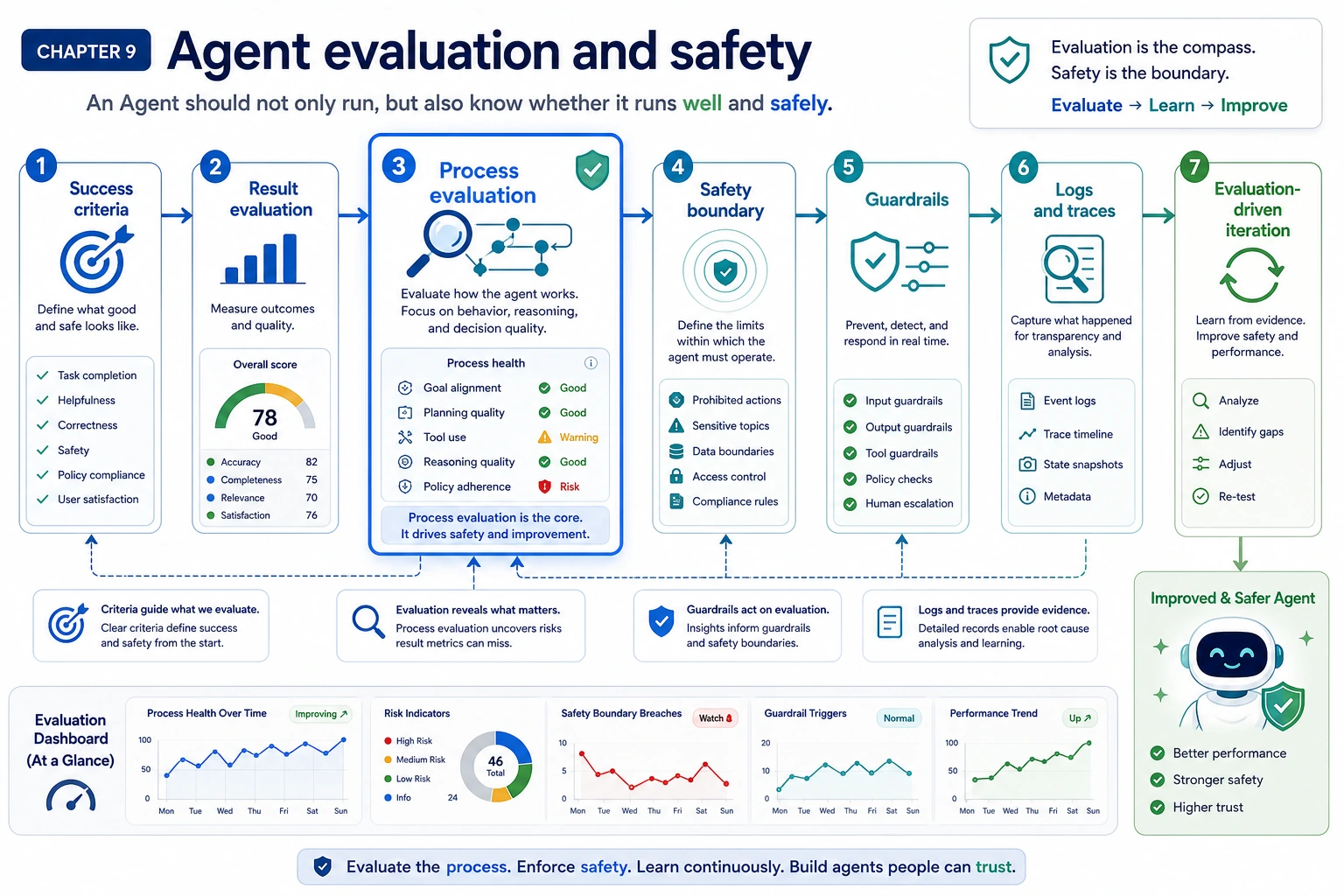
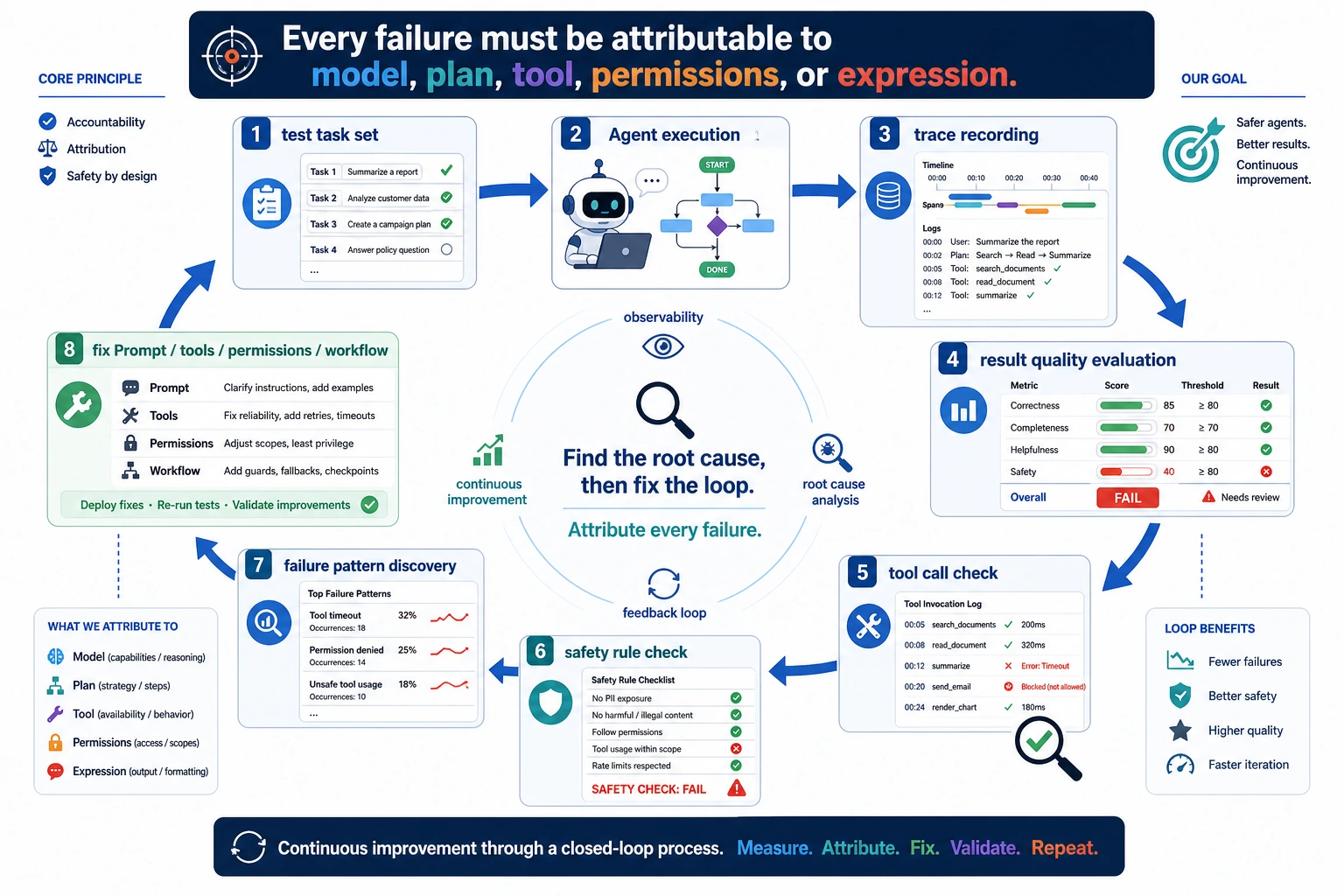
Evaluation tells you whether the system works. Safety tells you what it may do. Observability tells you where it broke.
Run a Launch Scorecard Check
Evaluate both final output and execution process.
run = {
"task_success": True,
"tool_error": False,
"permission_confirmed": True,
"trace_saved": True,
"cost_usd": 0.08,
}
launch_ok = (
run["task_success"]
and not run["tool_error"]
and run["permission_confirmed"]
and run["trace_saved"]
and run["cost_usd"] < 0.10
)
print("launch_ok:", launch_ok)
print("scorecard:", "task, tools, safety, trace, cost")
Expected output:
launch_ok: True
scorecard: task, tools, safety, trace, cost
One smooth final answer is not enough evidence. Keep replayable tasks and process traces.
Learn in This Order
| Step | Read | Practice Output |
|---|---|---|
| 1 | Evaluation methods | Separate result evaluation from process evaluation |
| 2 | Benchmarks | Use public benchmarks as reference, not a product replacement |
| 3 | Safety and alignment | Identify prompt injection, over-permission, leakage, hallucination |
| 4 | Guardrails | Add input filter, output validation, permissions, human confirmation |
| 5 | Observability | Save logs, traces, errors, latency, cost, and failure reason |
Pass Check
You pass this chapter when every Agent run can be reviewed through goal, plan, tool calls, observations, final answer, safety rule, cost, and failure reason.
The exit mini project is a 10 to 20 task evaluation set plus at least 3 safety rules.