5.4.5 超参数调优
本节概览
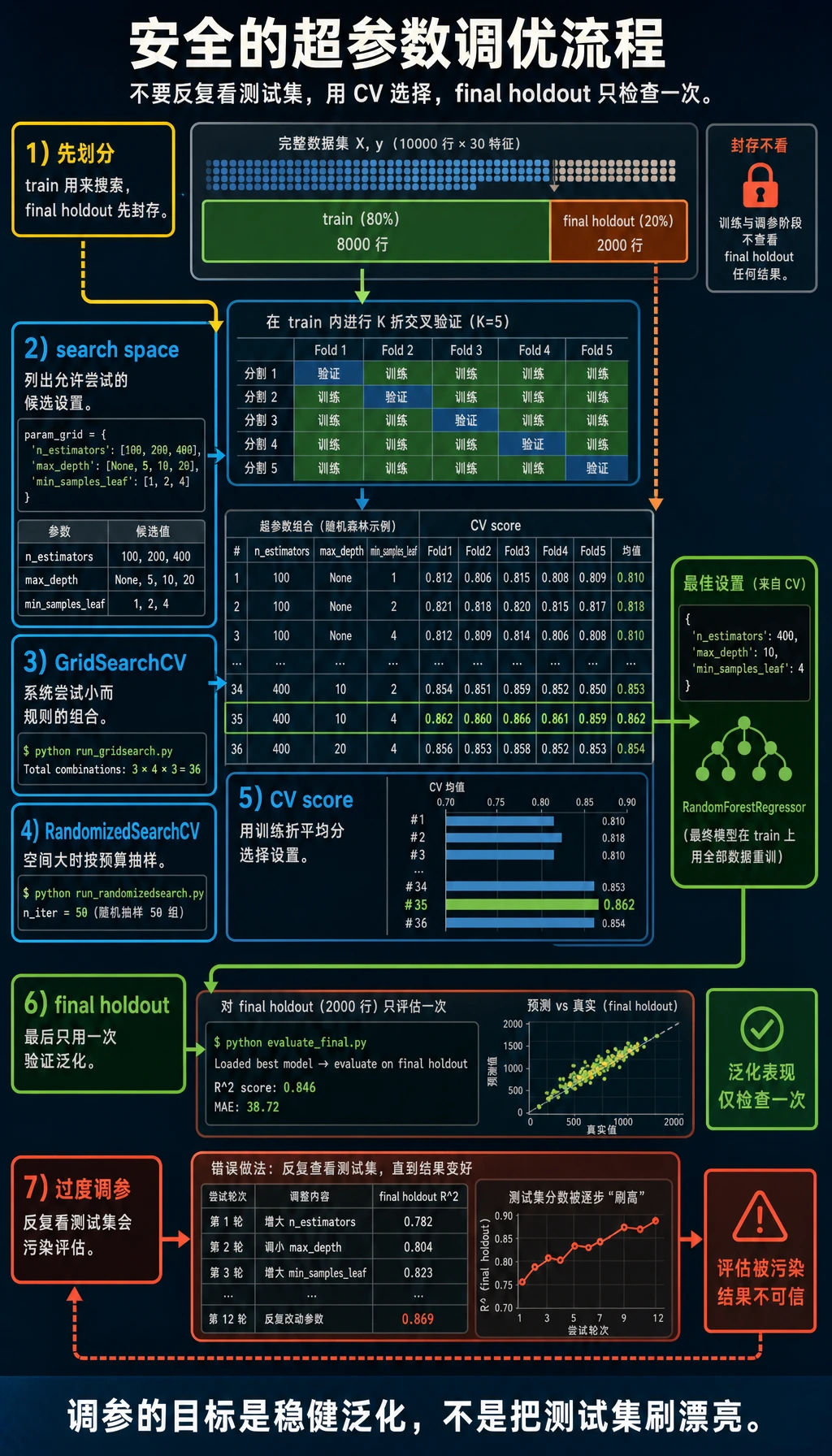
超参数调优不是“不断试设置,直到测试集分数好看”。安全流程是在训练折上搜索,用交叉验证选择参数,最后只在 final holdout 上检查一次。
你会做出什么
本节会演示:
- parameters 和 hyperparameters 的区别;
- 如何使用
GridSearchCV; - 搜索空间变大时如何使用
RandomizedSearchCV; - 如何保留最终 holdout 不参与调参;
- 如何避免过度调参。
术语速查
| 术语 | 实用含义 |
|---|---|
| parameter | 模型在 fit() 时从数据中学到的值 |
| hyperparameter | 训练前由你选择的设置,例如树深 |
| search space | 允许搜索尝试的候选值 |
| CV score | 用来选择设置的交叉验证分数 |
| final holdout | 调参后只用一次的未触碰数据 |
| budget | 你能承受的组合数或试验次数 |
环境准备
python -m pip install -U scikit-learn
运行完整实验
新建 tuning_lab.py:
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, recall_score
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV, StratifiedKFold, train_test_split
X, y = load_breast_cancer(return_X_y=True)
X_train, X_final, y_train, y_final = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
print("grid_search_lab")
grid = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid={
"n_estimators": [80, 160],
"max_depth": [3, 5, None],
"min_samples_leaf": [1, 3],
},
scoring="f1",
cv=cv,
n_jobs=-1,
)
grid.fit(X_train, y_train)
print("best_params=", grid.best_params_)
print(f"best_cv_f1={grid.best_score_:.3f}")
final_pred = grid.best_estimator_.predict(X_final)
print(
f"final accuracy={accuracy_score(y_final, final_pred):.3f} "
f"recall={recall_score(y_final, final_pred):.3f} "
f"f1={f1_score(y_final, final_pred):.3f}"
)
print("random_search_lab")
random_search = RandomizedSearchCV(
RandomForestClassifier(random_state=42),
param_distributions={
"n_estimators": [60, 100, 160, 220],
"max_depth": [3, 5, 8, None],
"min_samples_leaf": [1, 2, 3, 5],
"max_features": ["sqrt", "log2", None],
},
n_iter=8,
scoring="f1",
cv=cv,
random_state=42,
n_jobs=-1,
)
random_search.fit(X_train, y_train)
print("best_params=", random_search.best_params_)
print(f"best_cv_f1={random_search.best_score_:.3f}")
print("top_3_grid_results")
rows = sorted(
zip(grid.cv_results_["mean_test_score"], grid.cv_results_["params"]),
key=lambda item: item[0],
reverse=True,
)[:3]
for score, params in rows:
print(f"score={score:.3f} params={params}")
运行:
python tuning_lab.py
预期输出:
grid_search_lab
best_params= {'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 80}
best_cv_f1=0.968
final accuracy=0.956 recall=0.972 f1=0.966
random_search_lab
best_params= {'n_estimators': 100, 'min_samples_leaf': 1, 'max_features': 'log2', 'max_depth': 8}
best_cv_f1=0.972
top_3_grid_results
score=0.968 params={'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 80}
score=0.968 params={'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 160}
score=0.968 params={'max_depth': None, 'min_samples_leaf': 3, 'n_estimators': 160}

参数与超参数
随机森林会从数据中学习划分规则,这些学到的规则是 parameters。
你提前选择的设置包括:
n_estimators;max_depth;min_samples_leaf;max_features。
这些是 hyperparameters。它们决定模型如何学习。
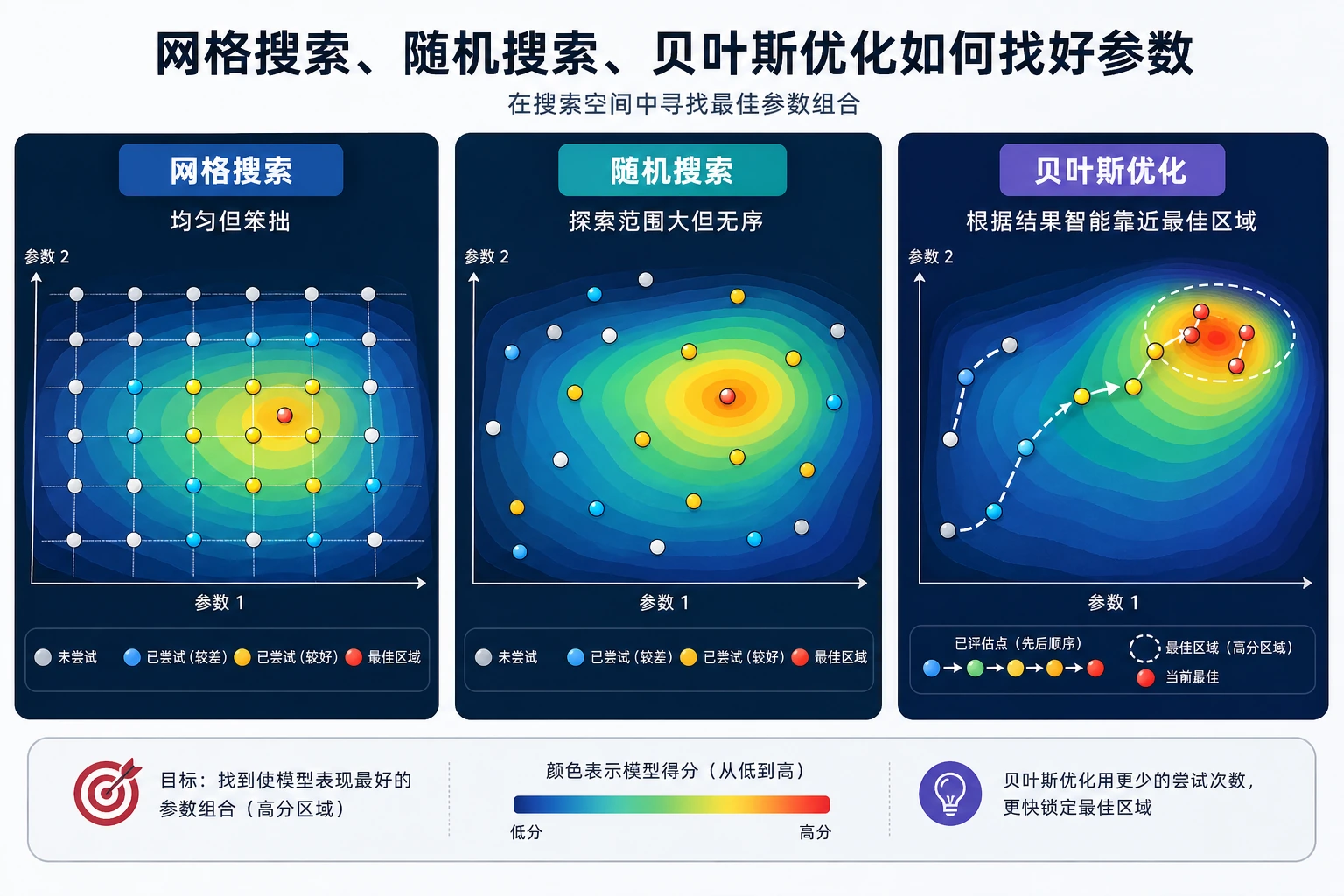
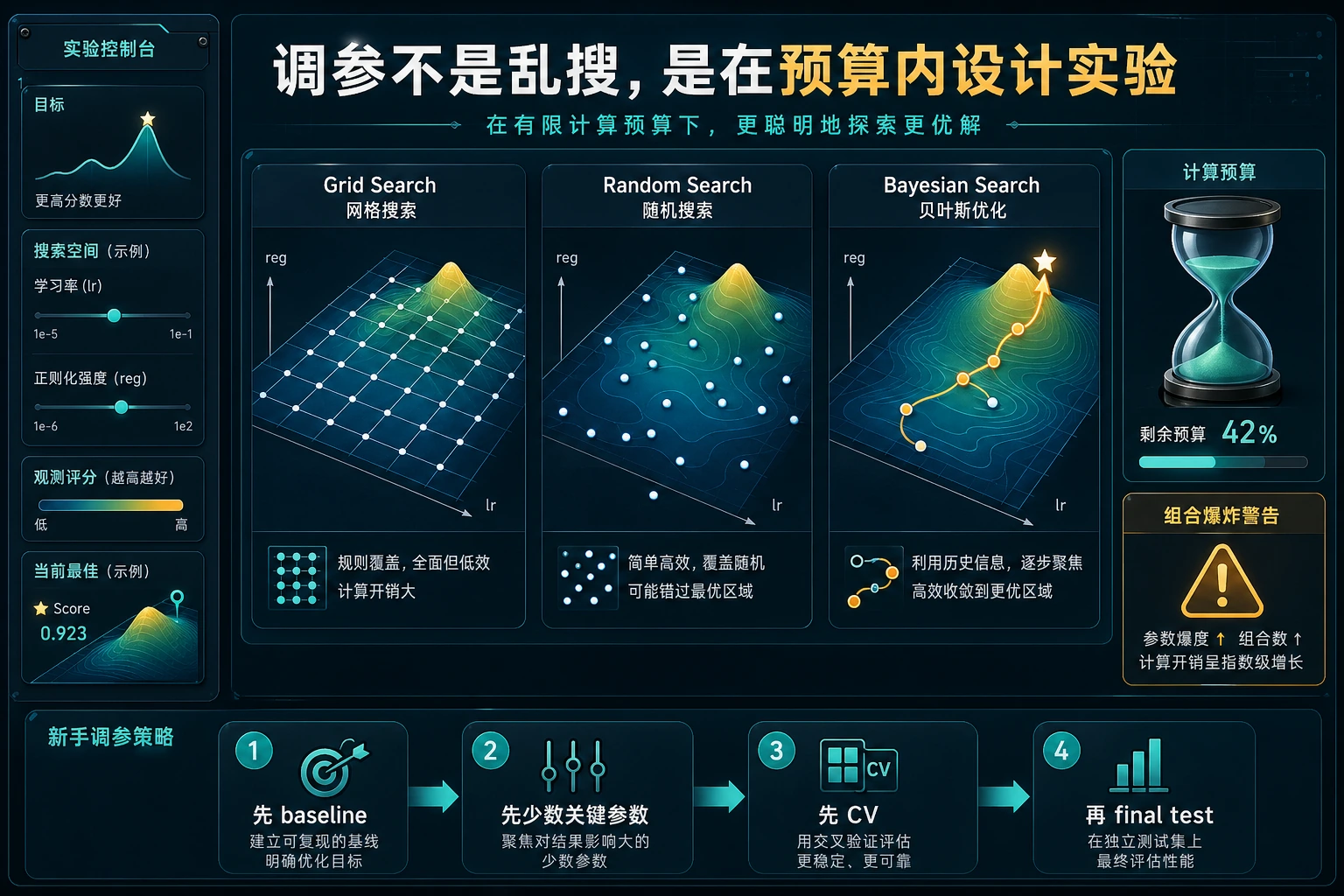
Grid Search
Grid search 会尝试你列出的每一种组合:
param_grid={
"n_estimators": [80, 160],
"max_depth": [3, 5, None],
"min_samples_leaf": [1, 3],
}
这个 grid 有 2 x 3 x 2 = 12 个组合。配合 5 折 CV,就是 60 次模型训练。
适合使用 grid search 的情况:
- 搜索空间较小;
- 你知道哪些取值大致合理;
- 想要简单、可复现的基线。
Random Search
Random search 会从更大的空间里抽取有限次数组合:
n_iter=8
实验中,它只尝试了 8 个组合,却搜索了更大的空间,并找到略高的 CV F1:
best_cv_f1=0.972
适合使用 random search 的情况:
- 超参数很多;
- 训练成本高;
- 想先探索,再设计更窄的 grid。
Final Holdout
final holdout 是没有参与 CV 搜索的数据:
X_train, X_final, y_train, y_final = train_test_split(...)
搜索选出最佳设置后,只评估一次:
final accuracy=0.956 recall=0.972 f1=0.966
看完 final holdout 后,不要继续改 grid。如果继续改,它就不再是最终 holdout,而变成调参的一部分。
读取搜索结果
grid 前几名非常接近:
score=0.968 params={'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 80}
score=0.968 params={'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 160}
分数几乎一样时,优先选择更简单或更便宜的模型。更多树、更深树并不自动更好。
实用调参策略
| 阶段 | 行动 |
|---|---|
| 起步 | 先用默认设置建立简单基线 |
| 诊断 | 检查偏差/方差和指标选择 |
| 第一次搜索 | 围绕重要参数做小 grid |
| 扩大搜索 | 组合爆炸时用 random search |
| 最终检查 | 在 untouched holdout 上评估一次 |
| 生产 | 监控漂移和重训策略 |
给有经验的读者:Optuna 这类贝叶斯优化工具适合单次试验很贵或搜索空间很大时使用,但它不能替代干净的验证设计。
常见排查清单
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| 搜索太慢 | grid 太大 | 减少候选值,改用 random search |
| CV 分数提升但 final holdout 下降 | 过度调参 | 简化搜索,保留新的 holdout |
| 最佳模型复杂很多 | 指标差异很小 | 选择更便宜/更简单模型 |
| 不同运行选出不同参数 | 数据不稳定或 fold 太小 | 使用 repeated CV 或检查方差 |
| 调参没帮助 | 模型类别或特征受限 | 先改进特征或模型家族 |
练习
- 把 scoring 从
"f1"改成"recall"。最佳参数会变吗? - 给 grid 加入
max_depth=10。CV 分数是否提升? - 把
n_iter从8改成16。提升是否值得额外成本? - 从
cv_results_打印mean_fit_time,分数接近时选择更便宜模型。 - 给前面某一节只使用 CV 的实验增加最终 untouched test set。
过关检查
你能解释下面几点,就完成本节:
- 超参数是在训练前选择的;
- grid search 会穷举小范围候选空间;
- random search 适合更大的搜索空间;
- final holdout 不能被反复用于调参;
- 调参救不了坏特征或错误验证设计。