E.A.7 部署综合项目
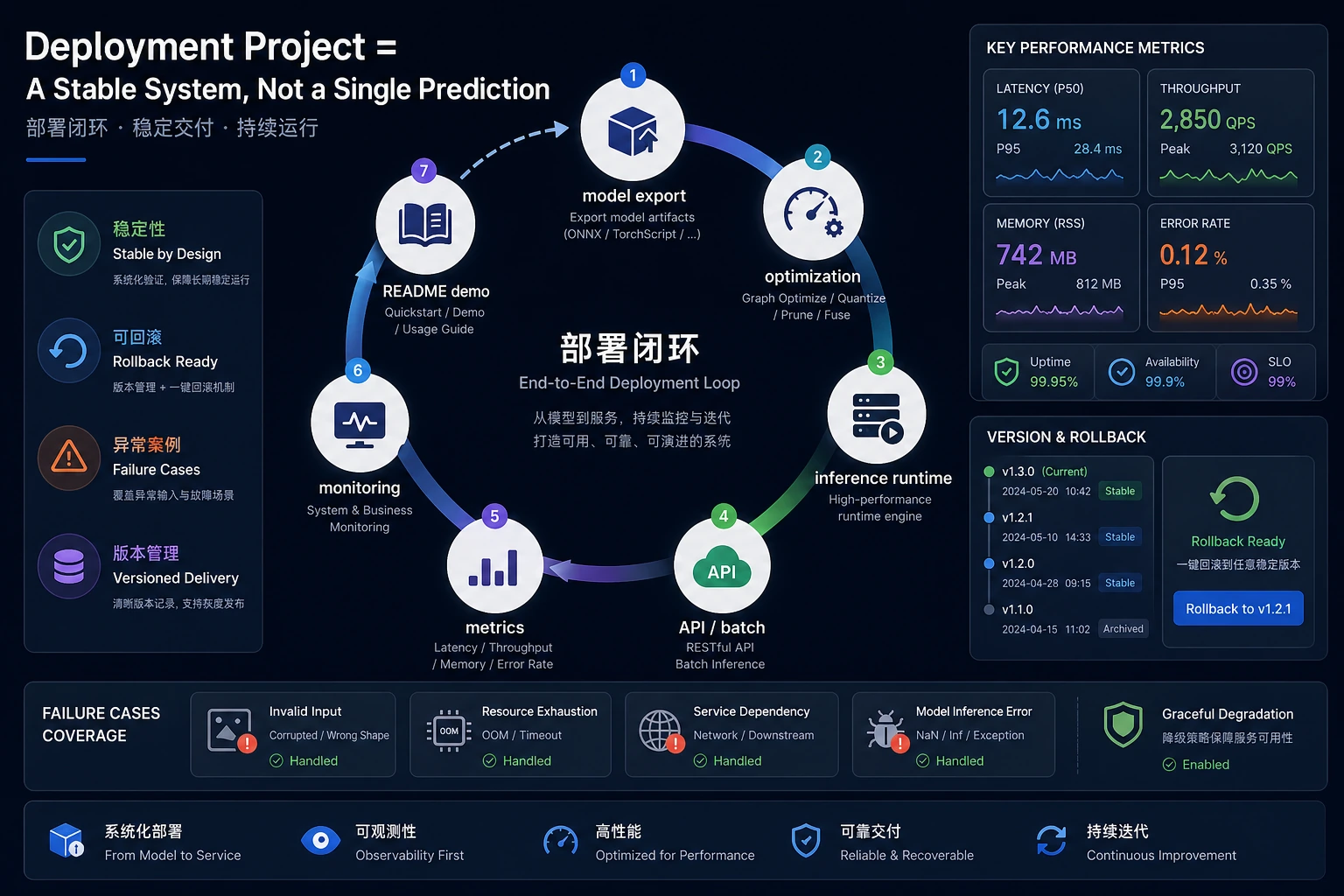
这个项目不是训练最大模型,而是证明你能把一个模型变成小型、可衡量、可部署的系统。
先构造一个简单项目故事:
轻量图像分类服务:支持本地推理、批处理、指标记录和边缘设备就绪检查。
准备内容
- Python 3.10+
- 不需要第三方包
- 一个小模型想法,可以是真模型,也可以先模拟
- 一个目标设备,例如笔记本 CPU、Raspberry Pi、Jetson 或云端 CPU 实例
交付清单
最终项目应展示:
- 目标设备和推理引擎选择
- 输入与输出示例
- 优化前后的指标对比
- 服务化或批处理流程
- 已知失败案例
- 复现命令
运行项目就绪评分
创建 deployment_project_check.py:
project = {
"name": "lightweight-image-classifier",
"target_device": "edge-c",
"engine": "ONNX Runtime",
"baseline": {"latency_ms": 120, "memory_mb": 820, "accuracy": 0.904},
"optimized": {"latency_ms": 68, "memory_mb": 430, "accuracy": 0.899},
"evidence": ["README.md", "metrics.csv", "failure_cases.md"],
}
checks = {
"latency_under_80": project["optimized"]["latency_ms"] < 80,
"memory_under_512": project["optimized"]["memory_mb"] < 512,
"accuracy_drop_ok": project["baseline"]["accuracy"] - project["optimized"]["accuracy"] <= 0.01,
"has_failure_cases": "failure_cases.md" in project["evidence"],
}
for name, passed in checks.items():
print(name, passed)
release_candidate = all(checks.values())
print("release_candidate:", release_candidate)
print("evidence_files:", project["evidence"])
运行:
python deployment_project_check.py
预期输出:
latency_under_80 True
memory_under_512 True
accuracy_drop_ok True
has_failure_cases True
release_candidate: True
evidence_files: ['README.md', 'metrics.csv', 'failure_cases.md']
这就是可展示部署项目的形状:不只是代码,还要有证据。
如何讲这个项目
建议按这个顺序:
- 问题:要运行什么、运行在哪里、为什么要这样做。
- 约束:内存、延迟、硬件、离线要求。
- 设计:模型格式、推理引擎、服务链路。
- 证据:优化前后指标和失败案例。
- 取舍:哪些还没优化,为什么暂时不做。
常见错误
- 只展示界面,不展示指标。
- 优化了延迟,却不说明准确率下降。
- 没有内存测试或长时间运行测试,就宣称边缘设备可用。
- 项目范围太大,一次想覆盖云端、移动端和边缘端。
练习
增加第二个目标设备,重新运行就绪检查。然后写三行 README,说明为什么选择这个设备和推理引擎。