9.9.5 成本优化
本节定位
Agent 系统的成本,很多时候不是“调用一次模型多少钱”这么简单。 真正影响账单的,常常是整条链路:
- 多轮模型调用
- 工具调用
- 检索
- 重试
- 长上下文
所以做成本优化时,关键不是只盯模型单价,而是:
看清整条任务链里,钱到底花在哪。
学习目标
- 理解 Agent 成本的主要组成部分
- 学会通过最小示例估算一次任务链路成本
- 理解缓存、路由、截断和重试控制为什么能显著省钱
- 建立“成本优化不是单点技巧,而是全链路策略”的意识
Agent 的钱通常花在哪?
模型 token 成本
最直接的一层是:
- 输入 token
- 输出 token
上下文越长、步骤越多,成本越高。
工具和外部依赖成本
例如:
- 搜索 API
- 向量检索
- 第三方接口
- 代码执行环境
这些不一定按 token 计费,但都是真实成本。
重试与失败成本
失败不只是“没结果”,还意味着:
- 已经花掉一次调用的钱
- 还可能触发重试,继续加钱
所以运行时策略和成本优化天然耦合。
为什么 Agent 比普通聊天更容易“看不懂账单”?
因为一次用户请求背后可能拆成很多内部调用
例如用户只问一句:
- “我这单能不能退款?”
系统内部可能做了:
- 一次工具选择推理
- 一次订单状态查询
- 一次政策检索
- 一次金额计算
- 一次最终回答生成
如果其中还带重试,成本会继续放大。
所以成本核算应该按“任务链”而不是“单调用”
这个视角非常关键:
- 用户看到的是 1 次请求
- 系统内部跑的是 5-10 次动作
成本优化必须围绕“整链路”。
先跑一个最小成本估算器
这个示例会把一次 Agent 任务拆成几段成本:
- 模型 token 成本
- 工具调用成本
- 重试额外成本
PRICES = {
"small_model": {"input_per_1k": 0.001, "output_per_1k": 0.002},
"large_model": {"input_per_1k": 0.01, "output_per_1k": 0.03},
}
TOOL_PRICES = {
"search_api": 0.002,
"vector_retrieval": 0.0005,
"sql_query": 0.0002,
}
def llm_cost(model_name, input_tokens, output_tokens):
price = PRICES[model_name]
return (
input_tokens / 1000 * price["input_per_1k"]
+ output_tokens / 1000 * price["output_per_1k"]
)
def task_cost(task):
total = 0.0
for call in task["llm_calls"]:
total += llm_cost(call["model"], call["input_tokens"], call["output_tokens"])
for tool in task["tool_calls"]:
total += TOOL_PRICES[tool]
return round(total, 6)
baseline_task = {
"llm_calls": [
{"model": "large_model", "input_tokens": 1800, "output_tokens": 300},
{"model": "large_model", "input_tokens": 1400, "output_tokens": 220},
],
"tool_calls": ["search_api", "vector_retrieval"],
}
optimized_task = {
"llm_calls": [
{"model": "small_model", "input_tokens": 700, "output_tokens": 120},
{"model": "large_model", "input_tokens": 900, "output_tokens": 180},
],
"tool_calls": ["vector_retrieval"],
}
print("baseline_cost =", task_cost(baseline_task))
print("optimized_cost =", task_cost(optimized_task))
预期输出:
baseline_cost = 0.0501
optimized_cost = 0.01584

这段代码最想让你看到什么?
不是某个具体价格, 而是成本的组成方式:
- 哪几次模型调用最贵
- 哪些工具调用叠起来也不便宜
- 优化后为什么会明显下降
为什么“先小模型筛,再大模型精答”常常有效?
因为很多请求并不需要最贵模型全程参与。 典型做法是:
- 小模型做路由 / 过滤
- 大模型只处理真正复杂部分
为什么减少一次 search_api 也可能很值?
因为外部 API 单价有时并不低, 而且它还会增加延迟和重试风险。

读图提示
这张图把成本从“单次模型调用”扩展成“任务链路账单”:模型路由、上下文长度、工具调用、缓存命中、失败重试和预算上限都会影响最终成本。
成本优化最常见的五个方向
缩短上下文
最直接的方法通常是:
- 删掉无关历史
- 压缩长上下文
- 提前摘要
模型分级路由
常见模式:
- 简单请求 -> 小模型
- 复杂请求 -> 大模型
缓存
适合:
- 高频重复问题
- 只读工具结果
- 固定政策类内容
工具调用去重
很多 Agent 的钱其实不是花在“该调用的工具”上, 而是花在:
- 重复查同样的东西
控制失败与重试
如果失败太多或重试太多, 账单会很快失真。
一个非常实用的缓存节省示例
cache = {}
def cached_lookup(query, raw_cost=0.002):
if query in cache:
return {"source": "cache", "cost": 0.0}
cache[query] = True
return {"source": "api", "cost": raw_cost}
queries = ["退款政策", "退款政策", "证书规则", "退款政策"]
total_cost = 0.0
for query in queries:
result = cached_lookup(query)
total_cost += result["cost"]
print(query, "->", result)
print("total_cost =", total_cost)
预期输出:
退款政策 -> {'source': 'api', 'cost': 0.002}
退款政策 -> {'source': 'cache', 'cost': 0.0}
证书规则 -> {'source': 'api', 'cost': 0.002}
退款政策 -> {'source': 'cache', 'cost': 0.0}
total_cost = 0.004
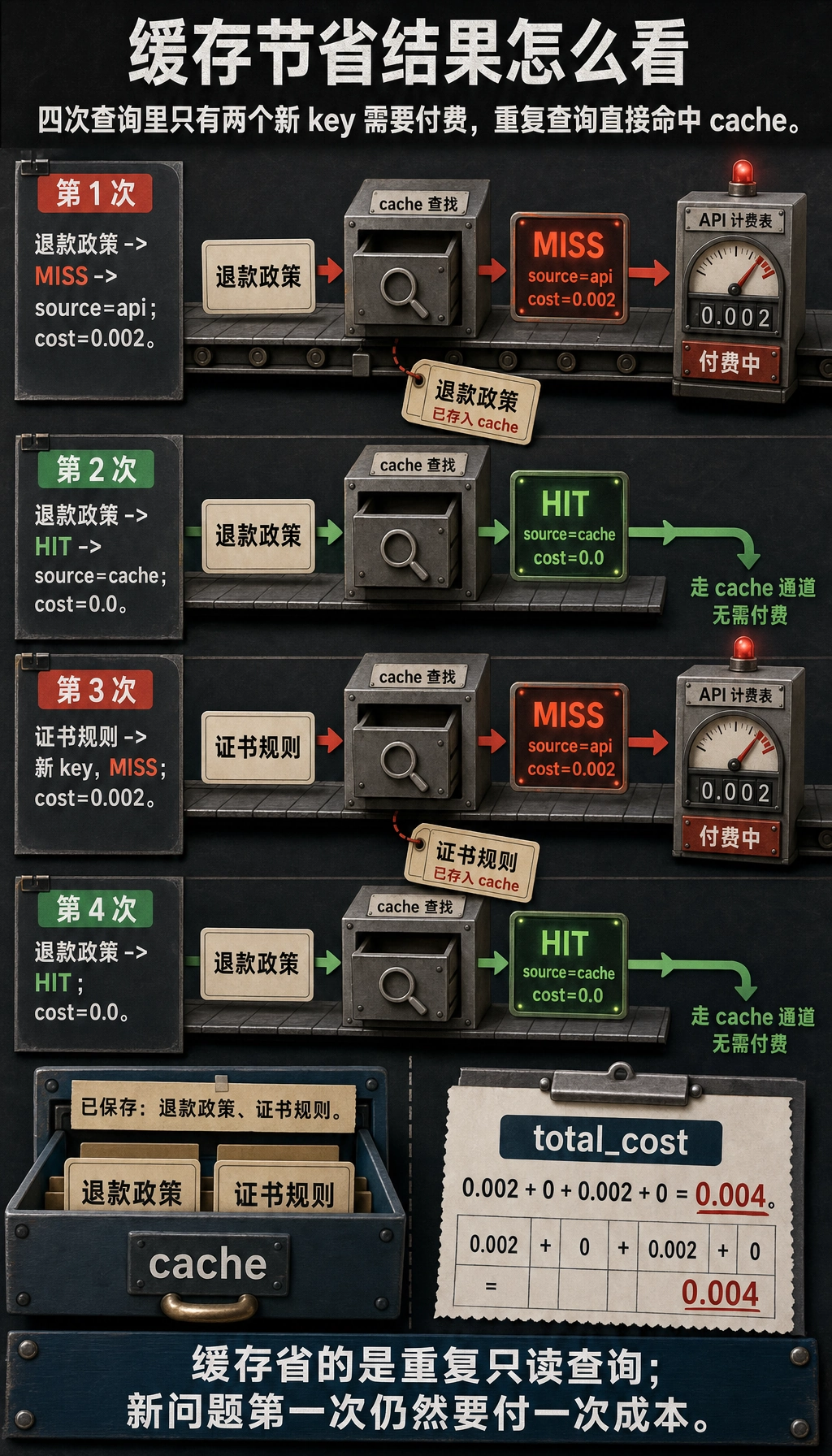
这段代码虽然简单,但已经非常接近真实工程的一个核心事实:
- 高频重复请求不做缓存,会持续烧钱
成本优化最容易踩的坑
误区一:只换更便宜模型就算优化
如果链路设计不变、工具调用照样乱、重试依然失控, 模型单价下降也未必能救整体账单。
误区二:一味追最低成本
如果为了省钱导致:
- 正确率显著下降
- 延迟反而上升
- 复杂请求答不出来
那就不是真正的优化。
误区三:不做“单请求成本画像”
如果你不知道:
- 哪类请求最贵
- 贵在哪一段
后面的优化基本只能盲猜。
小结
这节最重要的是建立一个全链路成本观:
Agent 成本优化不是“把模型换便宜一点”这么简单,而是同时优化上下文长度、模型路由、工具调用、缓存命中和失败重试。
当你开始按任务链拆成本,而不是只看单个模型调用时,优化才会真正有效。
练习
- 给示例再加一条“重试导致额外模型调用”的成本,看看总价怎么变化。
- 想一想:哪些请求适合直接走缓存,哪些请求必须实时算?
- 为什么说模型分级路由通常比“统一用大模型”更适合生产系统?
- 如果某条链路正确率很高但成本异常高,你会先从哪一段查?