5.3.2 聚类算法
本节概览
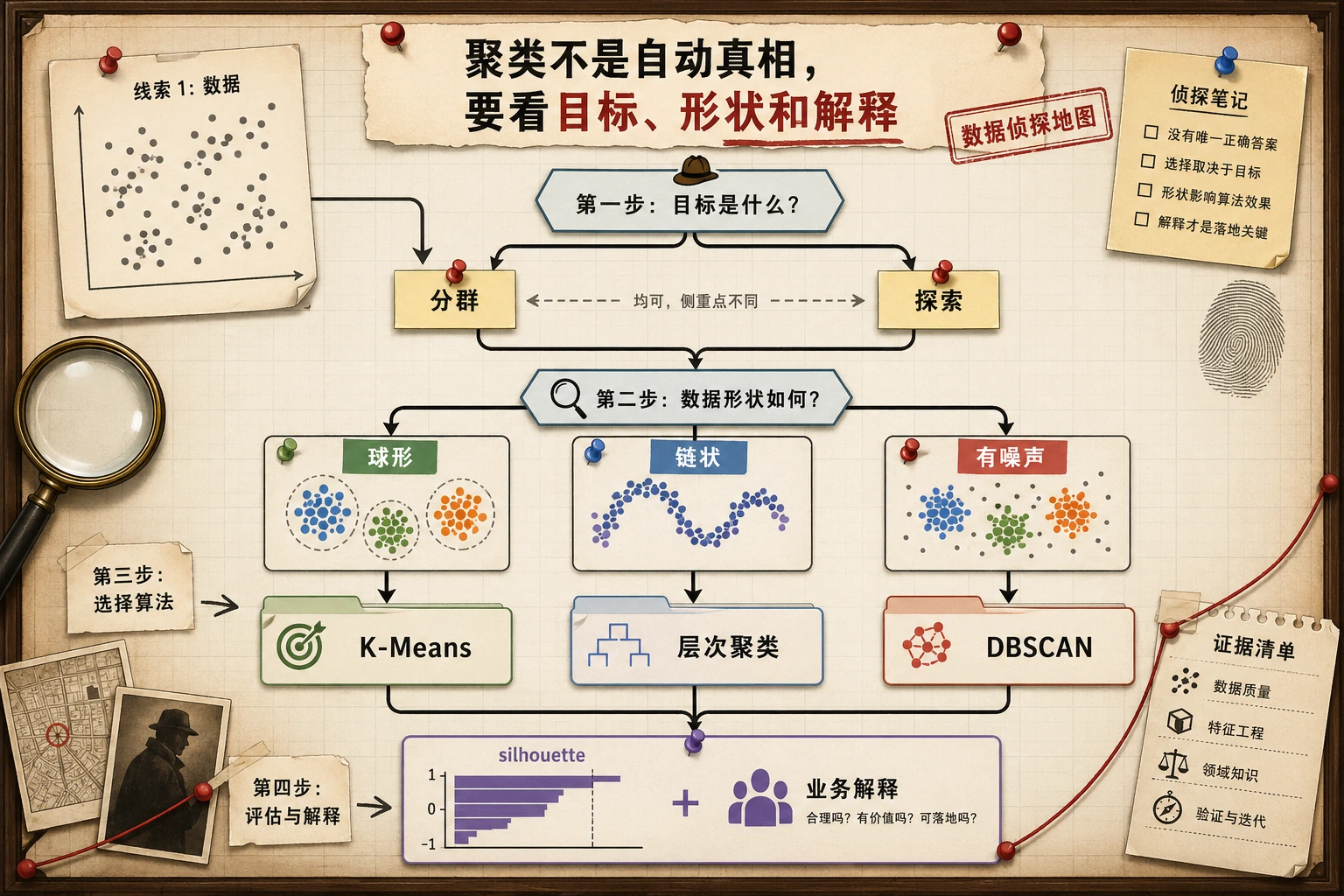
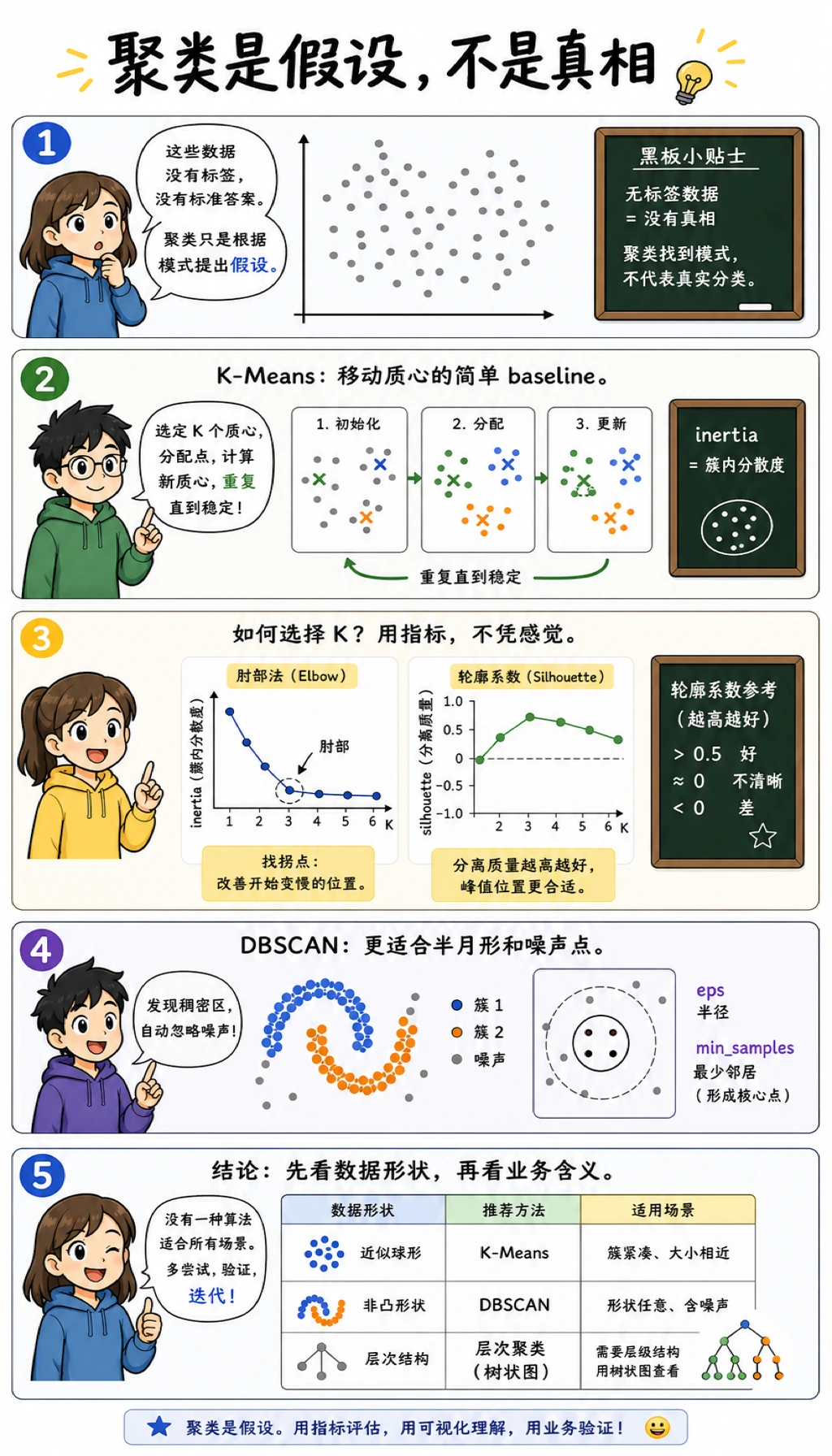
聚类是在没有标签的情况下,把相似样本分到一起。结果不是唯一真相,而是一个关于数据结构的假设,需要用指标、图形和业务含义一起验证。
你会做出什么
这一节会完成一个实用聚类实验:
- 用 inertia 和 silhouette score 选择 K-Means 的
K; - 查看 K-Means 聚类中心;
- 在弯曲数据上比较 K-Means 与 DBSCAN;
- 调整 DBSCAN 的
eps; - 运行层次聚类,作为更适合观察层级关系的替代方案。
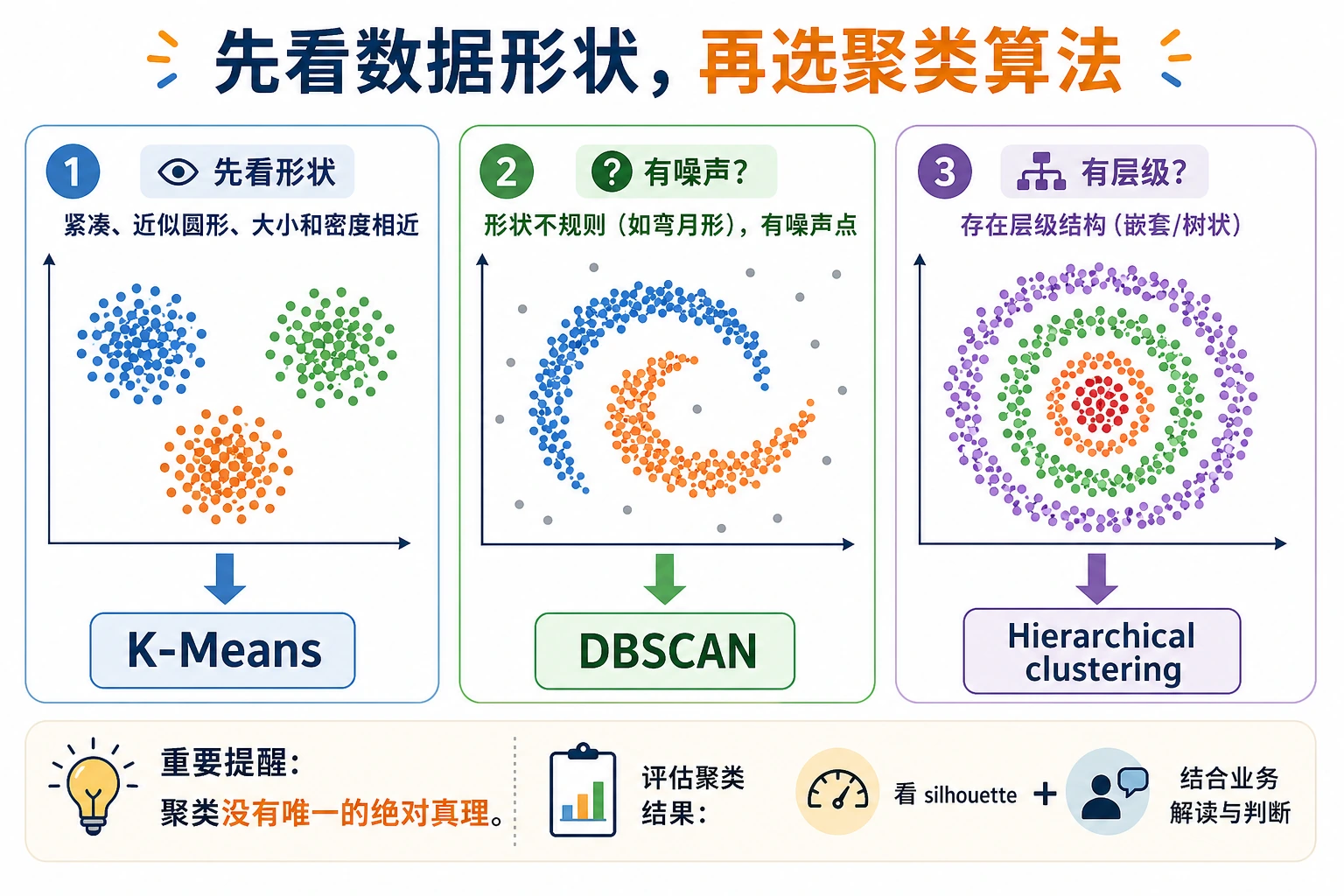
先看图。聚类的关键不是背算法名字,而是让算法假设匹配数据形状。
术语速查
| 术语 | 实用含义 |
|---|---|
cluster | 在当前特征下看起来相似的一组点 |
centroid | K-Means 聚类中心 |
inertia_ | 簇内平方距离;越低越紧凑,但随着 K 增大一定会下降 |
silhouette_score | 同时衡量紧凑度和分离度,通常越高越好 |
eps | DBSCAN 的邻域半径 |
min_samples | 成为 DBSCAN 核心点所需的最少邻居数 |
noise | DBSCAN 中的 -1 标签,表示没有分到任何密集簇 |
linkage | 层次聚类合并簇的规则 |
环境准备
python -m pip install -U scikit-learn numpy
所有示例都会先缩放特征。聚类通常依赖距离,特征尺度会直接改变“相似”的含义。
运行完整实验
新建 clustering_lab.py:
import numpy as np
from sklearn.cluster import AgglomerativeClustering, DBSCAN, KMeans
from sklearn.datasets import make_blobs, make_moons
from sklearn.metrics import adjusted_rand_score, silhouette_score
from sklearn.preprocessing import StandardScaler
# Round blob clusters: good K-Means demo.
X_blob, y_blob = make_blobs(n_samples=360, centers=3, cluster_std=0.85, random_state=42)
X_blob = StandardScaler().fit_transform(X_blob)
print("kmeans_k_selection")
for k in [2, 3, 4, 5]:
model = KMeans(n_clusters=k, n_init="auto", random_state=42)
labels = model.fit_predict(X_blob)
print(
f"k={k} inertia={model.inertia_:6.1f} "
f"silhouette={silhouette_score(X_blob, labels):.3f}"
)
best = KMeans(n_clusters=3, n_init="auto", random_state=42)
labels = best.fit_predict(X_blob)
print("kmeans_centers")
print(np.round(best.cluster_centers_, 2))
print("kmeans_ari=", round(adjusted_rand_score(y_blob, labels), 3))
# Curved clusters: DBSCAN is a better fit than K-Means.
X_moon, y_moon = make_moons(n_samples=400, noise=0.08, random_state=42)
X_moon = StandardScaler().fit_transform(X_moon)
print("shape_mismatch_lab")
kmeans = KMeans(n_clusters=2, n_init="auto", random_state=42)
km_labels = kmeans.fit_predict(X_moon)
print("kmeans_moon_ari=", round(adjusted_rand_score(y_moon, km_labels), 3))
for eps in [0.15, 0.25, 0.35]:
db = DBSCAN(eps=eps, min_samples=5)
db_labels = db.fit_predict(X_moon)
clusters = len(set(db_labels)) - (1 if -1 in db_labels else 0)
noise = int(np.sum(db_labels == -1))
print(
f"dbscan eps={eps:.2f} clusters={clusters} noise={noise} "
f"ari={adjusted_rand_score(y_moon, db_labels):.3f}"
)
print("hierarchical_lab")
agg = AgglomerativeClustering(n_clusters=3, linkage="ward")
agg_labels = agg.fit_predict(X_blob)
print("agglomerative_ari=", round(adjusted_rand_score(y_blob, agg_labels), 3))
运行:
python clustering_lab.py
预期输出:
kmeans_k_selection
k=2 inertia= 417.4 silhouette=0.527
k=3 inertia= 16.4 silhouette=0.869
k=4 inertia= 14.6 silhouette=0.690
k=5 inertia= 11.9 silhouette=0.532
kmeans_centers
[[-0.2 1.17]
[-1.09 -1.25]
[ 1.29 0.08]]
kmeans_ari= 1.0
shape_mismatch_lab
kmeans_moon_ari= 0.475
dbscan eps=0.15 clusters=12 noise=37 ari=0.312
dbscan eps=0.25 clusters=2 noise=1 ari=0.995
dbscan eps=0.35 clusters=2 noise=1 ari=0.995
hierarchical_lab
agglomerative_ari= 1.0
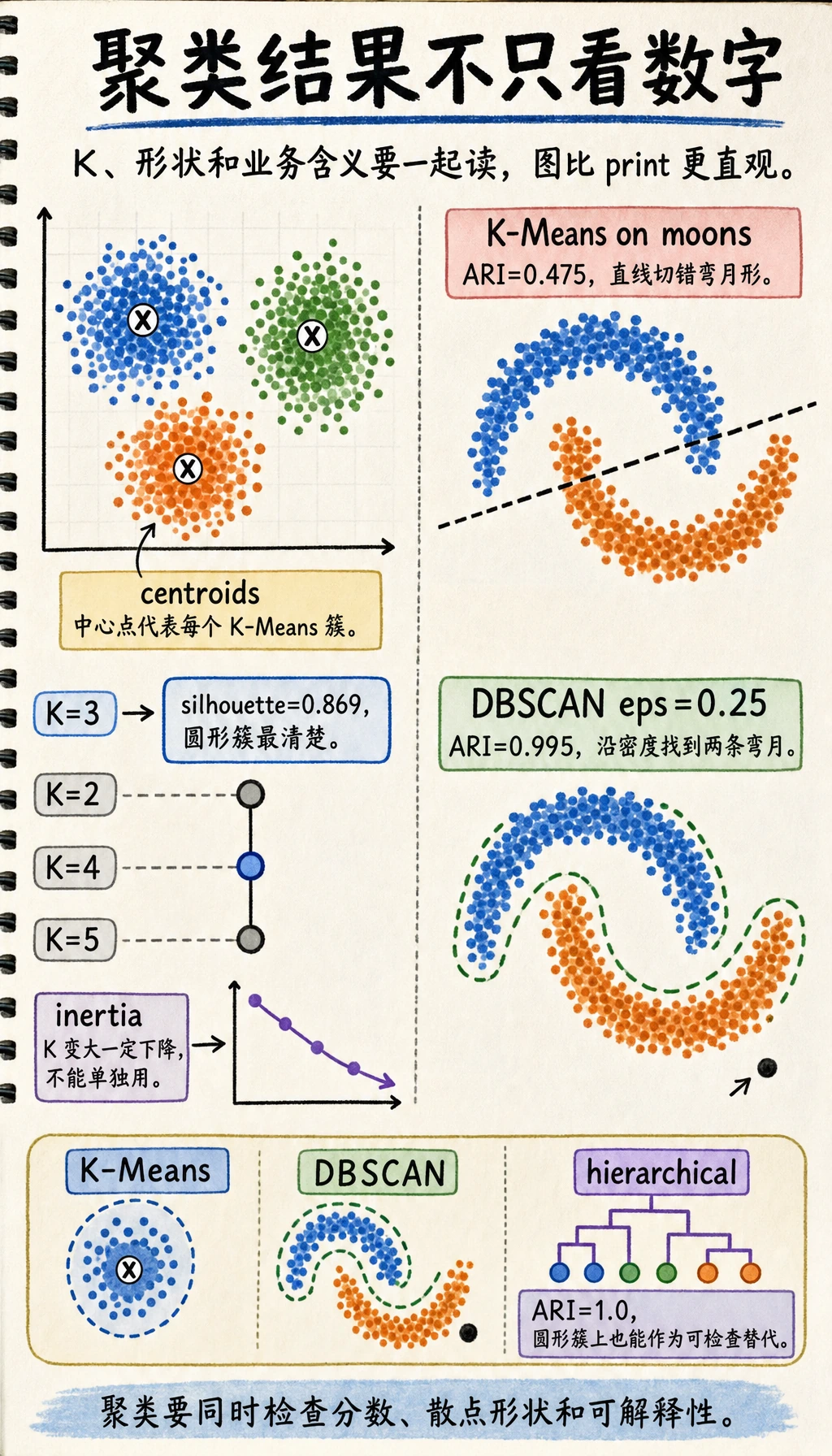
adjusted_rand_score 只在这个合成教学数据里使用隐藏标签,方便验证算法行为。真实聚类项目通常没有标签,要靠指标、可视化和业务解释判断。
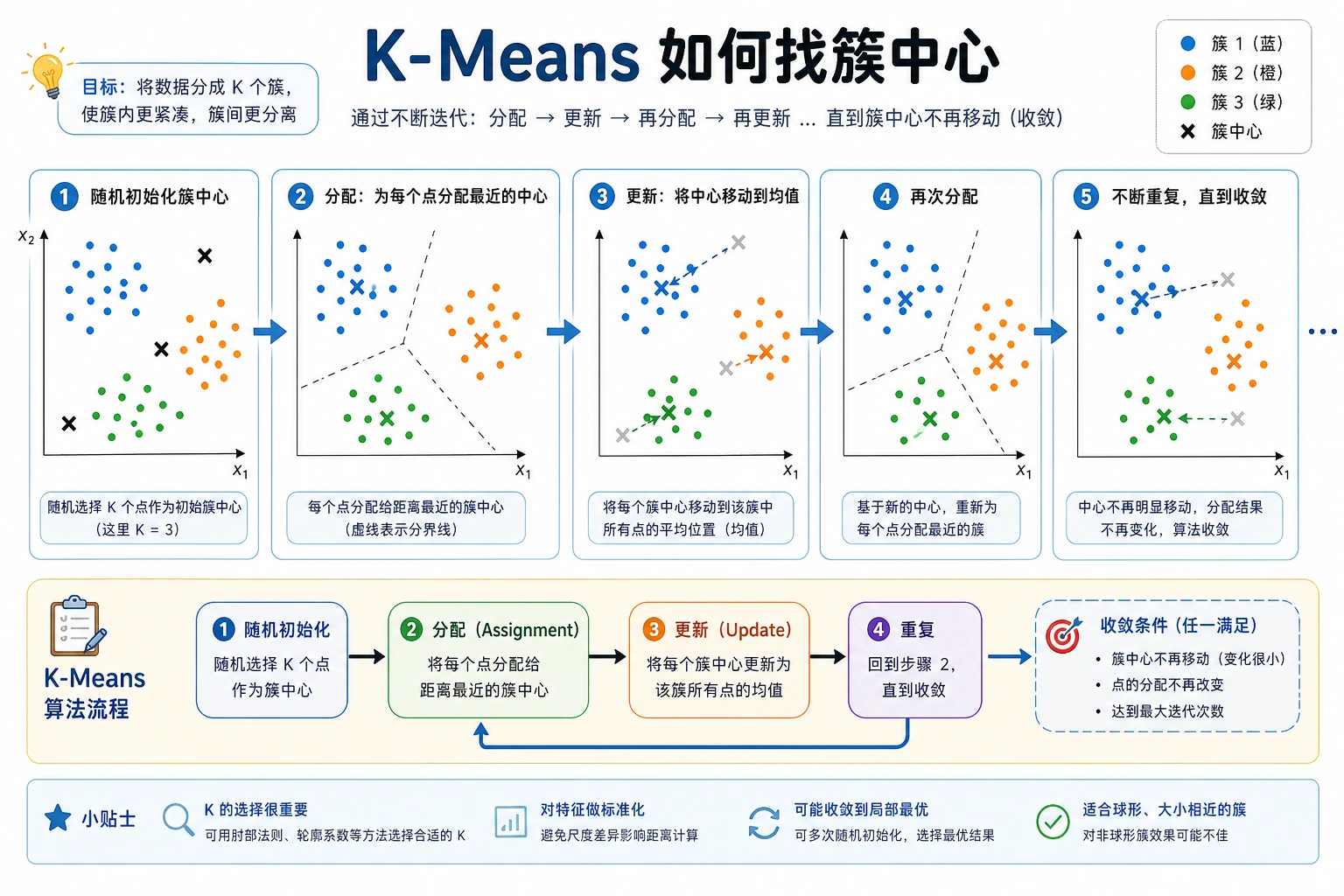
K-Means:选择 K
K-Means 重复三步:
- 放置
K个聚类中心; - 把每个点分给最近的中心;
- 把中心移动到本簇样本的平均位置。
实验比较了多个候选 K:
k=2 inertia= 417.4 silhouette=0.527
k=3 inertia= 16.4 silhouette=0.869
k=4 inertia= 14.6 silhouette=0.690
这里 K=3 是更合理的选择:
- inertia 从
K=2到K=3大幅下降; - silhouette 在
K=3最高; - 继续增加簇数会降低 inertia,但分离度变差。
不要只靠 inertia 选 K。因为 K 越大,簇越小,inertia 一定会下降。
K-Means 的假设
K-Means 更适合:
- 大致圆形的簇;
- 尺寸相近的簇;
- 通过距离能分开的簇;
- 特征尺度可比较的数据。
如果簇是弯曲、嵌套、噪声多,或者密度差异很大,K-Means 往往会吃力。
DBSCAN:寻找密集区域
DBSCAN 不要求你先给出 K。它问的是:
哪些点在半径
eps内有足够多邻居?
所以它适合弯曲形状和带噪声的数据。实验展示了形状不匹配:
kmeans_moon_ari= 0.475
dbscan eps=0.25 clusters=2 noise=1 ari=0.995
K-Means 会把月牙形数据硬切成基于距离的区域。DBSCAN 沿着密集曲线寻找簇,因此能恢复两个弯月形结构。
关键参数是 eps:
dbscan eps=0.15 clusters=12 noise=37
dbscan eps=0.25 clusters=2 noise=1
eps 太小,一个真实簇会被切成很多小块;eps 太大,又可能把多个簇合并。
层次聚类
层次聚类会不断合并相近的组。当你想观察嵌套关系,或者想在完整脚本之外画 dendrogram 时,它很有用。
实验里:
agglomerative_ari= 1.0
linkage="ward" 在圆形 blob 数据上效果很好,因为它偏好紧凑的簇。面对非圆形结构时,它不一定够用。
算法选择
| 数据形状 / 目标 | 优先尝试 | 原因 |
|---|---|---|
| 圆形、紧凑的簇 | K-Means | 快、简单、强基线 |
不知道 K,有噪声和弯曲形状 | DBSCAN | 能标记噪声,也能跟随密集区域 |
| 需要观察层级关系 | Agglomerative clustering | 能展示合并结构 |
| 高维 embedding | K-Means 或 HDBSCAN 类工具 | 需要结合可视化和检索检查 |
| 业务分群 | K-Means 基线 + 领域复核 | 分群必须可行动,不只是图好看 |
给有经验的读者:聚类应当按工作流评估,而不是只看一个算法分数。需要检查重采样、特征变化、缩放方式和随机种子下的稳定性。
常见排查清单
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| K-Means 结果变化很大 | 初始化不稳定 | 使用 n_init="auto",尝试多个随机种子 |
| inertia 看起来 K 越大越好 | inertia 必然随 K 增大下降 | 同时看 silhouette 和业务可解释性 |
| DBSCAN 几乎全是 noise | eps 太小,或特征没缩放 | 缩放特征,增大 eps |
| DBSCAN 只给出一个巨大簇 | eps 太大 | 减小 eps |
| 聚类图很好看但没用 | 特征和行动无关 | 先定义每个簇会改变什么产品动作 |
练习
- 把
make_blobs()的cluster_std从0.85改成1.5。silhouette 怎么变? - 给 K-Means 循环加入
K=6。inertia 是否提升?silhouette 呢? - 把 DBSCAN 的
min_samples改成10。noise 数量怎么变? - 换成客户数据。先缩放数值特征,再用自然语言解释每个簇。
- 用不同随机种子重复聚类。分群是否稳定到可以相信?
过关检查
你能解释下面几点,就完成本节:
- 聚类产生的是假设,不是保证正确的真相;
- K-Means 是圆形、紧凑分群的强基线;
- inertia 不能单独决定
K; - DBSCAN 适合密集弯曲形状和噪声;
- 最终簇名称必须能被真实业务含义验证。