11.1.2 NLP の概要
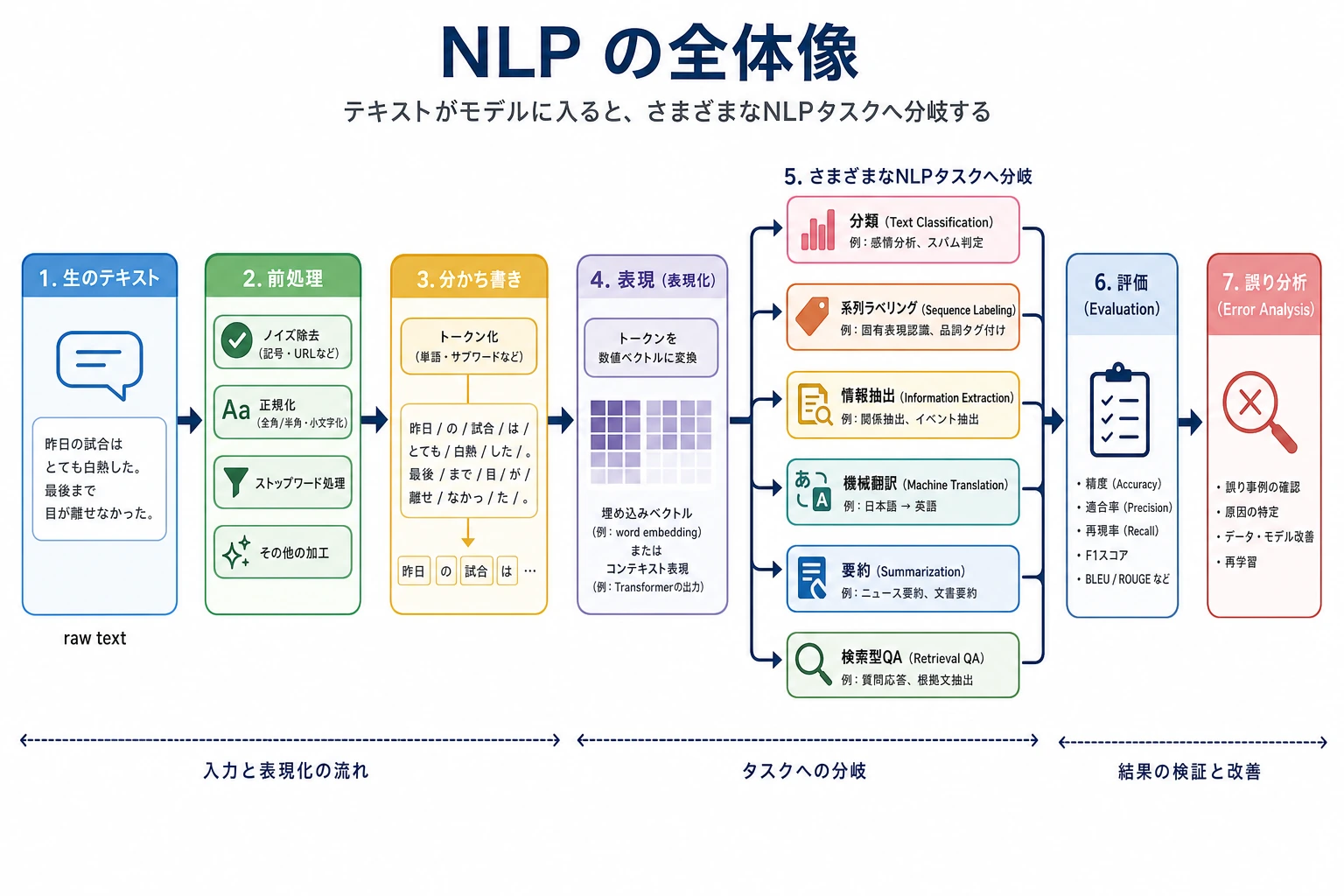
まず NLP を「テキスト -> 計算可能な構造や結果」へ変換する全体の流れとして考えましょう。同じテキストでも、分類、抽出、生成、検索質問応答など、さまざまなタスクに分かれます。後で出てくるモデルは、すべてこのタスクの境界を支えるためにあります。
学習目標
この節を終えると、次のことができるようになります。
- NLP が何を解決しようとしているのかを説明できる
- NLP でよく使われる代表的なタスクを理解できる
- 最も基本的な NLP の流れを理解できる
- なぜテキスト処理は表や画像よりも「ややこしい」のかを理解できる
- 最小例を通して「テキスト -> 構造化結果」の感覚をつかめる
一、NLP はいったい何をしているの?
NLP は Natural Language Processing の略で、日本語では自然言語処理です。
もっと簡単に言うと、
NLP とは、コンピュータに人間の言葉を処理させることです。
ここでいう「言葉」には、いろいろな形があります。
- チャットメッセージ
- コメント
- ニュース
- 契約書
- 問い合わせ票
- メール
- 検索キーワード
- 会議メモ
NLP が最終的に解決したいのは、単に「文字を認識する」ことではありません。さらに先へ進んで、
- 意味を理解する
- 情報を取り出す
- 答えを生成する
- タスクを完了する
ことを目指します。
二、NLP でよくあるタスクには何があるの?
まずは NLP のタスクを、次の 4 つの大きな種類に分けて考えるとわかりやすいです。
文全体を判断するタイプ
入力はテキスト 1 本で、出力は全体の結果です。
例えば:
- テキスト分類
「これは返金の問い合わせ? それとも請求書の問い合わせ?」 - 感情分析
「このレビューはポジティブ? ネガティブ?」
一部のフレーズを見つけるタイプ
入力はテキスト 1 本で、その中から重要な部分を出力します。
例えば:
- 固有表現抽出
「山田太郎は東京で働いている」から山田太郎と東京を抜き出す - 情報抽出
お知らせから時間、場所、人名を抜き出す
テキストからテキストへ変換するタイプ
入力テキストを受け取り、別のテキストを出力します。
例えば:
- 機械翻訳
- テキスト要約
- 言い換え
- 質問応答生成
対話型・システム型のタスク
入力は単発のテキストだけとは限らず、状態、履歴、ツールの結果なども含まれます。
例えば:
- チャットボット
- RAG 質問応答システム
- Agent
こうしたタスクでは、上の 3 つの能力を組み合わせて使います。
三、なぜテキスト処理は表データより難しいことが多いの?
テキストにはあいまいさがある
1 つの文が、複数の意味に取れることがあります。
例えば:
「このスマホは安くはないけど、カメラは本当に強い。」
「安くない」だけを見るとネガティブに見えますが、
文全体ではむしろポジティブな評価です。
テキストは文脈への依存が強い
単独では重要でない単語も、文脈に入ると意味が決まります。
例えば:
bank銀行の意味にも、川岸の意味にもなりえます
テキスト表現は統一されていない
同じ意味でも、ユーザーはたくさんの言い方をします。
例えば:
- 「返金したい」
- 「返金のやり方は?」
- 「この注文はまだキャンセルできる?」
文字面はかなり違っても、意図は近いです。
テキストはもともと非構造化データ
表データには、たいてい明確な列の意味があります。
- 年齢
- 収入
- 都市
一方でテキストは、基本的に人が自由に書いた表現です。
モデルはまず、それを計算できる形に変える必要があります。
四、NLP の典型的な処理フローはどうなっているの?
最も基本的な流れは、まず次のように理解できます。
この流れの各段階は、とても大切です。
- 前処理
汚れたテキストを、今のタスクに合う形へ整える - テキスト表現
文字を数字に変える - モデル
入力と目的の関係を学習する - 出力
ラベル、答え、要約、またはエンティティの断片にする
後で学ぶ 11 自然言語処理(方向選択)の内容の多くは、実はこの流れを土台にして広がっています。
五、まずは最小の NLP 例を動かしてみよう
次の例はとてもシンプルですが、NLP の核心となる流れをすでに全部含んでいます。
- 入力はテキスト
- 最小限の前処理をする
- ルールで意図を判定する
- 構造化された結果を出す
import re
texts = [
"今日の東京の天気を調べて",
"大阪行きのチケットを予約して",
"25 かける 4 はいくつ?",
"明日の横浜は雨が降る?",
]
def classify_intent(text):
text = re.sub(r"\s+", "", text)
if "天気" in text or "雨" in text:
return "weather_query"
if "チケット" in text or "予約" in text:
return "ticket_booking"
if "計算" in text or "かける" in text:
return "calculation"
return "unknown"
for text in texts:
print(text, "->", classify_intent(text))
実行結果の例:
今日の東京の天気を調べて -> weather_query
大阪行きのチケットを予約して -> ticket_booking
25 かける 4 はいくつ? -> calculation
明日の横浜は雨が降る? -> weather_query
出力は構造化されています。自由な文章が、それぞれタスクラベルに変換されています。後で使うモデルが強くなっても、プロジェクトにはこの明確な出力境界が必要です。
この例で本当に押さえたいことは?
この例は、NLP の最小ループがとても素朴だということを示しています。
- 入力は自然言語
- システムがその中のパターンを見つける
- 最後に構造化された結果を返す
ここではルールしか使っていませんが、これでもすでに最も基本的な NLP システムです。
六、NLP の 3 つの主要な発展ルート
ルールベースのシステム
人手でルールを書いて処理します。
メリット:
- 説明しやすい
- 小さなタスクならすぐ始められる
デメリット:
- 保守が大変
- 汎化しにくい
伝統的な機械学習
先に特徴量を作り、それを使って分類器を学習します。
例えば:
- BoW
- TF-IDF
- SVM
- ロジスティック回帰
深層学習と事前学習モデル
モデルに表現や文脈関係を直接学習させます。
例えば:
- RNN / LSTM
- Transformer
- BERT
- GPT
つまり、これから学ぶ多くの内容は、結局のところ同じ問いに答えています。
どうすれば機械は、人間の言語をより安定して処理できるようになるのか?
七、なぜ NLP は大規模モデル、RAG、Agent と強く関係するの?
大規模言語モデルも、結局はテキストを扱っているからです。
もし次のような基礎概念を知らないと、
- token
- 意味表現
- 文脈
- 分類
- 抽出
- 生成
後で LLM、RAG、Agent を学んだときに、理解が
- API を呼べる
ところで止まりやすくなります。
でも本当に大事なのは、
- それらが内部で何をしているのかを理解すること
です。
だから 11 自然言語処理(方向選択)は回り道ではなく、後ろの土台づくりなのです。
八、初心者がよくハマる誤解
NLP = チャットボット だと思ってしまう
チャットは NLP の応用の 1 つであって、すべてではありません。
前処理は細かいおまけだと思ってしまう
多くのタスクでは、前処理の質がそのまま結果の上限に効きます。
深層学習だけが NLP だと思ってしまう
ルールベースや伝統的機械学習も、中小規模の多くのタスクで今でもとても価値があります。
テキストを「読めた」なら機械もそのまま処理できると思ってしまう
機械にとっては、テキストをまず計算可能な形に変える必要があります。
まとめ
この節でいちばん覚えておきたい一文はこれです。
NLP の本質は、自然言語を計算可能で、モデル化できて、推論できる対象に変えることです。
これから先で見る内容は、次のようにつながっています。
- 前処理は「どうやってテキストを整えるか」
- テキスト表現は「どうやってテキストを数字に変えるか」
- モデルは「どうやって数字から規則を学ぶか」
この地図を先に頭の中に置いておけば、11 自然言語処理(方向選択)の後半で内容が混乱しにくくなります。
練習問題
- 自分の言葉で説明してください:なぜテキスト処理は表データより難しいことが多いのでしょうか?
- 例のルールを拡張して、
hotel_bookingの意図分類を追加してみてください。 - チャットボットは、なぜ NLP の 1 つの応用にすぎず、すべてではないのでしょうか?
- 自分がよく知っている AI 製品を 1 つ選び、裏側で使われている NLP タスクに分解できますか?