5.4.5 ハイパーパラメータチューニング
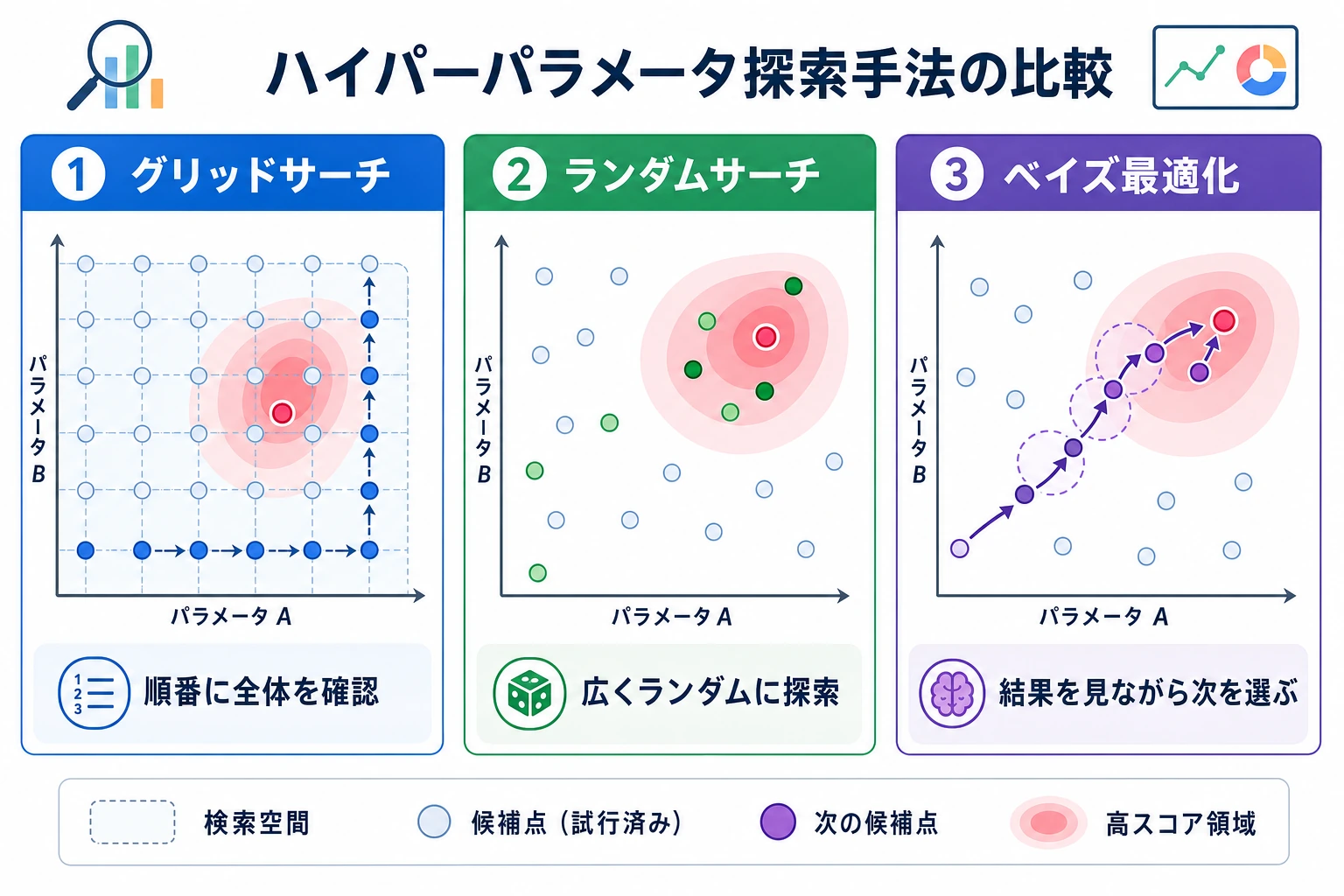
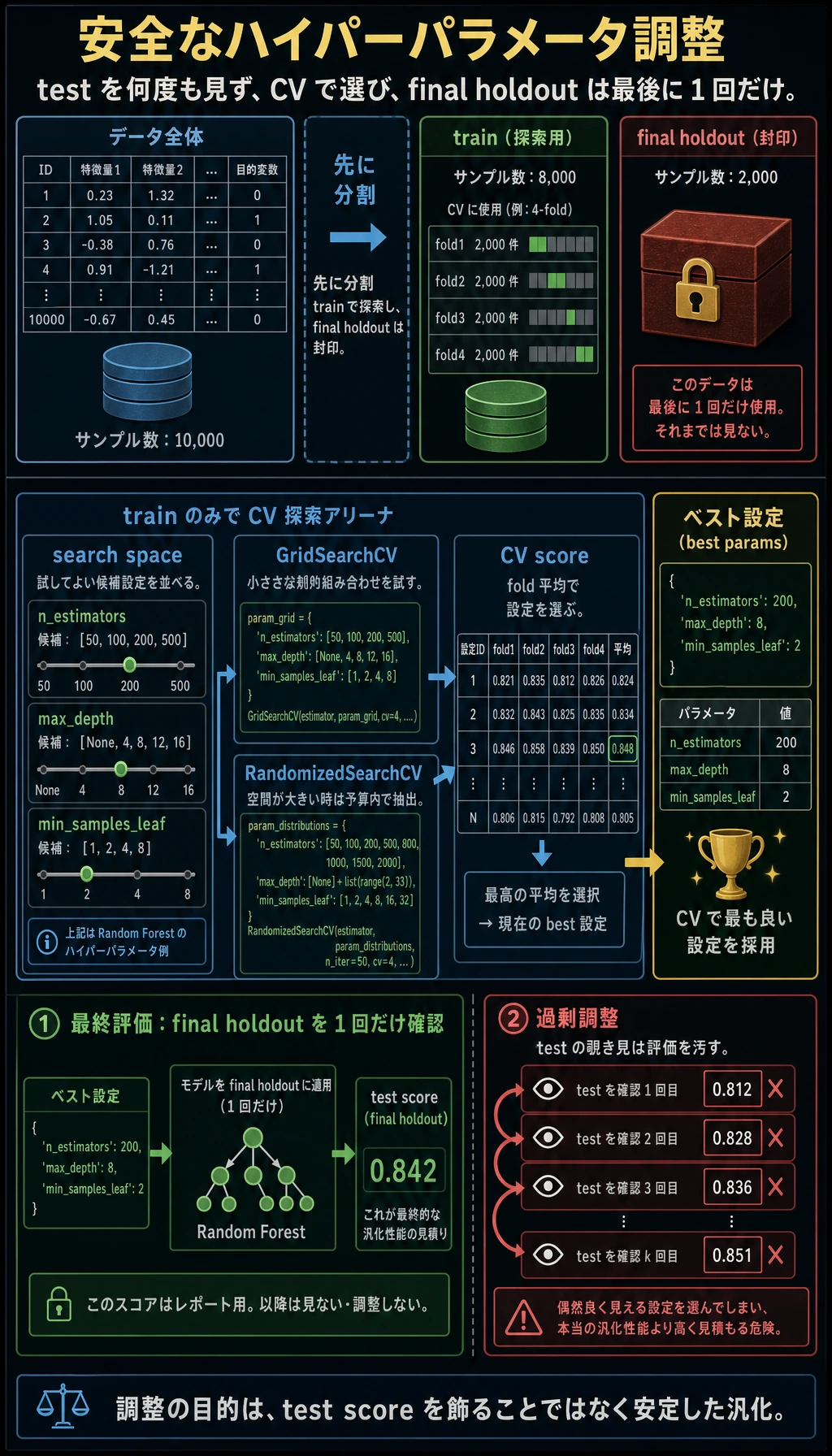
ハイパーパラメータ調整は、「テストスコアが良く見えるまで設定を試すこと」ではありません。安全な流れは、訓練 fold で探索し、クロスバリデーションで選び、最後に final holdout で 1 回だけ確認することです。
作るもの
この節では次を確認します。
- parameters と hyperparameters の違い;
GridSearchCVの使い方;- 探索空間が大きいときの
RandomizedSearchCV; - final holdout を調整に使わず残す方法;
- 過剰調整を避ける方法。
用語早見表
| 用語 | 実用上の意味 |
|---|---|
| parameter | モデルが fit() 中にデータから学ぶ値 |
| hyperparameter | 学習前に人が選ぶ設定。たとえば木の深さ |
| search space | 探索に試させる候補値 |
| CV score | 設定を選ぶためのクロスバリデーションスコア |
| final holdout | 調整後に 1 回だけ使う、触っていないデータ |
| budget | 試せる組み合わせ数や trial 数 |
セットアップ
python -m pip install -U scikit-learn
完全な実験を実行する
tuning_lab.py を作成します。
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, recall_score
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV, StratifiedKFold, train_test_split
X, y = load_breast_cancer(return_X_y=True)
X_train, X_final, y_train, y_final = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
print("grid_search_lab")
grid = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid={
"n_estimators": [80, 160],
"max_depth": [3, 5, None],
"min_samples_leaf": [1, 3],
},
scoring="f1",
cv=cv,
n_jobs=-1,
)
grid.fit(X_train, y_train)
print("best_params=", grid.best_params_)
print(f"best_cv_f1={grid.best_score_:.3f}")
final_pred = grid.best_estimator_.predict(X_final)
print(
f"final accuracy={accuracy_score(y_final, final_pred):.3f} "
f"recall={recall_score(y_final, final_pred):.3f} "
f"f1={f1_score(y_final, final_pred):.3f}"
)
print("random_search_lab")
random_search = RandomizedSearchCV(
RandomForestClassifier(random_state=42),
param_distributions={
"n_estimators": [60, 100, 160, 220],
"max_depth": [3, 5, 8, None],
"min_samples_leaf": [1, 2, 3, 5],
"max_features": ["sqrt", "log2", None],
},
n_iter=8,
scoring="f1",
cv=cv,
random_state=42,
n_jobs=-1,
)
random_search.fit(X_train, y_train)
print("best_params=", random_search.best_params_)
print(f"best_cv_f1={random_search.best_score_:.3f}")
print("top_3_grid_results")
rows = sorted(
zip(grid.cv_results_["mean_test_score"], grid.cv_results_["params"]),
key=lambda item: item[0],
reverse=True,
)[:3]
for score, params in rows:
print(f"score={score:.3f} params={params}")
実行します。
python tuning_lab.py
期待される出力:
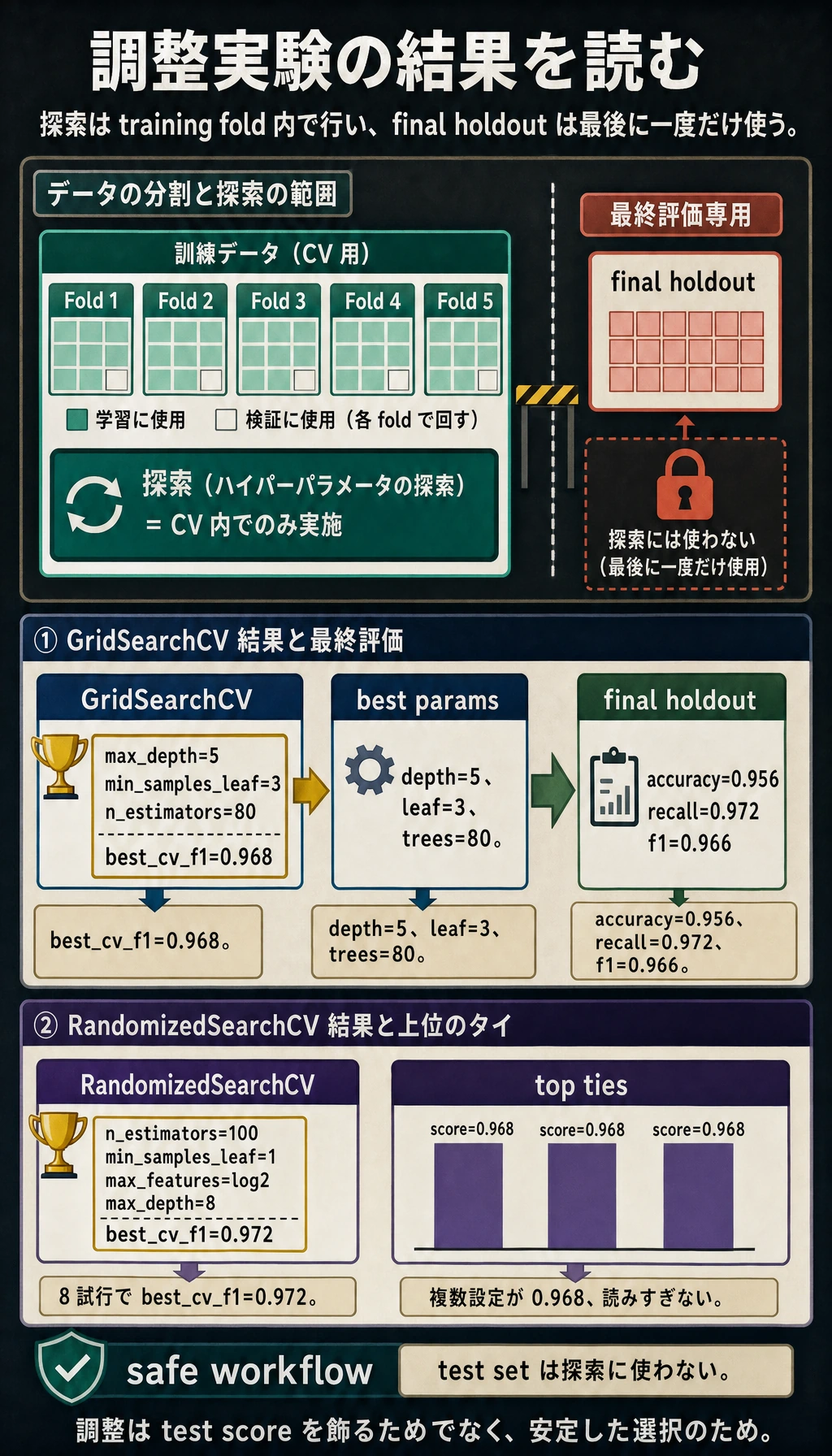
grid_search_lab
best_params= {'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 80}
best_cv_f1=0.968
final accuracy=0.956 recall=0.972 f1=0.966
random_search_lab
best_params= {'n_estimators': 100, 'min_samples_leaf': 1, 'max_features': 'log2', 'max_depth': 8}
best_cv_f1=0.972
top_3_grid_results
score=0.968 params={'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 80}
score=0.968 params={'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 160}
score=0.968 params={'max_depth': None, 'min_samples_leaf': 3, 'n_estimators': 160}
パラメータとハイパーパラメータ
ランダムフォレストは、データから分岐ルールを学びます。学習された分岐ルールは parameters です。
人が事前に選ぶ設定には次があります。
n_estimators;max_depth;min_samples_leaf;max_features。
これらが hyperparameters です。学習の進み方を形作ります。
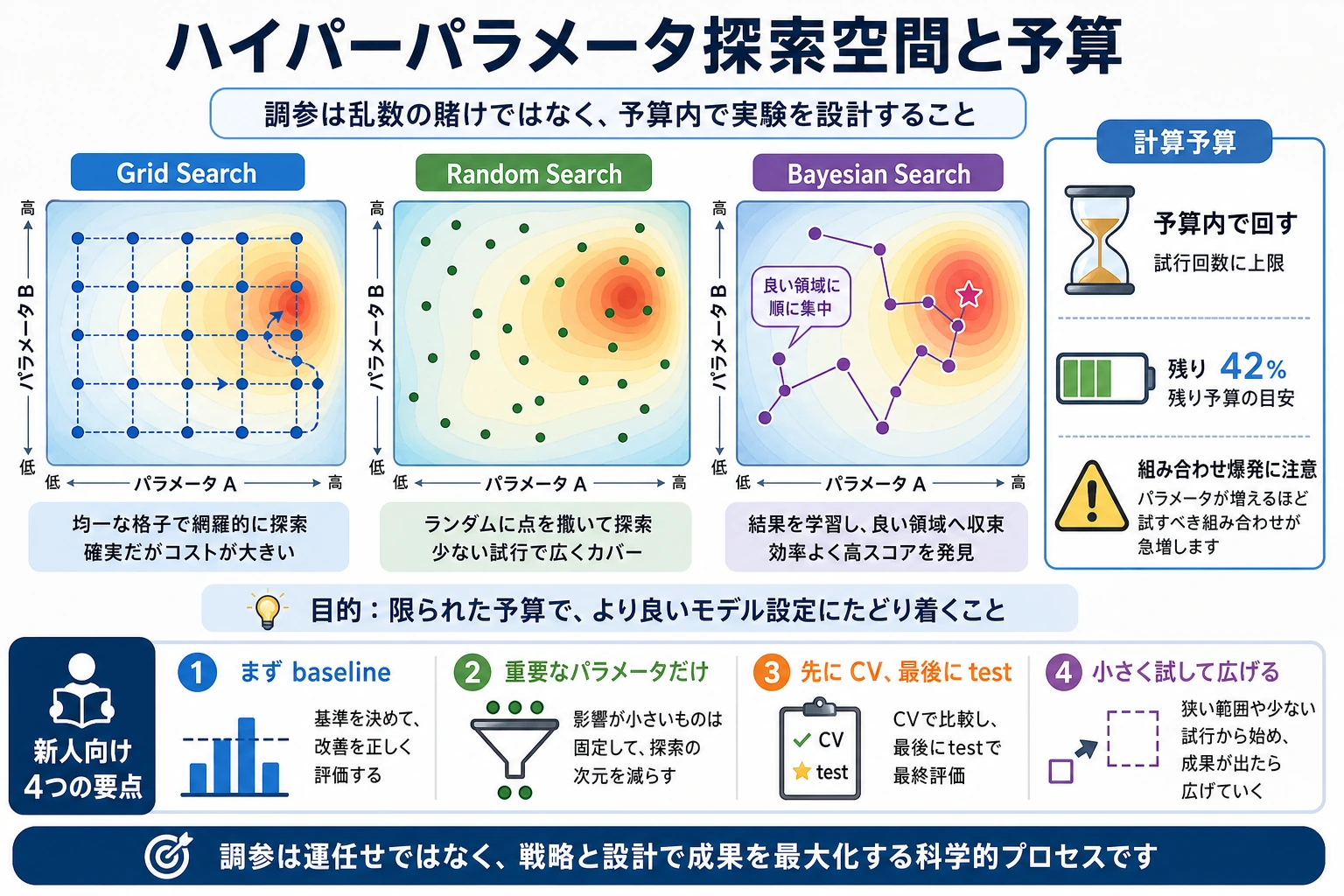
Grid Search
Grid search は、列挙したすべての組み合わせを試します。
param_grid={
"n_estimators": [80, 160],
"max_depth": [3, 5, None],
"min_samples_leaf": [1, 3],
}
この grid は 2 x 3 x 2 = 12 通りです。5-fold CV なら、60 回モデルを fit します。
Grid search が向いている場面:
- 探索空間が小さい;
- 妥当な候補値がある程度わかっている;
- 単純で再現しやすい基線がほしい。
Random Search
Random search は、大きな空間から限られた回数だけ組み合わせを抽出します。
n_iter=8
実験では、8 通りだけ試しながらより広い空間を探索し、少し高い CV F1 を見つけました。
best_cv_f1=0.972
Random search が向いている場面:
- ハイパーパラメータが多い;
- 学習コストが高い;
- 狭い grid を作る前に広く探索したい。
Final Holdout
final holdout は、CV 探索に使っていない部分です。
X_train, X_final, y_train, y_final = train_test_split(...)
探索が最良設定を選んだ後、1 回だけ評価します。
final accuracy=0.956 recall=0.972 f1=0.966
final holdout を見たあとに grid を変え続けないでください。そうすると final holdout ではなく、調整の一部になります。
探索結果を読む
Grid の上位結果はかなり近いです。
score=0.968 params={'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 80}
score=0.968 params={'max_depth': 5, 'min_samples_leaf': 3, 'n_estimators': 160}
スコアが同じくらいなら、より単純または安いモデルを選びます。木が多い、深い、というだけでは良いモデルとは限りません。
実用的な調整戦略
| 段階 | 行動 |
|---|---|
| 開始 | まず既定設定で簡単な基線を作る |
| 診断 | bias/variance と指標選択を確認する |
| 最初の探索 | 重要パラメータの小さな grid を試す |
| 広い探索 | 組み合わせが爆発したら random search |
| 最終確認 | untouched holdout で 1 回だけ評価 |
| 本番 | ドリフトと再学習方針を監視する |
経験者向け:Optuna などのベイズ最適化ツールは、1 回の trial が高価なときや探索空間が大きいときに便利です。ただし、きれいな検証設計の代わりにはなりません。
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| 探索が遅すぎる | grid が大きすぎる | 候補値を減らし、random search を使う |
| CV スコアは上がるが final holdout が下がる | 過剰調整 | 探索を単純にし、新しい holdout を残す |
| 最良モデルがかなり複雑 | 指標差が小さい | 安い/単純なモデルを選ぶ |
| 実行ごとに違う params が選ばれる | データが不安定、fold が小さい | repeated CV や分散確認を行う |
| 調整しても改善しない | モデルクラスや特徴量が制限 | 先に特徴量やモデルファミリーを改善する |
練習
- scoring を
"f1"から"recall"に変えてください。最良パラメータは変わりますか? - grid に
max_depth=10を追加してください。CV スコアは改善しますか? n_iterを8から16に増やしてください。追加コストに見合う改善がありますか?cv_results_からmean_fit_timeを表示し、スコアが近いときは安いモデルを選んでください。- 以前の CV だけの実験に、最後まで触らない test set を追加してください。
合格チェック
次を説明できれば、この節はクリアです。
- ハイパーパラメータは学習前に選ぶ;
- grid search は小さな候補空間を全探索する;
- random search は大きな探索空間に向いている;
- final holdout は繰り返し調整に使ってはいけない;
- 調整では、悪い特徴量や誤った検証設計は救えない。