4 AI 数学:最小限の基礎

第 4 章の目的は 1 つです。モデルの中の数学を、実行でき、説明できる道具として感じられるようにすることです。
メインルートでの位置
Section titled “メインルートでの位置”ここまでに、基本的なコーディングとデータ分析の流れを作りました。この章では、その作業をモデルの言葉へ変換します。データはベクトルや行列になり、不確かさは確率になり、誤りは loss になり、改善は勾配にもとづくパラメータ更新になります。
続ける前に数学者になる必要はありません。最小の例を実行し、出力を読み、各数式がどのモデル動作を支えるか説明できれば十分です。第 5 章では、この土台を sklearn のモデル学習と評価に使います。
まずモデル数学ループを見る
Section titled “まずモデル数学ループを見る”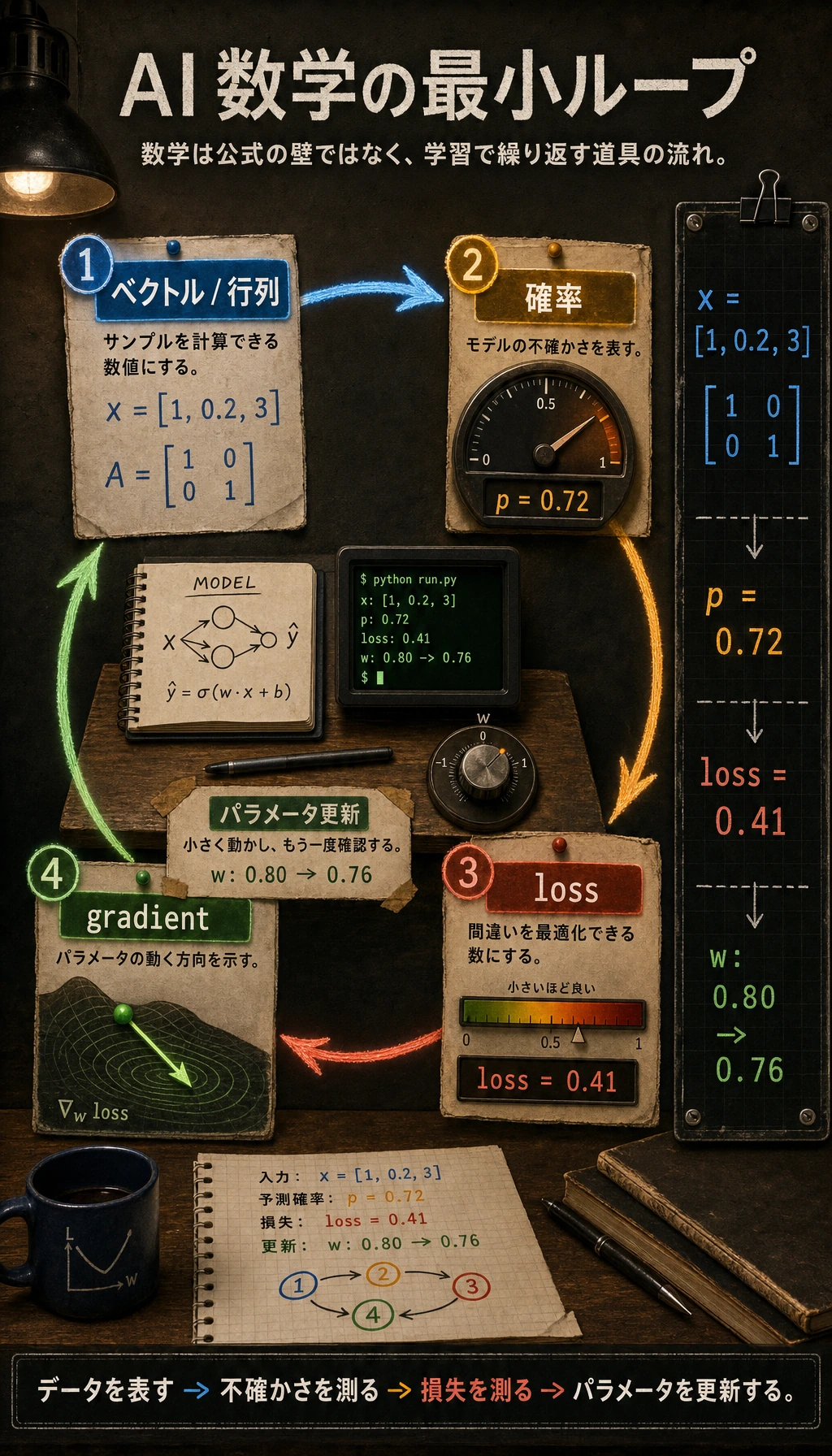
先に図を見てください。このコースの AI 数学の多くは、次のループを支えます。
データを表す不確かさを測る損失を測るパラメータを更新する
ベクトルと行列はデータを表し、確率は不確かさを表し、損失はどれくらい間違ったかを示し、勾配はどちらへ改善するかを示します。
学習順序とタスクリスト
Section titled “学習順序とタスクリスト”先に理論を学び、その後でフルワークショップを実行します。ワークショップは、概念をゼロから紹介する場ではなく、学んだ内容をつなげる場です。
- 4.1 線形代数: ベクトル、行列、内積、ノルム、コサイン類似度で例を比較する。
- 4.2 確率と統計: 不確かさ、分布、平均、分散、エントロピー、損失をシミュレーションする。
- 4.3 微積分と最適化: 導関数、勾配、学習率、勾配降下を追跡する。
- 4.4 フル数学ワークショップ: 1 つの実行スクリプトで全体をつなげ、
ch04_math_workshop_evidence/を残す。
必修ルート、拡張、深掘り
Section titled “必修ルート、拡張、深掘り”| 層 | いま学ぶこと | どう使うか |
|---|---|---|
| 必修コア | ベクトル類似度、行列 shape、確率の直感、loss、勾配降下 | 後で特徴量、指標、embedding、検索スコア、学習更新になります |
| 任意の拡張 | 固有値、ベクトル空間、歴史と基礎 | PCA、表現の幾何、モデル史の問いが出たときに戻ります |
| 深掘り課題 | 入力、確率、loss、学習率を 1 つ変え、結果を予測してからコードを実行する | 実験前に考える習慣を作ります |
本章でよく使う用語:
| 用語 | 意味 |
|---|---|
Embedding | テキスト、画像、ユーザー、アイテムのベクトル表現 |
dot product | 2 つのベクトルの方向がどれくらい一致するか |
norm | ベクトルの長さや強さ |
entropy | 不確かさや驚き |
loss | モデルの誤りを測る数値 |
gradient | 値を最も速く変える方向 |
GD / SGD | 勾配降下 / 確率的勾配降下:損失の下り坂を進む方法 |
最初の実行ループ
Section titled “最初の実行ループ”NumPy がなければ先に入れます。
python -m pip install numpy次のスクリプトを実行します。Embedding や検索の前に、ベクトル類似度がなぜ重要かを確認します。
import numpy as np
python_topic = np.array([1.0, 1.0, 0.0])data_topic = np.array([1.0, 0.8, 0.2])unrelated_topic = np.array([0.0, 0.1, 1.0])
def cosine(a, b): return a @ b / (np.linalg.norm(a) * np.linalg.norm(b))
print("Python vs data:", round(cosine(python_topic, data_topic), 3))print("Python vs unrelated:", round(cosine(python_topic, unrelated_topic), 3))期待される出力:
Python vs data: 0.982Python vs unrelated: 0.071コードは小さいですが、この考え方は後で Embedding、検索、推薦、Attention、RAG に何度も出てきます。
この出力の読み方
Section titled “この出力の読み方”0.982は、2 つのベクトルがかなり近い方向を向いていることを示します。0.071は、無関係なベクトルが Python トピックとほぼ直交していることを示します。- これらは不思議なスコアではなく、内積をベクトル長で割った値です。
- 1 つの次元を変える前に、結果がどちらへ動くか予測してから実行します。
| レベル | 証明できること |
|---|---|
| 最低合格 | ベクトル類似度の例を実行し、各次元が何を表すか説明できる。 |
| プロジェクト利用可 | ベクトル、確率、損失、勾配を、別々の公式ではなく 1 つのモデル動作へ対応づけられる。 |
| 深い確認 | 入力や学習率を 1 つ変え、結果の変化方向を予測してからコードで確認できる。 |
このページを終えたら、この evidence card を残します。
- 概念ブリッジ
- 学習や AI アプリケーションを支える数学の考え方はどれか
- 計算
- 手計算または NumPy で確認できる小さな例
- 出力
- number、curve、vector、matrix、probability、またはgradient trace
- 失敗確認
- モデルの振る舞いを理解せずに数式だけを暗記している
- 期待される成果
- 1つの実際の AI 操作を説明する数学メモ
よくある失敗
Section titled “よくある失敗”| 症状 | 最初に確認すること | よくある修正 |
|---|---|---|
| 数式が抽象的すぎる | どのモデル動作を支えるか | 表す、比較する、不確かさを測る、損失を測る、更新する、に訳す |
| ベクトル例が任意に見える | 各次元が何を意味するか | 計算前に次元ラベルを書く |
| 確率の用語が混ざる | 何がランダムで、何がイベントか | サンプル、結果、確率を小さな表にする |
| 勾配降下が発散する | 学習率が大きすぎないか | 各ステップの loss を表示し、学習率を下げる |
| ワークショップが魔法に見える | 理論を飛ばしていないか | 先に 4.1、4.2、4.3 のロードマップを読む |
通過チェック
Section titled “通過チェック”次の 5 つに答えられたら、第 5 章へ進めます。
- 1 つのサンプルはどうやってベクトルになりますか?
- モデル出力を確率や信頼度として読めるのはなぜですか?
- loss は何を測っていますか?
- 勾配はパラメータにどちらへ動くべきかをどう伝えますか?
- 4.4 フル数学ワークショップ を実行し、生成ファイルを説明できますか?
印刷用のチェックリストが必要なときは、4.0 学習ガイドとタスクリスト を使ってください。次の章では、この数学直感を sklearn のモデル学習と評価に落とし込みます。
確認の考え方と解説
- 通過チェックでは、公式、コード、モデルの挙動をつなげます。「式を知っている」で止めず、小さな計算と、それが説明する AI タスクを示します。
- ベクトルと行列では shape 確認と、類似度または変換結果を証拠にします。確率では繰り返しサンプルの推定や Bayes 更新、微積分では勾配と 1 回の更新ステップを示します。
- ある数値の意味を普通の言葉で説明できない場合は、この章を閉じずに、図か小さな NumPy 例を追加してください。