11.3.2 伝統的なテキスト分類
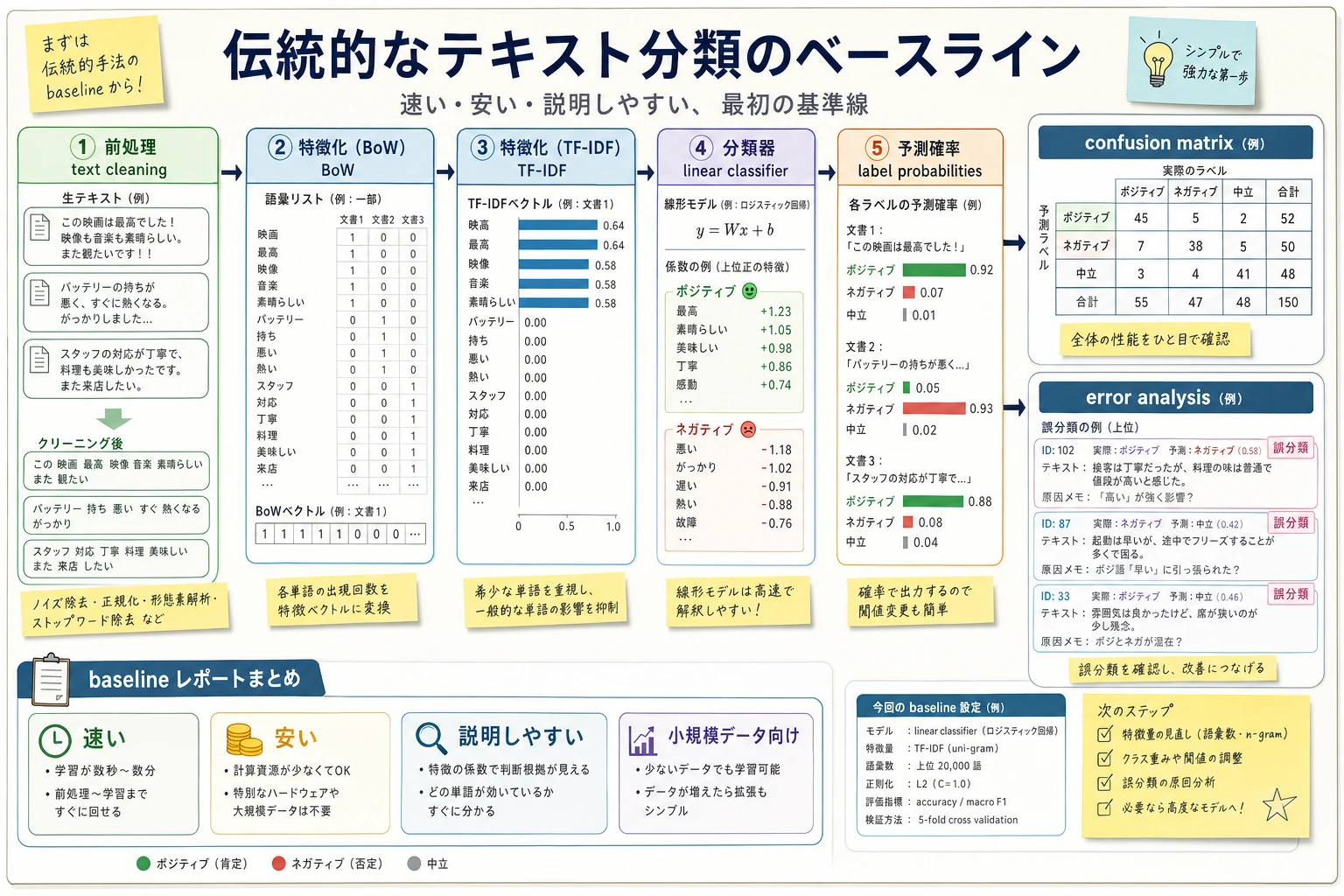
伝統的なテキスト分類は、まず「テキストの前処理 -> 特徴表現 -> 線形分類器 -> 誤り分析」の順で理解すると分かりやすいです。これは古い内容ではなく、多くのテキストプロジェクトで最も安定していて、最も速く、最も説明しやすい最初のベースラインです。
テキスト分類をするとき、多くの人は自然にこう考えます:
- いきなり大規模モデルを使う
しかし、実際の業務では従来の方法が今でもとても実用的です。特に次のような場合です:
- データ量がそれほど多くない
- ラベルがはっきりしている
- すばやく、安く、説明しやすいベースラインが必要
この節のポイントは、懐かしむことではなく、次のようなとても実用的な判断基準を作ることです:
いつ従来のテキスト分類で十分なのか、あるいはむしろそれが最初の一歩としてより良いのか。
学習目標
- BoW と TF-IDF の基本的な直感を理解する
- 線形分類器がテキストタスクでよく効く理由を理解する
- 実行できる例を通して、従来のテキスト分類の最小フローを身につける
- 「従来の方法は古い手法ではなく、強いベースラインである」という見方を身につける
まず全体像をつかもう
伝統的なテキスト分類は、次の流れで考えると理解しやすいです。「テキストをどう特徴量に変え、その特徴量をどう分類器に入れるか」という見方です。
この節で本当に解決したいのは、次のことです:
- なぜこの流れが多くの実務タスクで十分強いのか
- なぜ最初の baseline としてとても適しているのか
一、従来のテキスト分類は何をしているのか?
まずテキストを特徴量に変え、その特徴量を分類器に入れる
典型的な流れは次の通りです:
- テキストの前処理
- BoW / TF-IDF ベクトル化
- 線形モデルまたはナイーブベイズで分類
つまり、これは end-to-end の深層学習モデルではなく、
明示的な「特徴量設計 + 分類器」です。
なぜこの方法でうまくいくのか?
多くのテキストタスクでは、
単語やフレーズそのものがすでに強い区別力を持っているからです。
たとえば:
- 「返金」
- 「証明書」
- 「パスワード」
これらの単語だけで、カテゴリを強く推測できます。
たとえ話
伝統的なテキスト分類は、手作業で手がかりカードを整理するようなものです。
先にキーワードの手がかりを取り出してから、それらをもとに分類器が判断します。
初学者向けの、より分かりやすい全体イメージ
次のようにも考えられます:
- まず各テキストに「キーワード一覧」を作り、そこから分類器が点数をつける
だからこそ、この方法は次のようなタスクで特に扱いやすいです:
- カテゴリの境界がはっきりしている
- キーワード自体に強い区別力がある
二、BoW と TF-IDF はそれぞれ何をしているのか?
BoW(Bag of Words)
最もシンプルな考え方は次の通りです:
- 各単語が何回出てきたかを数える
この方法は語順をあまり気にせず、
主に次の点を見ます:
- その単語が出たかどうか
- どれくらい多く出たか
TF-IDF
TF-IDF は BoW を一歩進めたものです:
- その文書の中でよく出る単語は重要
- ただし、全体の文書でどこでもよく出る単語は重要度が下がる
これにより、次のような高頻度だけど区別力の弱い単語を減らしやすくなります:
- 「の」「です」
なぜテキスト分類でよく効くのか?
多くのカテゴリ分けは、結局のところ次のことに依存しているからです:
- どの単語がより代表的か
初学者がまず覚えるとよい選択表
| 状況 | まず試すとよい方法 |
|---|---|
| テキストが短く、キーワードがはっきりしている | まず従来の方法を試す |
| データが少ない | まず従来の方法を試す |
| 説明しやすさとコストを重視する | まず従来の方法を試す |
| 文脈や否定の関係に強く依存する | 深層学習モデルも検討する |
この表は初学者にとても便利です。なぜなら、「いつ従来の方法で十分か」を判断しやすくしてくれるからです。
三、まずは従来のテキスト分類の最小サンプルを動かしてみよう
次の例では、以下を使って:
CountVectorizerLogisticRegression
カスタマーサポートの意図分類の最小システムを作ります。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
texts = [
"返金はいつ振り込まれますか",
"返金を申請するにはどうすればいいですか",
"請求書はいつ発行できますか",
"電子請求書はどこに届きますか",
"パスワードを忘れたらどうすればいいですか",
"パスワードの再設定画面はどこですか",
]
labels = [
"refund",
"refund",
"invoice",
"invoice",
"password",
"password",
]
clf = make_pipeline(
CountVectorizer(analyzer="char"),
LogisticRegression(max_iter=200),
)
clf.fit(texts, labels)
pred = clf.predict(["返金はどう処理しますか", "電子請求書はいつ発行されますか"])
print(pred.tolist())
実行結果の例:
['refund', 'invoice']
ここでは外部分かち書きライブラリを使わずに動かせるよう、analyzer="char" を使っています。1つ目は返金に関係する文字が多く、2つ目は請求書に関係する文字が多いため、まず説明しやすい baseline になります。
このコードで一番大事なところはどこか?
大事なのは 2 つです:
CountVectorizer
テキストを計算可能な特徴量に変えるLogisticRegression
その特徴量を使って分類する
なぜこれでもう実用システムの最小構成に近いのか?
多くの軽量なオンライン分類器の本質は、次の組み合わせだからです:
- ベクトル化器
- 軽量な分類器
この組み合わせは、導入や運用のコストがかなり低いです。
TF-IDF に変えた最小例も見てみよう
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
texts = [
"返金はいつ振り込まれますか",
"返金を申請するにはどうすればいいですか",
"請求書はいつ発行できますか",
"電子請求書はどこに届きますか",
"パスワードを忘れたらどうすればいいですか",
"パスワードの再設定画面はどこですか",
]
labels = [
"refund",
"refund",
"invoice",
"invoice",
"password",
"password",
]
clf_tfidf = make_pipeline(
TfidfVectorizer(analyzer="char"),
LogisticRegression(max_iter=200),
)
clf_tfidf.fit(texts, labels)
print(clf_tfidf.predict(["パスワード再設定の入口はどこですか"]).tolist())
実行結果の例:
['password']
TF-IDF は、どのクラスにも出やすい文字の影響を下げ、パスワード や 再設定 のような区別に効く手がかりを見えやすくします。
この例は初学者に向いています。なぜなら、次のことに気づけるからです:
- 従来の方法にもいろいろな特徴表現がある
- baseline は 1 種類だけではない
四、なぜ従来の方法はよくベースラインとして優れているのか?
学習が速い
第一版の結果をすぐに得られます。
デバッグしやすい
分類を間違えたとき、次の点を追いやすいです:
- どの単語が判断に効いたのか
- 特徴量の作り方が間違っていないか
データが少ないときでも意外と悪くない
特に、ラベルの定義がはっきりしていて、テキストが短いタスクでは、
従来の方法が予想以上に強いことがよくあります。
初めてテキスト分類プロジェクトをするなら、安定した順番
より安定した順番は、たいてい次の通りです:
- まず BoW か TF-IDF の baseline を作る
- まずどのカテゴリを間違えやすいかを見る
- そのあとで、本当に深層学習モデルが必要か判断する
こうすると、最初から重いモデルを使うより、問題が見えやすくなります。
五、いつ従来の方法では足りなくなるのか?
より複雑な意味理解が必要なとき
たとえば:
- 否定
- 長距離の依存関係
- 文脈の細かい違い
語順がとても重要なとき
BoW 系の方法は語順にあまり敏感ではないからです。
多義表現や暗黙の意味が多いとき
この場合は、次のような方法がより必要になります:
- 文脈を表す表現
- 深層学習モデル
六、よくある誤解
誤解 1:従来のテキスト分類はもう学ぶ必要がない
違います。
多くの業務で、今でもとても実用的な出発点です。
誤解 2:精度が最強モデルより低いなら価値がない
実務では、次の点も重要です:
- コスト
- レイテンシ
- 説明しやすさ
誤解 3:BoW は何も理解していない
深い意味理解は苦手でも、
そもそも多くのタスクではそこまで複雑さが必要ないことも多いです。
これをプロジェクトやノートにするなら、何を見せるとよいか
一番見せる価値があるのは、たいてい次のような内容です:
- 「どの baseline を使ったか」
- 「なぜこのタスクでは従来の方法が向いているのか」
- 「どの種類のテキストでよく間違えたか」
- 「いつ、より複雑なモデルへ切り替えるべきか」
こうすると、他の人にも次のことが伝わりやすくなります:
- baseline をどう選んだかを理解している
- 単に sklearn を呼べるだけではない
まとめ
この節で最も重要なのは、次のようなエンジニアリング上の判断を持つことです:
従来のテキスト分類は「古い方法」ではなく、多くの中小規模データのタスクで、学習が速く、コストが低く、説明しやすい強いベースラインである。
この判断ができれば、今後テキスト分類プロジェクトをするときに、最初から「大規模モデル」だけに頼ることはなくなります。
練習
- 例の
CountVectorizerをTfidfVectorizerに変えて、結果がどう変わるか見てみましょう。 - 自分で
shippingのような新しいカテゴリを追加して、学習データを増やして試してみましょう。 - なぜ従来のテキスト分類は、あるタスクでは「より良い最初の一歩」だと言えるのでしょうか?
- もしタスクが語順や文脈に強く依存するなら、BoW を優先して使いますか? なぜですか?