8.4.2 非同期プログラミングと並行呼び出し
LLM アプリを作るとき、最初の性能ボトルネックは、モデルが弱いことではなく、次のようなことが多いです。
システムの大部分の時間が待ち時間になっている。
API を待つ、検索を待つ、ツールを待つ、データベースを待つ。
非同期プログラミングは、こうした「CPU は忙しくないのに、タスクだけが止まっている」問題を解決するためのものです。
学習目標
- なぜ LLM アプリは自然に非同期並行に向いているのかを理解する
- 同期呼び出しと非同期呼び出しの違いを区別できるようになる
async/await/gatherの基本的な使い方を学ぶ- 並行制限とタイムアウト制御がなぜ重要かを理解する
- 実際の場面に近い非同期呼び出しの例を読めるようになる
初学者向けの用語ブリッジ
コードを読む前に、エンジニアリングでよく出てくる用語を整理しておくと理解しやすくなります。
| 用語 | この節での意味 | なぜ重要か |
|---|---|---|
I/O | Input / Output の略。ネットワーク通信、データベース検索、ファイル読み込み、API 呼び出しなど | 多くの時間は計算ではなく待ち時間に使われるため |
coroutine | await の位置で一時停止し、あとで再開できる処理 | Python がひとつの待ち処理で全体を止めず、別の処理を進められる |
scheduler | イベントループ内で、どのコルーチンを次に進めるか決める部分 | 非同期並行処理の「交通整理役」と考えると分かりやすい |
Semaphore | 同時に実行できるタスク数を制限するゲート | API、データベース、モデルサービスに負荷をかけすぎないため |
timeout | 処理を最大どれくらい待つかという上限時間 | 上流の呼び出しが止まったまま、リクエスト全体を巻き込むのを防ぐ |
最初はこう捉えると十分です。非同期コードは外部サービスそのものを速くするのではなく、待ち時間を無駄にしないための設計です。
まず全体像をつかもう
非同期プログラミングは、「どこで待つのか、並行できるのか、どこを制限する必要があるのか」という観点で理解すると分かりやすいです。
この節で本当に解決したいのは、次の2つです。
- なぜ LLM エンジニアリングの性能問題は、計算力よりも待ち時間にあることが多いのか
- なぜ非同期は魔法の高速化ではなく、待ち時間をより賢く使う方法なのか
なぜ LLM エンジニアリングは特に「待ち」が起きやすいのか?
これ以上ないほど現実的な場面
質問応答アシスタントを作ると、1回のリクエストで次の処理が必要になることがあります。
- ナレッジベースを検索する
- モデルを呼び出す
- さらにツールを1つ呼び出す
もし各ステップを順番に終わるまで待ってから次に進むと、全体の遅延はどんどん長くなります。
重要な点:多くの処理は「計算が遅い」のではなく「待ちが遅い」
たとえば次のようなものです。
- ネットワーク通信
- データベース検索
- 外部 API
こうした場面では、CPU は多くの場合、実際にはフル稼働していません。
つまり、
あるタスクを待っている間に、別のタスクを進められる
ということです。
これこそが非同期プログラミングの一番大きな価値です。
初学者向けの分かりやすい比喩
非同期プログラミングは、次のように考えるとよいです。
- お湯を沸かしながら、野菜を切る
お湯が沸くのを鍋の前でただ待っているだけだと、
その時間は無駄になってしまいます。
非同期はこう言っています。
- 待っている間に、別のタスクを進めよう
この比喩は初心者にとても向いています。なぜなら、次のことをつかみやすいからです。
- 非同期は、1つのリクエストを「強くする」ものではない
- 全体の待ち時間を「より賢く」使うもの
同期と非同期は何が違うのか?
同期:1つ終わってから次へ進む
import time
def task(name, delay):
time.sleep(delay)
return f"{name} done"
start = time.time()
print(task("A", 1))
print(task("B", 1))
print("elapsed =", round(time.time() - start, 2))
このコードは、およそ 2 秒かかります。
出力例:
A done
B done
elapsed = 2.0
非同期:送ったら、むやみに待ち続けない
import asyncio
import time
async def task(name, delay):
await asyncio.sleep(delay)
return f"{name} done"
async def main():
start = time.time()
results = await asyncio.gather(
task("A", 1),
task("B", 1)
)
print(results)
print("elapsed =", round(time.time() - start, 2))
asyncio.run(main())
この版は、通常およそ 1 秒で終わります。
出力例:
['A done', 'B done']
elapsed = 1.0
本当の違いは何か?
「非同期が特別だから」ではなく、次の違いです。
待っている間、スケジューラは立ち止まらず、別のコルーチンを進める。
async と await は何を表しているのか?
async def
これは、
これはコルーチン関数です。
という意味です。
普通の関数のようにその場で即完了するのではなく、スケジューリングして実行できます。
await
これは、
ここでは非同期結果を待つ必要があります。
という意味です。
ただし、その待ち時間のあいだ、スケジューラは別のコルーチンを処理できます。
一番イメージしやすい比喩
同期は、
- 料理中に、鍋の前でお湯が沸くのをずっと待つ
非同期は、
- お湯が沸く間に、先に野菜を切る
なぜ gather はこんなに使われるのか?
LLM の場面では「複数の路線を同時に調べる」ことが多いから
たとえば次のようなことがあります。
- 3 つの検索器を同時に呼ぶ
- 複数のモデル候補を同時にリクエストする
- いくつかのデータソースを同時に確認する
こうした場面では、asyncio.gather() がとても自然です。
LLM の場面により近い例
import asyncio
async def retrieve_docs():
await asyncio.sleep(0.3)
return ["返金ポリシー", "証明書の説明"]
async def call_model():
await asyncio.sleep(0.5)
return "モデルの初回応答"
async def fetch_user_profile():
await asyncio.sleep(0.2)
return {"user_level": "beginner"}
async def main():
docs, model_reply, profile = await asyncio.gather(
retrieve_docs(),
call_model(),
fetch_user_profile()
)
print(docs)
print(model_reply)
print(profile)
asyncio.run(main())
想定出力:
['返金ポリシー', '証明書の説明']
モデルの初回応答
{'user_level': 'beginner'}
これは、実際のアプリで「複数の情報を並行して集める」書き方にかなり近いです。
なぜ無限に並行にしてはいけないのか?
外部システムには限界があるから
1000 件のリクエストを一気に並行実行すると、次のような問題が起きることがあります。
- API のレート制限
- データベースが耐えきれない
- ファイルハンドル不足
- 上流サービスのタイムアウト
なので、非同期プログラミングは「並行数が多いほどよい」わけではありません。
正しくは、
スループットと安定性のバランスを取ること
です。
Semaphore で並行数を制限する
import asyncio
semaphore = asyncio.Semaphore(3)
async def limited_task(i):
async with semaphore:
await asyncio.sleep(0.2)
return f"task_{i}"
async def main():
results = await asyncio.gather(*(limited_task(i) for i in range(10)))
print(results)
asyncio.run(main())
想定出力:
['task_0', 'task_1', 'task_2', 'task_3', 'task_4', 'task_5', 'task_6', 'task_7', 'task_8', 'task_9']
この例の意味は次のとおりです。
- 合計 10 個のタスクを開始する
- ただし、同時に実行できるのは最大 3 個まで
初学者がまず覚えておくとよい判断表
| 現象 | まず何を検討するか |
|---|---|
| リクエストは多いが、主に I/O で詰まっている | まず並行化を考える |
| 外部サービスがレート制限を返し始めた | まず Semaphore を入れる |
| いくつかのリクエストがずっと止まる | まず timeout を入れる |
| 単一タスク自体の計算が重い | 非同期が第一選択とは限らない |
この表は初心者にとても役立ちます。
「いつ非同期を使うか」「いつ制限をかけるか」が、具体的に判断しやすくなるからです。

非同期は無限並行ではありません。図では gather が並行待ちを担当し、Semaphore が制限を担当し、timeout がリクエストの停止を防ぎます。この3つがそろって、ようやく実際の工程に近くなります。
タイムアウト制御がなぜ特に重要なのか?
一部のリクエストは「固まる」ことがあるから
実際のシステムでは、上流サービスが極端に遅いのにタイムアウト制御がないと、リクエスト全体がずっと止まってしまうことがあります。
最小限のタイムアウト例
import asyncio
async def slow_task():
await asyncio.sleep(2)
return "done"
async def main():
try:
result = await asyncio.wait_for(slow_task(), timeout=0.5)
print(result)
except asyncio.TimeoutError:
print("task timeout")
asyncio.run(main())
想定出力:
task timeout
エンジニアリングでは、これはとても重要です。
なぜなら、「無限に待つ」ことは、たいてい「明確に失敗する」ことより悪いからです。
LLM エンジニアリングでの典型的な使いどころ
検索の並行化
次を同時に検索する。
- FAQ
- ベクトル DB
- データベース
複数モデルの並行実行
たとえば次のようなものです。
- メインモデル + バックアップモデル
- 複数候補の回答を並行生成する
ツールの並行実行
たとえば Agent が同時に次を確認する場合です。
- 天気
- ユーザー状態
- 注文履歴
ログと監視の処理
一部のログ出力や通知も非同期にすると、メインのリクエストを詰まらせずに済みます。
初めて非同期をプロジェクトに入れるときの、もっとも安全な順番
一般的には、次の順番が安定しています。
- どの処理が主に I/O 待ちなのかを見つける
- その処理をまず並行化する
- その後、Semaphore で並行数を制御する
- 最後にタイムアウトと例外処理を追加する
この順番なら、最初からプロジェクト全体を無理に非同期化するより安全です。
目標が「ナレッジベース駆動の教材生成アシスタント」なら、どの処理を並行化するべきか?
この種のプロジェクトで、並行化しやすいのは「最終的な教材生成」そのものよりも、
その前にある外部待ちの処理です。
優先して並行化を考えるとよいものは、たとえば次のとおりです。
- 内部ナレッジベースを調べる
- 外部資料を補う
- ユーザープロファイルや設定を読む
- テンプレート情報を先読みする
まずはこう理解するとよいです。
並行化が最も効くのは、たいてい「コンテキスト収集」の段階です。
実際のシステムに近い小さな例
import asyncio
async def search_kb(query):
await asyncio.sleep(0.3)
return f"ナレッジベース結果: {query}"
async def get_user_status(user_id):
await asyncio.sleep(0.2)
return {"user_id": user_id, "progress": 0.15}
async def call_llm(prompt):
await asyncio.sleep(0.4)
return f"LLM 応答: {prompt}"
async def handle_request(query, user_id):
kb_result, user_status = await asyncio.gather(
search_kb(query),
get_user_status(user_id)
)
prompt = f"次の情報をもとに回答してください: {kb_result}、ユーザー状態: {user_status}"
answer = await call_llm(prompt)
return answer
print(asyncio.run(handle_request("返金ポリシーは何ですか", 1)))
想定出力:
LLM 応答: 次の情報をもとに回答してください: ナレッジベース結果: 返金ポリシーは何ですか、ユーザー状態: {'user_id': 1, 'progress': 0.15}
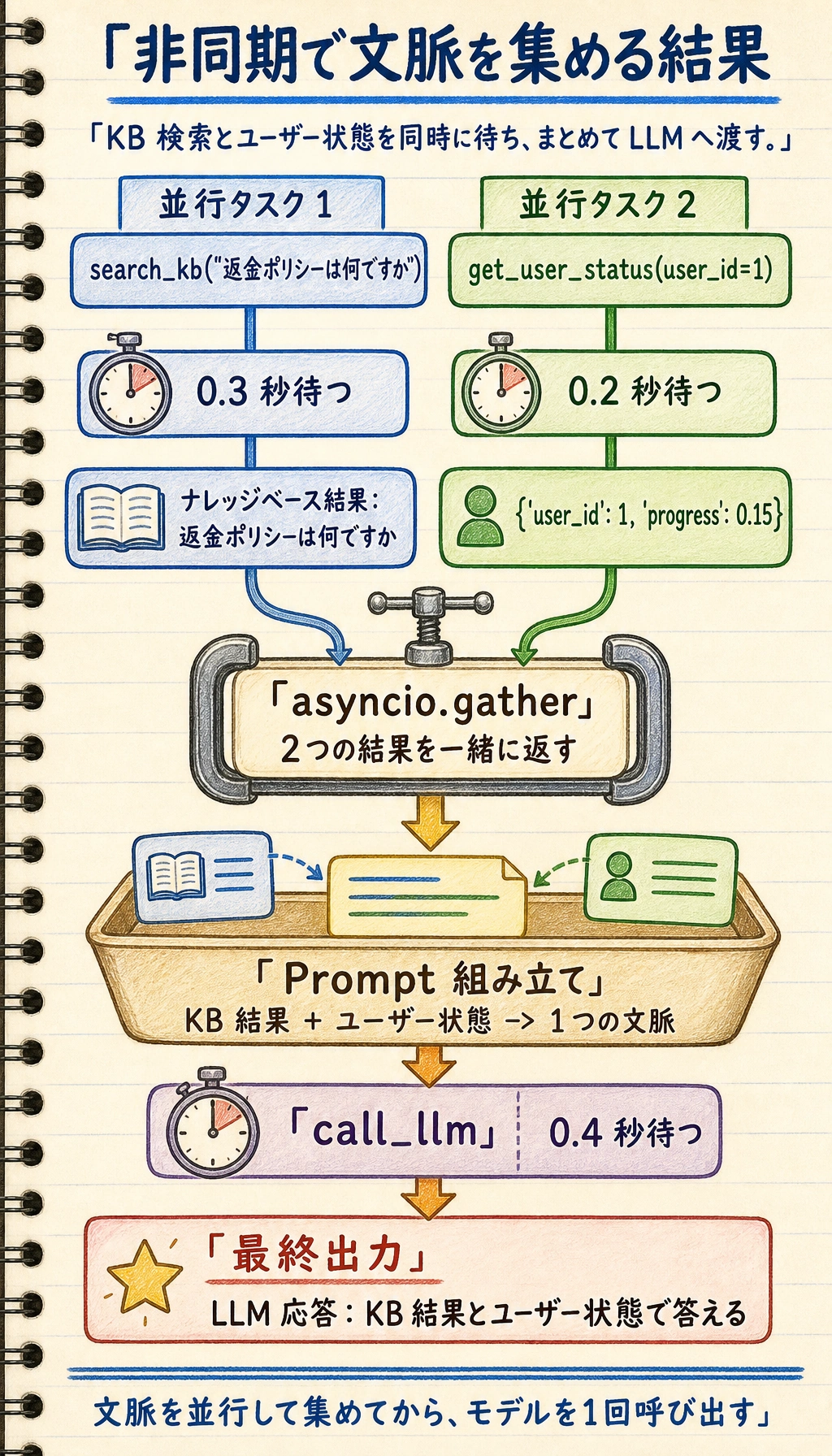
上の2本の並行レーンから下へ読みます。search_kb() と get_user_status() が同時に待ち、gather が2つの出力をまとめ、その後で call_llm() が組み立てた文脈を使います。
この例は、実際のバックエンドにかなり近いです。
- 前半でコンテキストを並行取得する
- 後半でそれをまとめてモデルに渡す
初学者がよくやるミス
非同期を「より速い同期」だと思う
非同期は高速化の魔法ではありません。
むしろ、待ち時間をより賢く使う方法です。
最初から無限に並行化する
これはシステムを壊しやすいです。
タイムアウトと例外処理を入れない
1 つのタスクが固まるだけで、リクエスト全体の流れが詰まることがあります。
これをプロジェクトやシステム設計で示すなら、何を見せるとよいか
たいてい、次のような点を見せるとよいです。
asyncioを使ったこと- どの処理を並行化したのか
- なぜそこを並行化する価値があったのか
- どのように並行制限とタイムアウトを設計したのか
- 全体の遅延をどう下げたのか
こうすると、相手に次のことが伝わりやすくなります。
- 非同期並行のエンジニアリング上の価値を理解している
- 単に構文を書けるだけではない
まとめ
この節で一番大事なのは、async / await の構文を暗記することではなく、次を理解することです。
非同期プログラミングの核心は、「待ち時間」を活用して、I/O 集中型の場面でシステムをより効率的かつ安定にすることです。
これは LLM エンジニアリングでは、ほぼ必須の基礎力です。
練習
- 本節の並行実行例で、タスク数を 10 から 30 に増やし、
Semaphoreの値を調整してみましょう。 handle_request()に、さらに1つ並行ツール呼び出しを追加してみましょう。- 考えてみましょう。なぜ非同期プログラミングは「複数の外部依存」がある LLM アプリに特に向いているのでしょうか?
- 自分の言葉で説明してみましょう。なぜ非同期プログラミングは「1つのタスクを速くする」のではなく、「全体の待ちを賢くする」のでしょうか?