6 深層学習と Transformer 基礎

第 6 章の目的は 1 つです。モデルが損失、勾配、反復する学習ステップによってどう学ぶのかを理解することです。
メインルートでの位置
Section titled “メインルートでの位置”ここまでに sklearn モデルを学習し、指標とエラーサンプルで結果を判断しました。この章では学習ループを開きます。tensor がデータを運び、モデルが予測を作り、loss が誤りを測り、逆伝播が勾配を計算し、optimizer がパラメータを更新します。
ここは LLM に入る前の最後のモデル基礎章です。すべての構造を完全に習得してから進む必要はありません。学習、shape、Attention、Transformer block を十分に理解し、第 7 章が魔法に見えない状態にすることが目標です。
まず学習ループを見る
Section titled “まず学習ループを見る”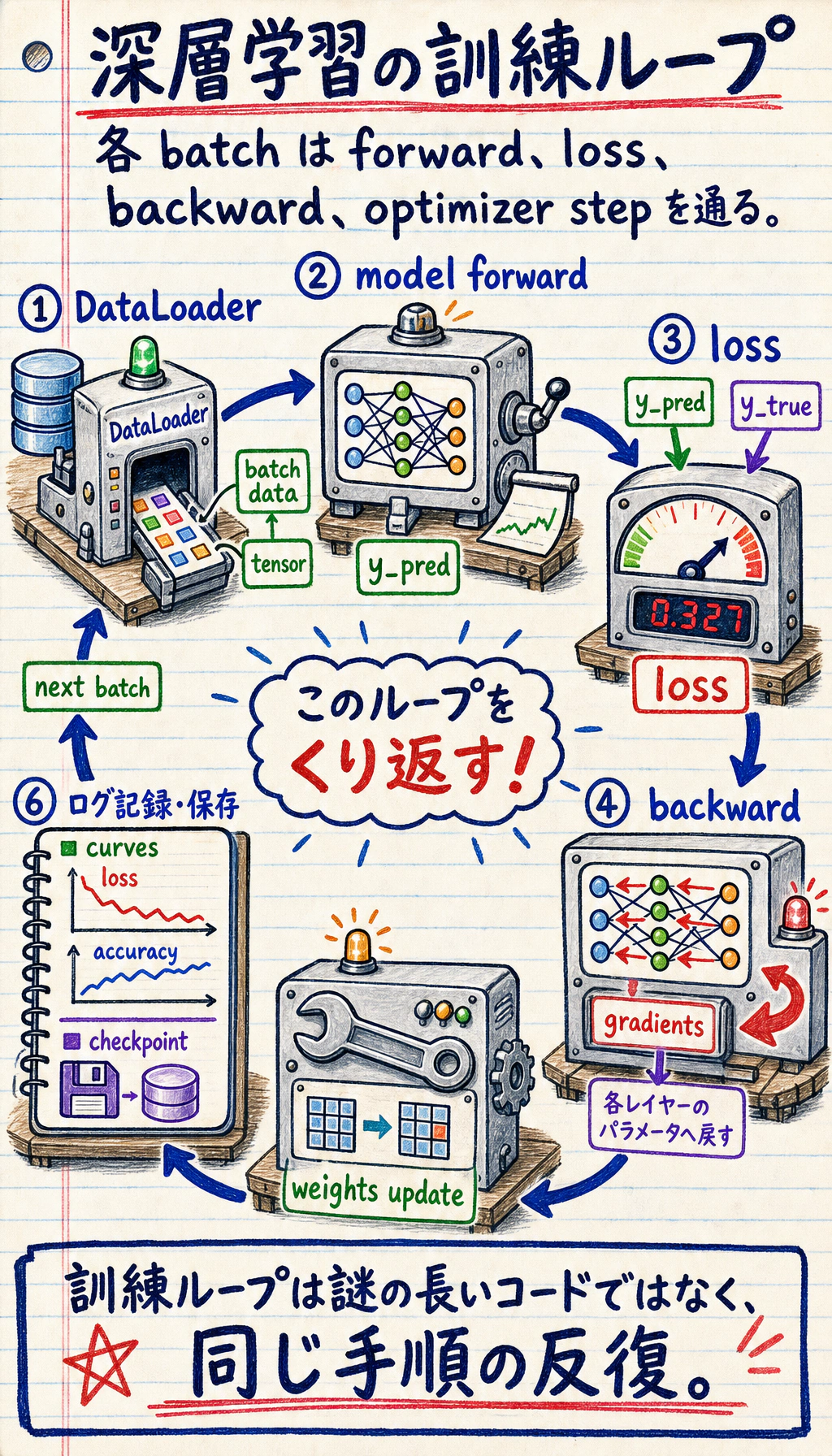
先に図を見てください。深層学習の学習コードの多くは、この流れです。
最初から大きなモデルを追わないでください。まず小さなモデルを学習させ、何が起きたかを記録し、なぜ改善または失敗したかを説明します。
学習順序とタスクリスト
Section titled “学習順序とタスクリスト”このチェックリストを、本章の学習ガイド兼タスクリストとして使います。まず中核ルート 6.1 -> 6.2 -> 6.5 -> 6.8 を進みます。CNN、RNN、生成モデル、学習テクニックは、プロジェクトで必要になったときに戻る拡張として扱います。
-
6.1 ニューラルネットワーク基礎 手を動かすこと:ニューロン、活性化、forward/backward、optimizer、正則化、初期化を理解する。 残す証拠:手書きの学習ループ説明。
-
6.2 PyTorch 手を動かすこと:tensor、autograd、
nn.Module、Dataset、DataLoader、最小学習ループを練習する。 残す証拠:実行できる PyTorch スクリプト。 -
6.5 Transformer 手を動かすこと:Query、Key、Value、self-attention、位置エンコーディング、Transformer block を学ぶ。 残す証拠:attention の入出力図。
-
6.8 プロジェクト と 6.8.5 ワークショップ 手を動かすこと:画像、感情分析、生成プロジェクトの前に PyTorch 証拠パックを作る。 残す証拠:ログ、曲線、checkpoint、shape trace、README。
-
6.3 CNN 手を動かすこと:画像分類でデータ形状、畳み込み、プーリング、転移学習をつなげる。 残す証拠:shape メモと画像分類の実行結果。
-
6.4 RNN 手を動かすこと:系列データに記憶が必要な理由、LSTM/GRU が Transformer 前に解いた問題を理解する。 残す証拠:系列モデルメモ。
-
6.1.8 任意の深層学習史 手を動かすこと:主な学習ループを理解してから、backprop、CNN、RNN、Attention、Transformer がなぜ現れたかを読む。 残す証拠:「この構造がある理由」のメモ。
-
6.6 生成モデル と 6.7 学習テクニック 手を動かすこと:学習ループが安定してから拡張として扱う。 残す証拠:チューニングまたは診断メモ。
必修ルート、拡張、深掘り
Section titled “必修ルート、拡張、深掘り”| 層 | いま学ぶこと | どう使うか |
|---|---|---|
| 必修コア | Tensor shape、autograd、nn.Module、Dataset/DataLoader、学習ループ、検証曲線、Attention、Transformer | 第 7 章で token、文脈、LLM の振る舞いを理解するための心内モデルになります |
| 任意の拡張 | CNN、RNN、GAN/VAE、圧縮、発展的な調整 | 画像、系列、生成、デプロイのプロジェクトで必要になったときに戻ります |
| 深掘り課題 | ごく小さい batch を意図的に過学習させ、それが何を証明し、何を証明しないか説明する | 後の学習失敗をデバッグしやすくします |
本章でよく使う用語:
| 用語 | 意味 |
|---|---|
tensor | PyTorch が使う多次元配列 |
forward | データがモデルを通り、予測を作る流れ |
loss | 予測誤差を測る数値 |
backward | loss から勾配を計算すること |
optimizer | 勾配を使ってパラメータを更新するもの |
epoch | 学習データ全体を 1 回見ること |
batch | 一度に処理する小さなサンプル群 |
最初の実行ループ
Section titled “最初の実行ループ”PyTorch がなければ公式セレクタで先にインストールします。PyTorch が使える状態で、次の小さな学習ループを実行してください。
import torchfrom torch import nn
torch.manual_seed(42)x = torch.tensor([[0.0], [1.0], [2.0], [3.0]])y = torch.tensor([[0.0], [2.0], [4.0], [6.0]])
model = nn.Linear(1, 1)loss_fn = nn.MSELoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(20): pred = model(x) loss = loss_fn(pred, y) optimizer.zero_grad() loss.backward() optimizer.step() if epoch in {0, 1, 5, 19}: print(epoch, round(loss.item(), 4))期待される形:
0 ...1 ...5 ...19 ...具体的な数値は環境で変わることがありますが、loss はおおむね下がるはずです。下がれば、学習ループが動いていることを確認できています。
先へ進む前に、小さな開始記録を残します。
- 最初のループ実行
- 小さな PyTorch ループが4行の loss を出力した
- 損失の方向
- 損失は全体として低下した
- 主要経路
- 6.1 → 6.2 → 6.5 → 6.8
- 次のデバッグ手順
- loss が動かない場合は、shape、loss、gradients、optimizer step を確認する
これは最初の例を checkpoint にします。ここで全 architecture を一気に覚える必要はありません。まず学習ループが見えるようになったことを証明します。
第 7 章への橋
Section titled “第 7 章への橋”LLM に入る前に、次のつながりを確認してください。
- 第 4 章のベクトルは token embedding と検索 embedding になります。
- 第 5 章の指標とエラーサンプルは Prompt 評価と RAG 評価になります。
- 本章の Attention と Transformer block は token から回答までの経路になります。
- 学習はパラメータを更新しますが、推論は学習済みパラメータを使って出力を生成します。
| レベル | 証明できること |
|---|---|
| 最低合格 | forward、loss、backward、optimizer step を順番に説明できる。 |
| プロジェクト利用可 | 小さな PyTorch モデルを実行し、loss の変化を見て、tensor shape を解釈できる。 |
| 深い確認 | 1 つのごく小さい batch を意図的に過学習させ、そのテストが大きなモデル前に役立つ理由を説明できる。 |
失敗サンプル練習
Section titled “失敗サンプル練習”この章を出る前に、失敗した、または疑わしい training run を1つ保存します。次の形式で書きます。
run_id:symptom: shape mismatch、flat loss、overfitting、OOM、confusing attention outputfirst_check:likely_cause:fix_attempt:result_after_fix:これにより、training failure は回復可能な engineering record になります。目的はすべての error を避けることではなく、最初にどの evidence を表示するかを知ることです。
よくある失敗
Section titled “よくある失敗”| 症状 | 最初に確認すること | よくある修正 |
|---|---|---|
| shape mismatch | 入力 shape、batch 次元、出力クラス数 | 各層で tensor shape を表示する |
| loss が下がらない | 学習率、ラベル、正規化、損失関数 | まず小さな batch を過学習できるか試す |
| 学習は良いが検証が悪い | 過学習またはデータ分割の問題 | 検証曲線、データ拡張、正則化、early stopping を使う |
| メモリ不足 | batch サイズ、画像サイズ、モデルサイズ | batch/解像度を下げる、軽いモデルにする |
| Transformer が抽象的 | Q/K/V と系列長 | コード前に attention 表を描く |
通過チェック
Section titled “通過チェック”次の 5 つに答えられたら、第 7 章へ進めます。
forward、loss.backward()、optimizer.step()はそれぞれ何をしますか?- Dataset と DataLoader はそれぞれ何を解決しますか?
- 学習曲線と検証曲線は、過学習をどう示しますか?
- Attention はなぜ文脈を扱えますか?
- Transformer は後の大規模モデルとどうつながりますか?
印刷用のチェックリストが必要なときは、6.0 学習ガイドとタスクリスト を使ってください。後の LLM、RAG、多モーダルモデルは、すべてこの表現学習の考え方の上にあります。