5.6.3 プロジェクト2:顧客離脱予測(分類問題)
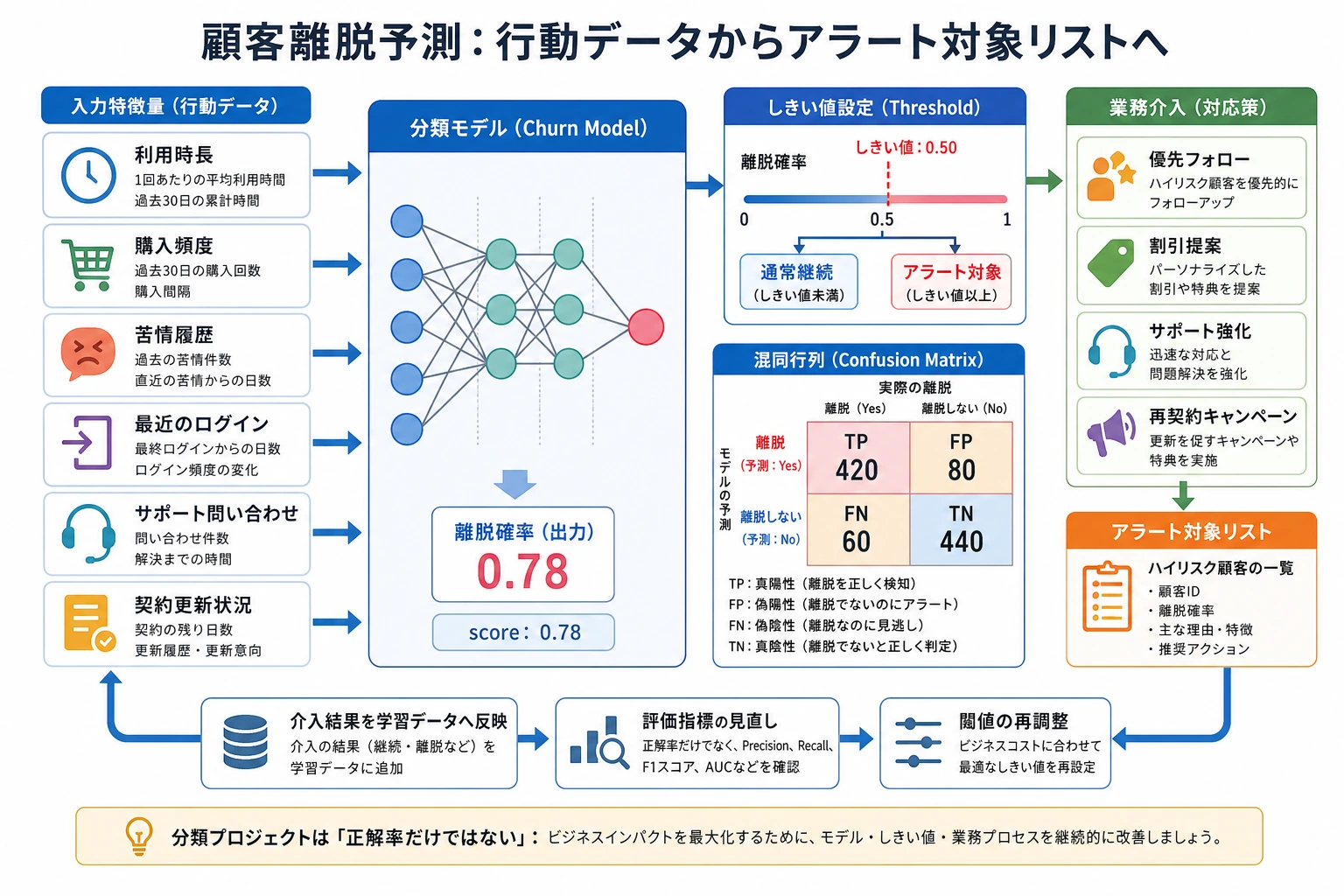
顧客離脱予測は、最も定番のビジネス向け ML アプリケーションの1つです。このプロジェクトでは、主に次の点を練習します:不均衡データの処理、ビジネス指標の理解、モデル結果からビジネス洞察を引き出すこと。
プロジェクト概要
| 情報 | 説明 |
|---|---|
| タスク種別 | 2値分類(離脱/継続) |
| コアな課題 | データ不均衡(離脱顧客が継続顧客よりかなり少ない) |
| 評価指標 | F1、AUC、再現率 |
| 関連スキル | 不均衡対策、Pipeline、ビジネス分析 |
コードを読む前に押さえる用語
- Recall(再現率):本当に離脱した顧客のうち、どれだけ見つけられたかを表します。離脱顧客を見逃すコストが高いときに重要です。
- Precision(適合率):高リスクと判定した顧客のうち、本当に離脱した顧客がどれだけいたかを表します。施策コストが高いときに重要です。
- F1:適合率と再現率の調和平均です。1つのバランス指標として便利ですが、具体的なビジネス上の取捨選択は隠れてしまいます。
- ROC(Receiver Operating Characteristic):しきい値を変えたときに、再現率と偽陽性率がどう変わるかを示す曲線です。
- AUC(Area Under the Curve):ROC 曲線を1つの数値にまとめたものです。AUC が高いほど、離脱顧客を継続顧客より前に並べる力が強いと考えられます。
- SMOTE(Synthetic Minority Over-sampling Technique):少数クラスの合成サンプルを作る方法です。不均衡データに有効な場合がありますが、必ず訓練データまたは交差検証の訓練 fold の中だけで使います。
class_weight(クラス重み):合成サンプルを作らず、少数クラスの誤りをより重く扱う設定です。- Threshold(しきい値):離脱確率を「離脱する / しない」に変える境界です。しきい値を下げると、通常は再現率が上がりますが、誤検知も増えます。
まず、とても重要な学習イメージを共有します
この問題は、初心者が最初に「モデル比較」に入り込みやすいです。
- ロジスティック回帰
- ランダムフォレスト
- SMOTE
- AUC
でも、最初の1回で本当に身につけるべきなのは、実は「どのモデルが一番高得点か」ではありません。大事なのは、次のことです。
不均衡な分類問題で、ビジネスコスト、指標の選び方、しきい値の判断、モデル結果をどうつなげるかをきちんと理解すること。
この流れが先に見えると、この問題は「もう1問の分類問題」ではなく、実際のプロジェクトらしくなります。
まず全体の地図を作ろう
この問題の価値は、「2値分類器を作ること」そのものではありません。最初に本当に向き合うのは、次の3つです。
- データの不均衡
- しきい値の選択
- ビジネスコストの違い
つまり、この問題で本当に練習するのは「どう分類判断をするか」であって、単に「分類モデルを動かすこと」ではありません。
この問題で本当に練習すること
このプロジェクトの核心は、「分類器を動かすこと」ではなく、次の練習です。
- 不均衡データで、なぜ正解率だけを見てはいけないのか
- 再現率、適合率、ビジネスコストの間でどうバランスを取るのか
- モデル結果をどうビジネス洞察に変えるのか
最初の版で、まず何をはっきりさせるべきか
この問題を初めてやるとき、まず説明すべきなのはモデル名ではなく、次の点です。
- 離脱顧客の割合はどれくらいか
- なぜ正解率だけではダメなのか
- ビジネスとして「離脱しそうな顧客を見逃したくない」なら、どの指標を重視すべきか
この3つを先に押さえると、その後のモデル選択やしきい値調整に意味が出ます。
初心者向けのたとえ
この問題は、こんなふうに考えると分かりやすいです。
- 顧客が本当に離れる前に、早めに「要注意リスト」を作る
このリストの価値は、
- 全員を100%完璧に当てること
ではなく、
- 許容できる誤検知コストの範囲で、本当に離脱しそうな人をできるだけ見逃さないこと
にあります。
だから、この問題は最初から正解率だけを見てはいけません。
おすすめの進め方
- まず不均衡を処理しない baseline を作る
- 次にクラス重みを試す
- さらに SMOTE などを試す
- 最後に ROC、AUC、F1 とビジネス解釈を比べる
こうすると、どこで改善したのかが分かります。
初めてこの問題をやるときの、いちばん安定した順番
初めて顧客離脱予測をするなら、次の順番がおすすめです。
- まずビジネス目標をはっきりさせる
- 次にクラス分布を見る
- そのあと元の baseline を作る
- 次に
class_weightを使う - 最後に SMOTE を試す
- それから、しきい値を再現率寄りにするか、適合率寄りにするか決める
こうすると、改善の理由が次のどれなのかが見えやすくなります。
- モデル
- サンプリング
- しきい値戦略
Step 1:ダミーデータを作る
import pandas as pd
import numpy as np
from sklearn.datasets import make_classification
# 不均衡な顧客データを作成
X, y = make_classification(
n_samples=5000, n_features=15, n_informative=8,
n_redundant=3, weights=[0.85, 0.15], # 85% 継続, 15% 離脱
random_state=42
)
feature_names = ['月額利用額', '通話時間', 'データ使用量', 'サポート通話回数', '契約期間',
'請求トラブル', 'プラン等級', '家族人数', '利用継続期間', '先月の苦情',
'データ超過回数', '国際ローミング', '追加サービス数', '口座残高', '端末変更']
df = pd.DataFrame(X, columns=feature_names)
df['離脱'] = y
print(f"データ形状: {df.shape}")
print(f"離脱率: {df['離脱'].mean():.1%}")
print(f"離脱顧客: {df['離脱'].sum()}, 継続顧客: {(1-df['離脱']).sum():.0f}")
Step 2:不均衡データの処理
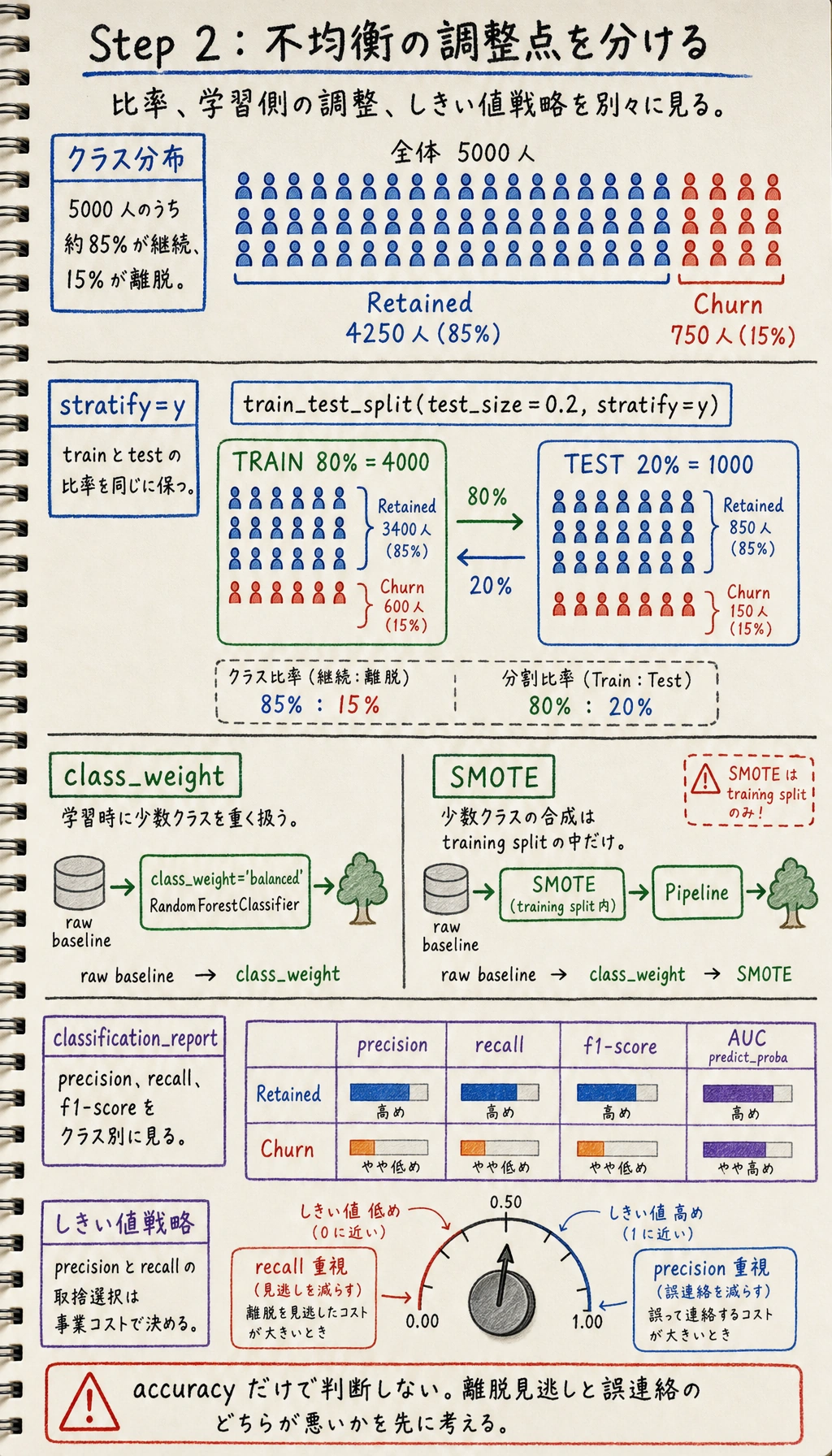
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, roc_auc_score
import matplotlib.pyplot as plt
X = df.drop('離脱', axis=1)
y = df['離脱']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 方法1: クラス重み
rf_weighted = RandomForestClassifier(n_estimators=100, class_weight='balanced', random_state=42)
rf_weighted.fit(X_train, y_train)
y_pred = rf_weighted.predict(X_test)
print("クラス重み付きランダムフォレスト:")
print(classification_report(y_test, y_pred, target_names=['継続', '離脱']))
print(f"AUC: {roc_auc_score(y_test, rf_weighted.predict_proba(X_test)[:,1]):.4f}")
Step 2.1 なぜ最初から SMOTE を使わないのか
より安定した順番は、たいてい次の通りです。
- まず元の baseline を作る
- 次に
class_weightを試す - 最後に
SMOTEを試す
こうすると、次の違いを切り分けられます。
- 改善がモデル自体によるものか
- サンプリング戦略によるものか
- しきい値調整によるものか
SMOTE によるオーバーサンプリング
# python -m pip install --upgrade imbalanced-learn
try:
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import Pipeline as ImbPipeline
smote_pipe = ImbPipeline([
('smote', SMOTE(random_state=42)),
('classifier', RandomForestClassifier(n_estimators=100, random_state=42)),
])
smote_pipe.fit(X_train, y_train)
y_pred_smote = smote_pipe.predict(X_test)
print("\nSMOTE + ランダムフォレスト:")
print(classification_report(y_test, y_pred_smote, target_names=['継続', '離脱']))
except ImportError:
print("imbalanced-learn をインストールしてください: python -m pip install --upgrade imbalanced-learn")
Step 3:特徴量重要度とビジネス洞察
# 特徴量重要度
importance = rf_weighted.feature_importances_
sorted_idx = np.argsort(importance)
plt.figure(figsize=(8, 8))
plt.barh(range(len(sorted_idx)), importance[sorted_idx], color='coral')
plt.yticks(range(len(sorted_idx)), np.array(feature_names)[sorted_idx])
plt.xlabel('特徴量重要度')
plt.title('顧客離脱予測——特徴量重要度')
plt.grid(axis='x', alpha=0.3)
plt.tight_layout()
plt.show()
# ビジネス提案
print("\nビジネス洞察:")
top3 = np.array(feature_names)[np.argsort(importance)[-3:]]
for i, feat in enumerate(reversed(top3), 1):
print(f" {i}. {feat} は離脱予測で最も重要")
Step 4:ROC の比較
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
models = {
'ロジスティック回帰': make_pipeline(StandardScaler(), LogisticRegression(class_weight='balanced', max_iter=1000)),
'ランダムフォレスト': RandomForestClassifier(n_estimators=100, class_weight='balanced', random_state=42),
}
plt.figure(figsize=(8, 6))
for name, model in models.items():
model.fit(X_train, y_train)
proba = model.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(y_test, proba)
auc = roc_auc_score(y_test, proba)
plt.plot(fpr, tpr, linewidth=2, label=f'{name} (AUC={auc:.4f})')
plt.plot([0, 1], [0, 1], 'k--', alpha=0.5)
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('顧客離脱予測 ROC 比較')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
Step 4.1 この段階で、さらに足すとよいもの
この問題をより実務らしくするなら、次に足すとよいのは次の内容です。
- 混同行列を1枚
- しきい値 vs Precision / Recall / F1 の曲線を1枚
- 「再現率を優先するなら、しきい値をどこに寄せるか」の説明
実際の継続施策では、デフォルトのしきい値 0.5 で誰が高得点かよりも、
- 許容できる誤検知コストの中で、高リスク顧客をどれだけ多く拾えるか
のほうが重要なことが多いです。
プロジェクト提出時に、できれば追加したい内容
- クラス分布の図
- 混同行列
- ROC 曲線
- 「離脱顧客をできるだけ拾いたい場合、しきい値をどう調整するか」の説明
実務っぽい振り返りの順番
次の順番でプロジェクトを振り返ると、分かりやすいです。
- データ分布とビジネス目標
- baseline モデルの結果
- 不均衡処理後の変化
- 指標のトレードオフとしきい値調整
- 特徴量重要度とビジネス提案
- 本番導入するなら、どう監視するか
さらにこのプロジェクトを発展させるなら、何を足すべきか
優先度が高いのは、たいてい次の3つです。
- しきい値調整ページ
- 誤判定した顧客ケースの分析
- 異なるビジネス目標に応じた指標切り替えの説明
こうすると、ただの「分類タスク」ではなく、より実際のビジネス判断システムに近い作品になります。
ポートフォリオとして見せるなら、何を見せるべきか
- クラス分布とタスク目標
- baseline と改善版の比較
- ROC または PR 曲線
- しきい値の説明図
- 実行可能な顧客運用の提案
プロジェクトチェックリスト
- データ不均衡の程度を分析する
- 少なくとも2種類の不均衡対策(クラス重み、SMOTE)を試す
- F1 と AUC で評価する(正解率だけを見ない)
- 特徴量重要度を分析し、ビジネス提案を出す
- 複数モデルで ROC 曲線を比較する
バージョンの進め方
| バージョン | 目標 | 提出の重点 |
|---|---|---|
| 基礎版 | 最小限の流れを通す | 入力できる、処理できる、出力できる、そしてサンプルを1組残す |
| 標準版 | 見せられるプロジェクトにする | 設定、ログ、エラー処理、README、スクリーンショットを追加する |
| 挑戦版 | ポートフォリオ品質に近づける | 評価、比較実験、失敗サンプル分析、次の改善方針を追加する |
まずは基礎版を完成させるのがおすすめです。最初から全部入りを目指さなくて大丈夫です。バージョンを1つ上げるたびに、「何が増えたか、どう検証したか、まだ何が課題か」を README に書きましょう。