E.A.7 デプロイ統合プロジェクト
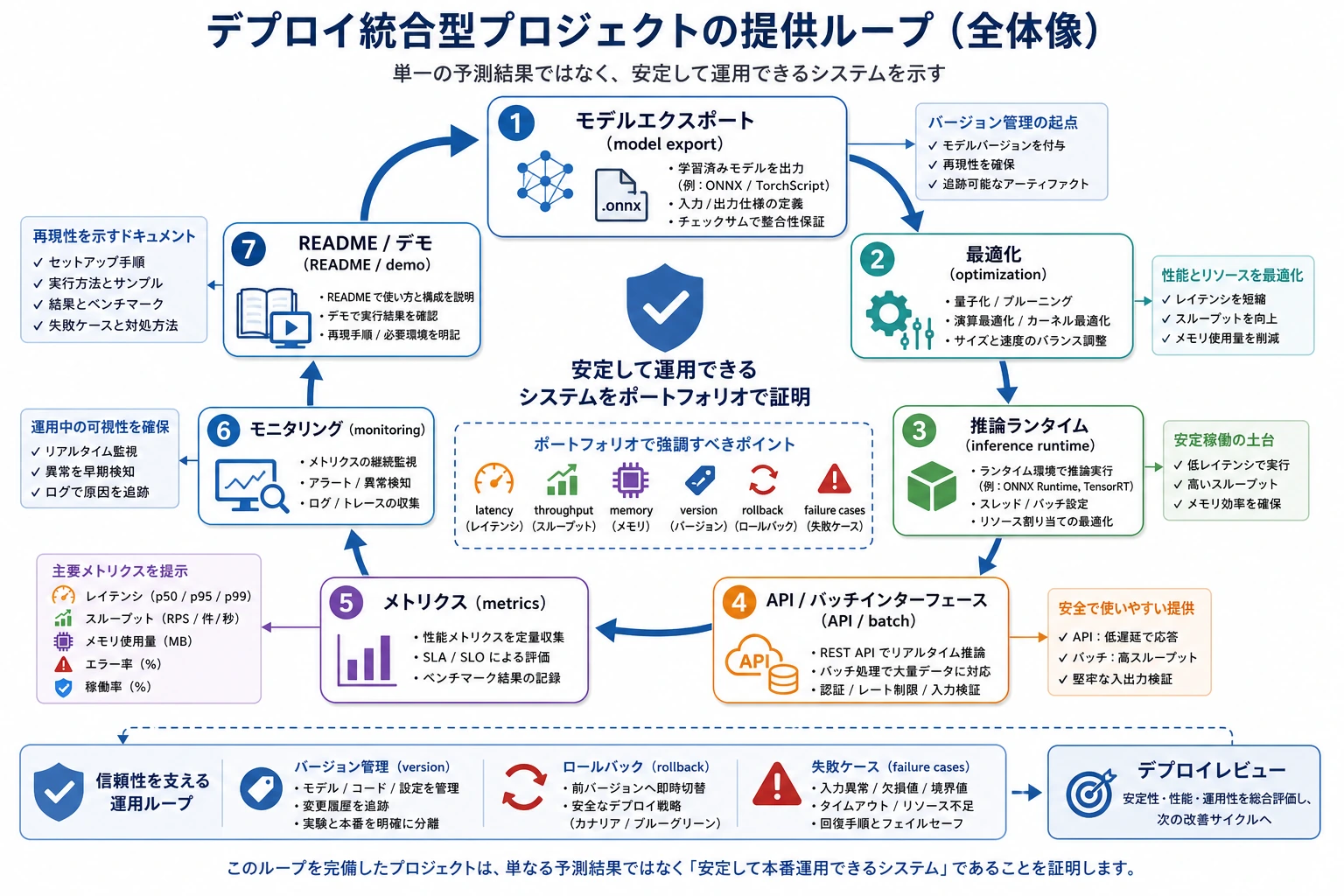
このプロジェクトの目的は、最大のモデルを学習することではありません。モデルを小さく、測定可能で、デプロイできるシステムに変えられることを示すことです。
まず、次のようなシンプルなプロジェクトストーリーを作ります。
軽量画像分類サービス:ローカル推論、バッチ処理、指標記録、エッジデバイスの準備チェックに対応する。
準備するもの
- Python 3.10+
- 外部パッケージ不要
- 実モデルでもシミュレーションでもよい、小さなモデル案
- ノートPC CPU、Raspberry Pi、Jetson、クラウド CPU インスタンスなどの対象デバイス
納品チェックリスト
最終プロジェクトでは、次を見せます。
- 対象デバイスと推論エンジンの選択
- 入力と出力の例
- ベースラインと最適化後の指標
- サービス化またはバッチ処理の流れ
- 既知の失敗ケース
- 再現コマンド
プロジェクト準備スコアを動かす
deployment_project_check.py を作成します。
project = {
"name": "lightweight-image-classifier",
"target_device": "edge-c",
"engine": "ONNX Runtime",
"baseline": {"latency_ms": 120, "memory_mb": 820, "accuracy": 0.904},
"optimized": {"latency_ms": 68, "memory_mb": 430, "accuracy": 0.899},
"evidence": ["README.md", "metrics.csv", "failure_cases.md"],
}
checks = {
"latency_under_80": project["optimized"]["latency_ms"] < 80,
"memory_under_512": project["optimized"]["memory_mb"] < 512,
"accuracy_drop_ok": project["baseline"]["accuracy"] - project["optimized"]["accuracy"] <= 0.01,
"has_failure_cases": "failure_cases.md" in project["evidence"],
}
for name, passed in checks.items():
print(name, passed)
release_candidate = all(checks.values())
print("release_candidate:", release_candidate)
print("evidence_files:", project["evidence"])
実行します。
python deployment_project_check.py
期待される出力:
latency_under_80 True
memory_under_512 True
accuracy_drop_ok True
has_failure_cases True
release_candidate: True
evidence_files: ['README.md', 'metrics.csv', 'failure_cases.md']
これが見せられるデプロイプロジェクトの形です。コードだけでなく、証拠も必要です。
プロジェクトの説明順序
この順番で話すと伝わりやすくなります。
- 問題:何を、どこで、なぜ動かすのか。
- 制約:メモリ、レイテンシ、ハードウェア、オフライン要件。
- 設計:モデル形式、推論エンジン、サービス経路。
- 証拠:最適化前後の指標と失敗ケース。
- トレードオフ:まだ最適化していない点と、その理由。
よくある間違い
- デモ画面だけを見せて、指標を見せない。
- レイテンシを改善した一方で、精度低下を隠す。
- メモリテストや長時間運転テストなしに、エッジ対応と言う。
- 範囲を広げすぎて、クラウド、モバイル、エッジを一度に扱おうとする。
練習
2つ目の対象デバイスを追加し、準備チェックをもう一度実行してください。その後、README に3行だけ、なぜそのデバイスと推論エンジンを選んだのかを書きます。