5.3.2 クラスタリングアルゴリズム
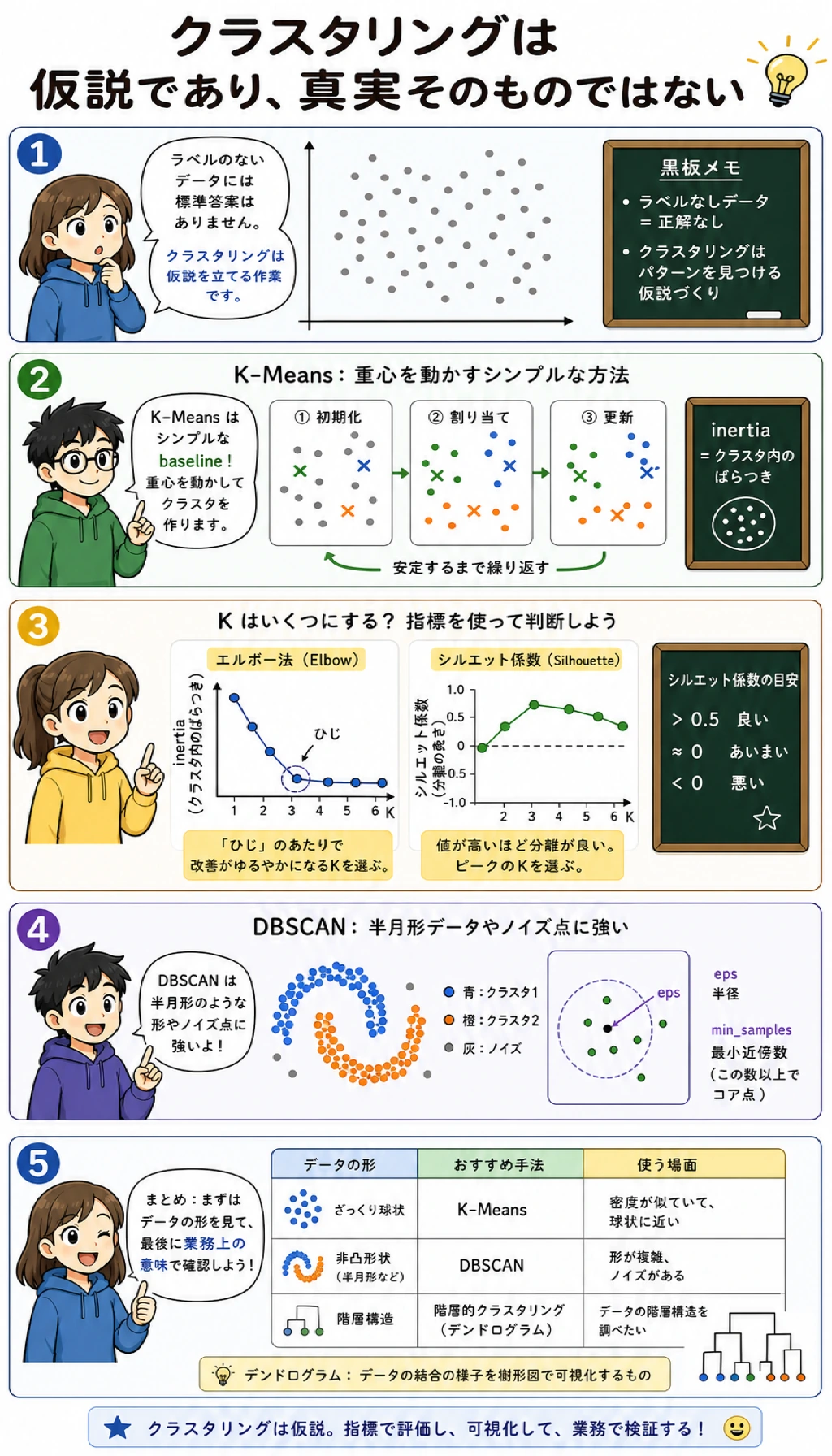
クラスタリングは、ラベルがない状態で似たサンプルをまとめる方法です。結果は唯一の正解ではなく、データ構造に関する仮説です。指標、図、ドメイン上の意味で確認する必要があります。
作るもの
この節では、実用的なクラスタリング実験を 1 つ完成させます。
- inertia と silhouette score で K-Means の
Kを選ぶ; - K-Means のクラスタ中心を確認する;
- 曲がったデータで K-Means と DBSCAN を比較する;
- DBSCAN の
epsを調整する; - 階層的クラスタリングを、構造を見やすい別案として実行する。
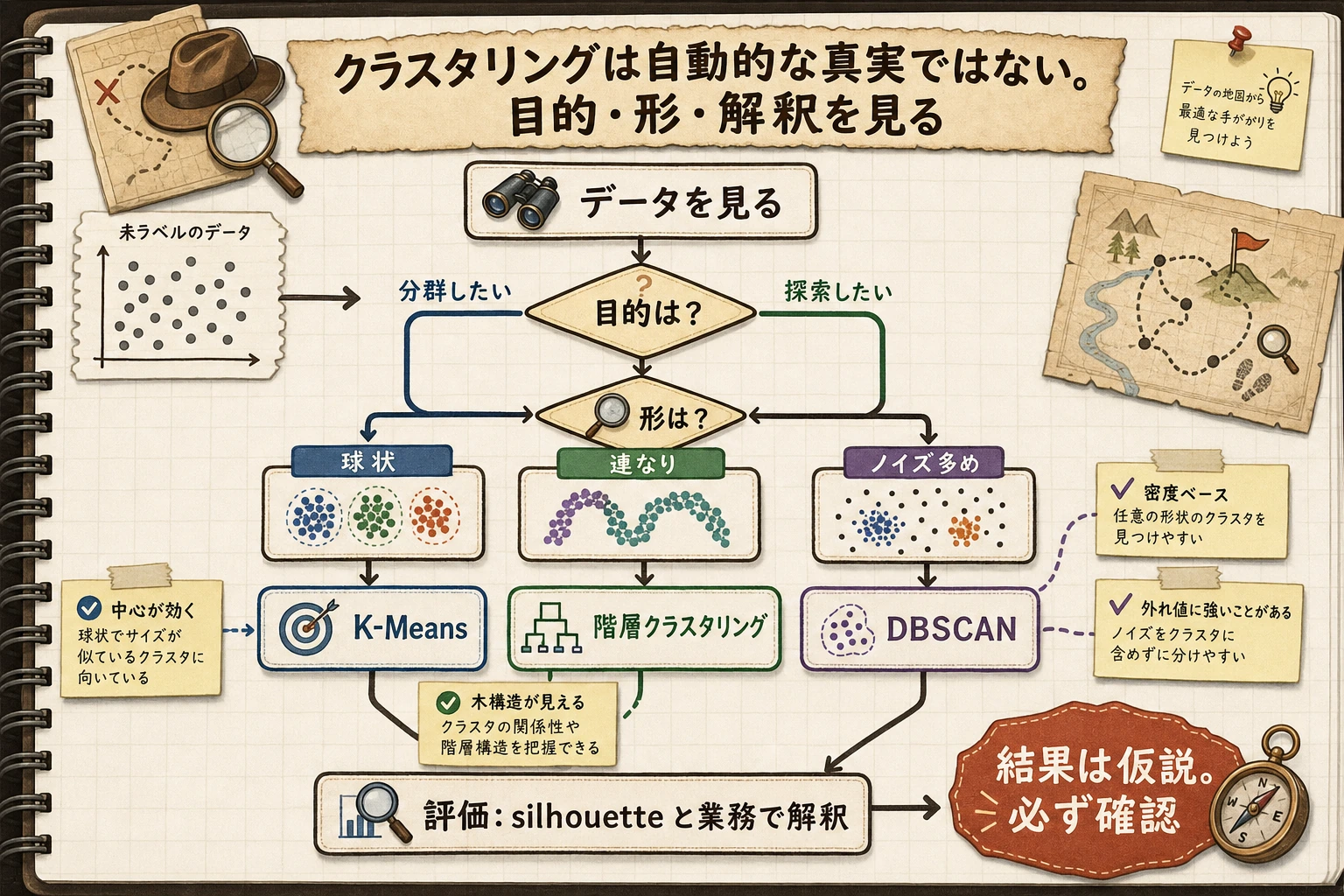
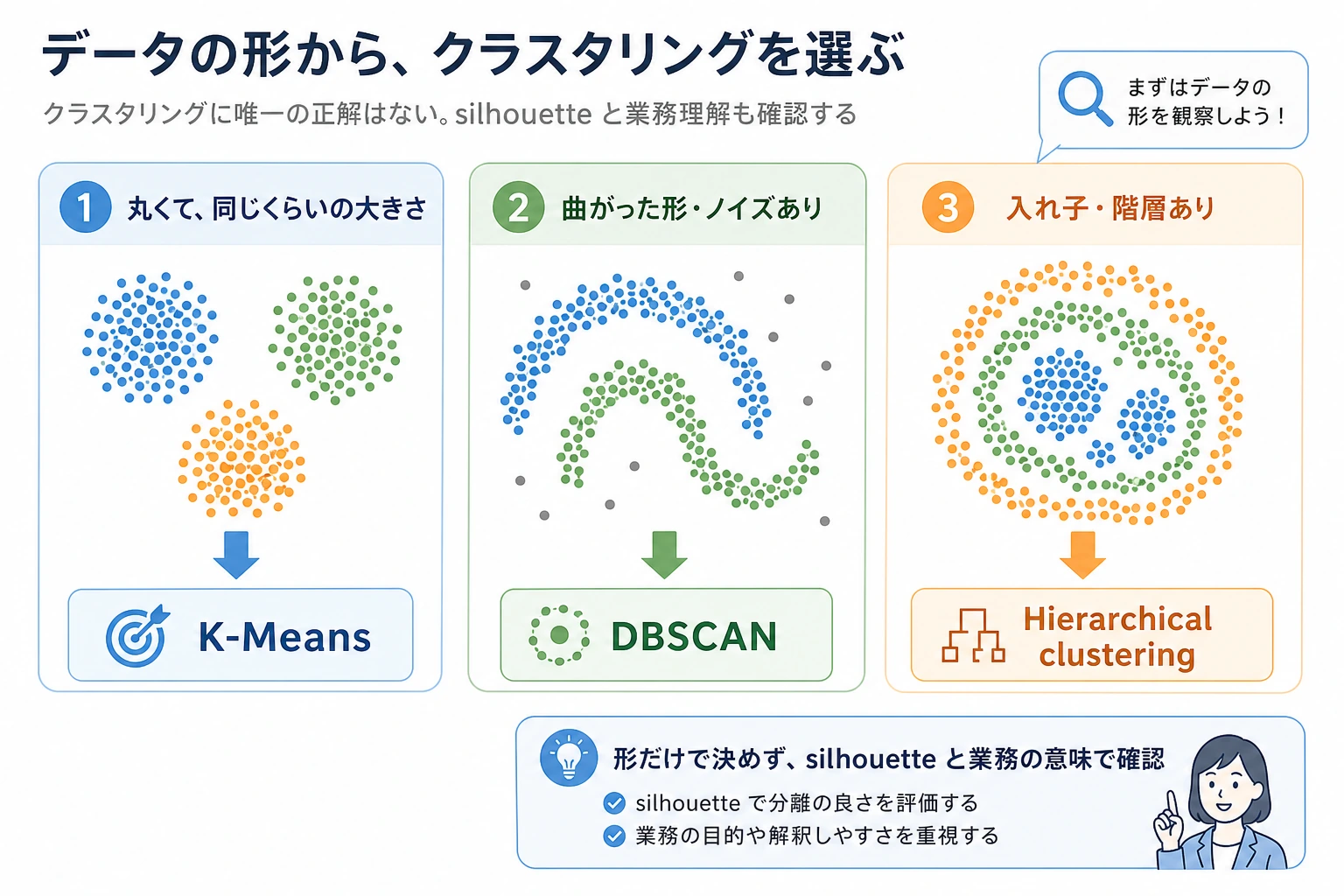
まず図を見てください。クラスタリングの要点は、アルゴリズム名を暗記することではなく、アルゴリズムの仮定をデータ形状に合わせることです。
用語早見表
| 用語 | 実用上の意味 |
|---|---|
cluster | 選んだ特徴量のもとで似て見える点のグループ |
centroid | K-Means のクラスタ中心 |
inertia_ | クラスタ内の二乗距離。低いほどまとまるが、K を増やすと必ず下がる |
silhouette_score | まとまりと分離の両方を見る指標。通常は高いほど良い |
eps | DBSCAN の近傍半径 |
min_samples | DBSCAN のコア点になるために必要な近傍点数 |
noise | DBSCAN のラベル -1。密なクラスタに入らなかった点 |
linkage | 階層的クラスタリングでグループを結合する規則 |
セットアップ
python -m pip install -U scikit-learn numpy
すべての例で特徴量をスケーリングします。クラスタリングは距離に依存することが多く、特徴量の尺度が「似ている」の意味を変えてしまうからです。
完全な実験を実行する
clustering_lab.py を作成します。
import numpy as np
from sklearn.cluster import AgglomerativeClustering, DBSCAN, KMeans
from sklearn.datasets import make_blobs, make_moons
from sklearn.metrics import adjusted_rand_score, silhouette_score
from sklearn.preprocessing import StandardScaler
# Round blob clusters: good K-Means demo.
X_blob, y_blob = make_blobs(n_samples=360, centers=3, cluster_std=0.85, random_state=42)
X_blob = StandardScaler().fit_transform(X_blob)
print("kmeans_k_selection")
for k in [2, 3, 4, 5]:
model = KMeans(n_clusters=k, n_init="auto", random_state=42)
labels = model.fit_predict(X_blob)
print(
f"k={k} inertia={model.inertia_:6.1f} "
f"silhouette={silhouette_score(X_blob, labels):.3f}"
)
best = KMeans(n_clusters=3, n_init="auto", random_state=42)
labels = best.fit_predict(X_blob)
print("kmeans_centers")
print(np.round(best.cluster_centers_, 2))
print("kmeans_ari=", round(adjusted_rand_score(y_blob, labels), 3))
# Curved clusters: DBSCAN is a better fit than K-Means.
X_moon, y_moon = make_moons(n_samples=400, noise=0.08, random_state=42)
X_moon = StandardScaler().fit_transform(X_moon)
print("shape_mismatch_lab")
kmeans = KMeans(n_clusters=2, n_init="auto", random_state=42)
km_labels = kmeans.fit_predict(X_moon)
print("kmeans_moon_ari=", round(adjusted_rand_score(y_moon, km_labels), 3))
for eps in [0.15, 0.25, 0.35]:
db = DBSCAN(eps=eps, min_samples=5)
db_labels = db.fit_predict(X_moon)
clusters = len(set(db_labels)) - (1 if -1 in db_labels else 0)
noise = int(np.sum(db_labels == -1))
print(
f"dbscan eps={eps:.2f} clusters={clusters} noise={noise} "
f"ari={adjusted_rand_score(y_moon, db_labels):.3f}"
)
print("hierarchical_lab")
agg = AgglomerativeClustering(n_clusters=3, linkage="ward")
agg_labels = agg.fit_predict(X_blob)
print("agglomerative_ari=", round(adjusted_rand_score(y_blob, agg_labels), 3))
実行します。
python clustering_lab.py
期待される出力:
kmeans_k_selection
k=2 inertia= 417.4 silhouette=0.527
k=3 inertia= 16.4 silhouette=0.869
k=4 inertia= 14.6 silhouette=0.690
k=5 inertia= 11.9 silhouette=0.532
kmeans_centers
[[-0.2 1.17]
[-1.09 -1.25]
[ 1.29 0.08]]
kmeans_ari= 1.0
shape_mismatch_lab
kmeans_moon_ari= 0.475
dbscan eps=0.15 clusters=12 noise=37 ari=0.312
dbscan eps=0.25 clusters=2 noise=1 ari=0.995
dbscan eps=0.35 clusters=2 noise=1 ari=0.995
hierarchical_lab
agglomerative_ari= 1.0

adjusted_rand_score は、この合成データに隠れたラベルがあるから使っています。実際のクラスタリングでは普通ラベルがないため、指標、可視化、業務上の解釈で判断します。
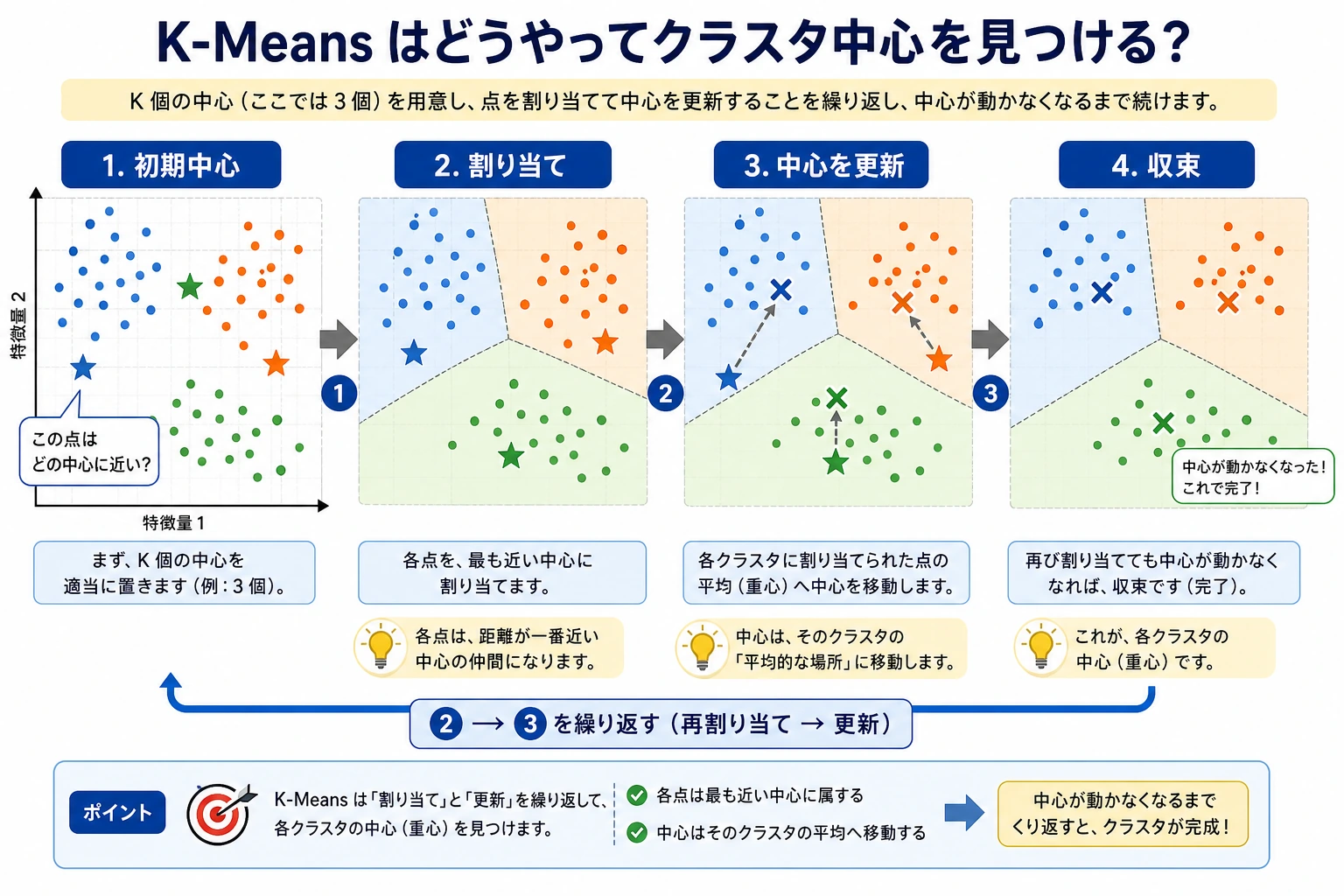
K-Means:K を選ぶ
K-Means は 3 ステップを繰り返します。
K個のクラスタ中心を置く。- 各点を最も近い中心に割り当てる。
- 各中心を、そのクラスタに属する点の平均へ動かす。
実験では複数の K を比較しています。
k=2 inertia= 417.4 silhouette=0.527
k=3 inertia= 16.4 silhouette=0.869
k=4 inertia= 14.6 silhouette=0.690
ここでは K=3 が実用的に最も良い選択です。
- inertia は
K=2からK=3で大きく下がる; - silhouette は
K=3が最も高い; - さらにクラスタ数を増やすと inertia は下がるが、分離は悪くなる。
inertia だけで K を選ばないでください。K が増えるほど小さなグループを作れるので、inertia は必ず改善します。
K-Means の仮定
K-Means が得意なのは次のような場合です。
- だいたい丸いクラスタ;
- 似た大きさのクラスタ;
- 距離で分けやすいクラスタ;
- 特徴量の尺度がそろっているデータ。
曲がった形、入れ子構造、ノイズが多いデータ、密度が大きく違うデータでは苦戦します。
DBSCAN:密な領域を探す
DBSCAN は先に K を求めません。代わりにこう問いかけます。
半径
epsの中に十分な近傍点を持つ点はどれか?
そのため、曲がった形やノイズのあるデータに向いています。実験では形状のミスマッチが見えます。
kmeans_moon_ari= 0.475
dbscan eps=0.25 clusters=2 noise=1 ari=0.995
K-Means は月形データを距離ベースの領域として無理に切ります。DBSCAN は密な曲線をたどるため、2 つの月形構造を復元できます。
重要なパラメータは eps です。
dbscan eps=0.15 clusters=12 noise=37
dbscan eps=0.25 clusters=2 noise=1
eps が小さすぎると、本来 1 つのクラスタが細かく割れます。大きすぎると、複数のクラスタが結合されます。
階層的クラスタリング
階層的クラスタリングは、近いグループを繰り返し結合します。入れ子構造を見たいとき、またはこの最小スクリプトの外で dendrogram を描きたいときに便利です。
実験では:
agglomerative_ari= 1.0
linkage="ward" はコンパクトなクラスタを好むため、丸い blob データではうまく動きます。非円形構造では、それだけでは不十分な場合があります。
アルゴリズム選択
| データ形状 / 目的 | 最初に試すもの | 理由 |
|---|---|---|
| 丸くてコンパクトなグループ | K-Means | 高速、単純、強いベースライン |
K が不明で、ノイズや曲線がある | DBSCAN | ノイズを分け、密な領域をたどれる |
| 階層関係を見たい | Agglomerative clustering | 結合構造を見られる |
| 高次元 embedding | K-Means または HDBSCAN 系 | 可視化と検索チェックを合わせて見る |
| ビジネスセグメント | K-Means 基線 + ドメインレビュー | 見た目ではなく、行動に結びつく必要がある |
経験者向け:クラスタリングはアルゴリズム単体の点数ではなく、ワークフローとして評価します。再サンプリング、特徴量変更、スケーリング、乱数シードに対する安定性も確認してください。
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| K-Means の結果が大きく変わる | 初期化が不安定 | n_init="auto" を使い、複数 seed で確認する |
| inertia では K が大きいほど良く見える | inertia は K が増えると必ず下がる | silhouette と業務解釈も見る |
| DBSCAN がほぼ noise になる | eps が小さい、または未スケーリング | 特徴量をスケーリングし、eps を上げる |
| DBSCAN が巨大な 1 クラスタだけ返す | eps が大きい | eps を下げる |
| クラスタ図はきれいだが使えない | 特徴量が行動につながらない | 各クラスタがプロダクト上何を変えるか先に決める |
練習
make_blobs()のcluster_stdを0.85から1.5に変えてください。silhouette はどう変わりますか?- K-Means のループに
K=6を追加してください。inertia は良くなりますか?silhouette はどうですか? - DBSCAN の
min_samplesを10に変えてください。noise の数はどう変わりますか? - 顧客データに置き換えてください。数値特徴量をスケーリングし、各クラスタを自然な言葉で説明してください。
- 異なる乱数 seed で同じクラスタリングを繰り返してください。信頼できるほど安定していますか?
合格チェック
次を説明できれば、この節はクリアです。
- クラスタリングは仮説を作るのであって、保証された真実ではない;
- K-Means は丸くコンパクトなグループの強いベースライン;
- inertia だけで
Kを決めてはいけない; - DBSCAN は密な曲線形状とノイズに強い;
- 最終的なクラスタ名は、現実の意味で検証される必要がある。