10 コンピュータビジョン(方向選択)
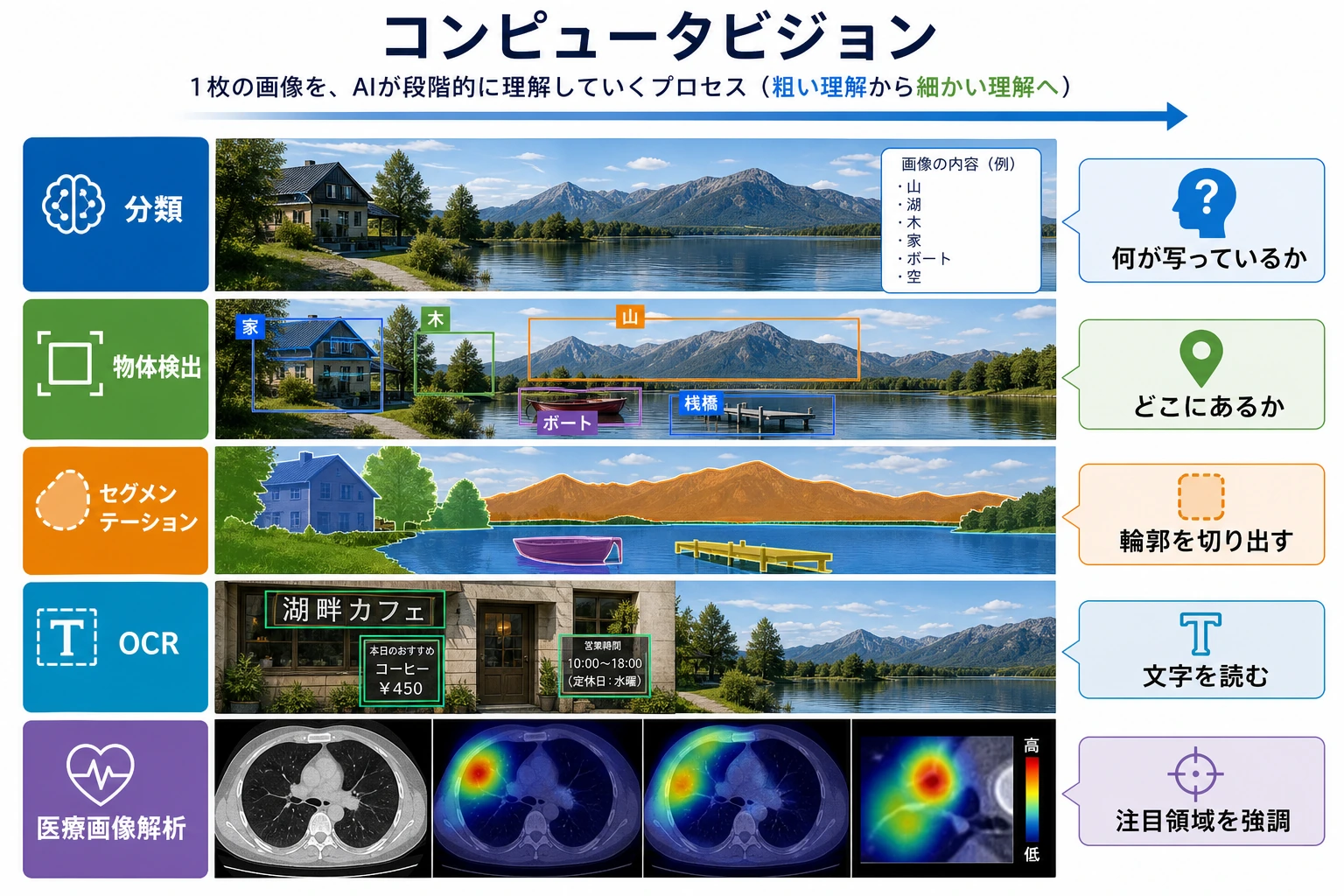
この選択章で答える問いはシンプルです。モデルが画像を見るとは、何を意味するのか。 まずピクセルから始め、出力の細かさに沿って進みます。画像全体を分類し、物体を位置づけ、ピクセルを分割し、最後に OCR、動画、マルチモーダルへつなげます。
主線が LLM アプリと Agent なら、あとで戻ってきても大丈夫です。OCR、産業検査、医用画像、画像検索、マルチモーダル製品に関心があるなら、体系的に学ぶ価値があります。
出力粒度で視覚タスクを見る
Section titled “出力粒度で視覚タスクを見る”
同じ画像に3つの質問をします。
| 質問 | タスク | 出力 |
|---|---|---|
| この画像は主に何か? | 分類 | 1つ以上のラベル |
| 各物体はどこにあるか? | 検出 | box、label、confidence |
| どのピクセルがどの物体や領域か? | セグメンテーション | mask またはピクセルクラス |
| どんな文字や視覚意味を取り出せるか? | OCR / 視覚理解 | テキスト、表、説明、回答 |
学習順序とタスク表
Section titled “学習順序とタスク表”まず出力タイプを理解し、それからプロジェクトへ進みます。同じ画像でも複数のタスクになります。
| 手順 | 読む内容 | 手を動かすこと | 残す証拠 |
|---|---|---|---|
| 10.1 | 画像基礎と OpenCV | ピクセル、チャンネル、リサイズ、グレー化、エッジを確認 | 入力画像、処理後画像 |
| 10.2 | 画像分類 | 小さな分類器を実行または訓練 | label、accuracy/F1、失敗画像 |
| 10.3 | 物体検出 | box、confidence、IoU、mAP、YOLO を理解 | 予測 box と閾値メモ |
| 10.4 | セグメンテーション | mask とピクセル単位ラベルを理解 | mask 可視化と IoU/Dice メモ |
| 10.5 | 応用トピック | 必要なときだけ OCR、動画、顔、3D、医療方向を選ぶ | 方向メモとシナリオ境界 |
| 10.6 | ステージプロジェクト | 10.6.4 実践:再現可能なビジョンミニパイプラインを作る を動かす | 生成画像、mask、box、指標、失敗レポート |
最初に動かすループ:依存なしでピクセルを見る
Section titled “最初に動かすループ:依存なしでピクセルを見る”この依存なしの小さなラボは、小さなカラー画像を作り、グレー画像へ変換し、多くの画像ビューアで開ける形式で保存します。学ぶ核心は、画像が構造化された数値データだということです。
ch10_pixel_lab.py を作成し、Python 3.10 以降で実行してください。
from pathlib import Path
width, height = 8, 8
pixels = [ [(x * 32, y * 32, 128) for x in range(width)] for y in range(height)]
gray = [ [round(0.299 * r + 0.587 * g + 0.114 * b) for r, g, b in row] for row in pixels]
ppm_body = "\n".join(" ".join(f"{r} {g} {b}" for r, g, b in row) for row in pixels)pgm_body = "\n".join(" ".join(str(value) for value in row) for row in gray)
Path("synthetic_rgb.ppm").write_text(f"P3\n{width} {height}\n255\n{ppm_body}\n")Path("synthetic_gray.pgm").write_text(f"P2\n{width} {height}\n255\n{pgm_body}\n")
print("size:", (width, height))print("channels:", 3)print("top_left_rgb:", pixels[0][0])print("center_gray:", gray[height // 2][width // 2])print("saved:", "synthetic_rgb.ppm", "synthetic_gray.pgm")期待される出力:
- Size
- (8, 8)
- Channels
- 3
- Top Left Rgb
- (0, 0, 128)
- Center Gray
- 128
- Saved
- synthetic_rgb.ppm synthetic_gray.pgm
操作メモ: width、height、RGB の式を変えてください。保存画像が変われば、すでに画像前処理をしています。後の章では、この小さなラボを OpenCV、Pillow、PyTorch、検出・セグメンテーションモデルへ置き換えます。
この出力の読み方
Section titled “この出力の読み方”sizeとchannelsは、モデルが見る前の画像データの形を示します。top_left_rgbは画像説明ではなく、実際のピクセル値です。center_grayは、前処理によって RGB データが 1 つのグレー値に変換されたことを示します。- 保存されたファイルは証拠です。処理前後のファイルを示せないと、前処理が正しいかを後で調べにくくなります。
| 段階 | 証明できること |
|---|---|
| 最低合格 | pixel lab を実行し、画像サイズ、チャンネル、RGB 値、グレー変換、保存出力を説明できる。 |
| 実務準備 | 出力に合うタスクを選び、元画像、処理画像、予測画像を残し、適切な指標を報告し、失敗例を保存できる。 |
| 深い確認 | 構造を変える前に、誤りを data、annotation、preprocessing、model、threshold、metric、deployment constraint に切り分けられる。 |
視覚結果をデバッグする
Section titled “視覚結果をデバッグする”
視覚モデルが間違えたら、まず入力とラベルを確認し、そのあとモデル構造を疑います。
| 症状 | まず表示・可視化するもの | 修正候補 |
|---|---|---|
| 分類が不安定 | 誤分類画像とクラス数 | データ清掃、クラス再バランス、augmentation 調整 |
| 小物体を見逃す | 画像解像度、box、confidence 閾値 | ラベル改善、解像度向上、閾値調整 |
| セグメンテーション境界が粗い | mask を元画像に重ねた図 | アノテーション改善、適切な IoU/Dice 指標 |
| デモ画像は良いが実画像で悪い | 照明、角度、背景、カメラ | 実サンプルとシナリオ説明を追加 |
このページを終えたら、この evidence card を残します。
- タスク出力
- 分類ラベル、検出ボックス、セグメンテーションマスク、OCR テキスト、または動画イベント
- 成果物
- 元画像、処理後画像、予測オーバーレイ、metrics ファイル、失敗サンプル
- 指標
- accuracy/F1、mAP、IoU、Dice、レイテンシ、またはシナリオ別レビュー評価
- 失敗確認
- データ品質、ラベル誤り、前処理不一致、閾値、または本番制約
- 期待される成果
- ビジュアル出力と短い失敗レポートを含む再現可能な実行フォルダ
よくある失敗
Section titled “よくある失敗”- データ品質を見ずにモデル名を追う。
- accuracy だけ報告し、失敗画像を保存しない。
- 分類、検出、セグメンテーションの出力を混同する。
- ラベルの意味を変えてしまう augmentation を使う。
- 画像サイズ、遅延、デバイスメモリなど配置制約を無視する。
この選択章を出る前に、次をできるようにしてください。
- 分類、検出、セグメンテーション、OCR、視覚理解を出力で説明できる。
- ピクセルラボを動かし、画像サイズ、チャンネル、RGB 値、グレー値を説明できる。
- 入力画像、処理画像、予測、指標、失敗例を残せる。
- accuracy/F1、mAP、IoU、Dice など適切な指標を選べる。
- 再現可能なビジョンミニパイプラインを動かし、短い失敗分析を書ける。
印刷用チェックリストは 10.0 学習チェックリスト を使ってください。プロジェクトから始めたい場合は 10.6.4 実践:再現可能なビジョンミニパイプラインを作る へ進みます。