2.1.3 演算子と式
この節の位置づけ
この節では、データに対して計算や判定を行う方法を学びます。演算子は数学計算だけでなく、モデル指標の計算、条件による絞り込み、ループの判定、データクレンジングのロジックにもよく使われます。変数を組み合わせてプログラムのロジックを作るための、最初の一歩です。
学習目標
- 算術演算子、比較演算子、論理演算子を理解する
- 演算子の優先順位を理解する
- 代入演算子とメンバーシップ演算子の使い方を学ぶ
- 正しい条件式を書けるようになる
| 何をしたいか | よく使う演算子 |
|---|---|
| 数値を計算する | +、-、*、/ |
| 大きさを比べる | >、>=、==、!= |
| 条件を組み合わせる | and、or、not |
| 含まれているか判定する | in、not in |
まずは場面を見てみよう
AI のデータ処理スクリプトを開発しているとします。次のような処理が必要です。
- モデルの正解率を計算する:
correct / total * 100 - 合格かどうかを判定する:
accuracy >= 60 - 2つの条件を確認する:
accuracy >= 60 and loss < 0.5
これらの操作はすべて演算子なしではできません。演算子とは、Python に「データに対して何をするか」を伝える記号です。
算術演算子
いちばん基本的な数学演算です。
| 演算子 | 意味 | 例 | 結果 |
|---|---|---|---|
+ | 足し算 | 5 + 3 | 8 |
- | 引き算 | 5 - 3 | 2 |
* | 掛け算 | 5 * 3 | 15 |
/ | 割り算 | 5 / 3 | 1.6667 |
// | 切り捨て除算 | 5 // 3 | 1 |
% | 余り | 5 % 3 | 2 |
** | べき乗 | 5 ** 3 | 125 |
実際の例
# シーン:AI モデル学習のいくつかの指標を計算する
total_samples = 1000 # 総サンプル数
correct = 873 # 正しく予測できた数
epochs = 50 # 学習回数
batch_size = 32 # バッチサイズ
# 正解率を計算する
accuracy = correct / total_samples * 100
print(f"正解率: {accuracy}%") # 87.3%
# 1 epoch を終えるのに必要なバッチ数を計算する
batches_per_epoch = total_samples // batch_size
remaining = total_samples % batch_size
print(f"各 epoch の完全なバッチ数: {batches_per_epoch}") # 31
print(f"最後のバッチのサンプル数: {remaining}") # 8
# 指数減衰する学習率を計算する
initial_lr = 0.01
decay = 0.95
current_lr = initial_lr * (decay ** epochs)
print(f"{epochs} 回目の学習の学習率: {current_lr:.6f}") # 0.000769
- epoch(エポック、学習回数):学習データを最初から最後まで 1 回見ることです。1000 件のサンプルがあれば、1 epoch はモデルが 1000 件すべてを 1 回見たという意味です。
- batch(バッチ):まとめて処理する小さなサンプルのかたまりです。
batch_size = 32は、モデルが全データを一度に見るのではなく、32 件ずつ見るという意味です。 - learning rate / lr(学習率):モデルのパラメータを更新するときの一歩の大きさです。大きすぎると不安定になり、小さすぎると学習が遅くなります。
- decay(減衰):値を少しずつ小さくすることです。学習が進むにつれて学習率を下げるときによく使います。
割り算の2つの形
ここは初心者がよく混乱するところです。
print(7 / 2) # 3.5 ← 通常の割り算。結果は float
print(7 // 2) # 3 ← 切り捨て除算。小数部分を捨てる
print(-7 // 2) # -4 ← 注意!0 方向ではなく、下方向に切り捨てる
# 余りの使いどころ
print(10 % 3) # 1 ← 10 を 3 で割ると余りは 1
print(15 % 5) # 0 ← 割り切れると余りは 0
# 奇数・偶数の判定
number = 42
if number % 2 == 0:
print(f"{number} は偶数です") # 42 は偶数
比較演算子
比較演算子の結果は常に真偽値(True または False)です。
| 演算子 | 意味 | 例 | 結果 |
|---|---|---|---|
== | 等しい | 5 == 5 | True |
!= | 等しくない | 5 != 3 | True |
> | より大きい | 5 > 3 | True |
< | より小さい | 5 < 3 | False |
>= | 以上 | 5 >= 5 | True |
<= | 以下 | 5 <= 3 | False |
# シーン:モデルの性能を判定する
accuracy = 87.3
loss = 0.35
print(accuracy > 90) # False —— 正解率は 90 を超えていない
print(accuracy >= 80) # True —— 正解率は 80 以上ある
print(loss < 0.5) # True —— 損失値は 0.5 未満
print(accuracy == 87.3) # True —— 正解率はちょうど 87.3
= と == の違い=は代入です:x = 5は 5 を x に入れる==は比較です:x == 5は x が 5 と等しいかを判定する
初学者がいちばん間違えやすいのは、判定のときに == ではなく = と書いてしまうことです。
連鎖比較(Python 特有)
Python では連鎖比較ができます。これは他の言語ではできないことがあります。
age = 25
# age が 18 から 65 の間かを判定する
print(18 <= age <= 65) # True
# 同じ意味
print(18 <= age and age <= 65) # True。ただし上の書き方のほうが簡潔
# さらに例
x = 5
print(1 < x < 10) # True
print(1 < x < 3) # False
論理演算子
論理演算子は、複数の条件を組み合わせるために使います。
| 演算子 | 意味 | 説明 |
|---|---|---|
and | かつ | 両方が真のときだけ真 |
or | または | 少なくとも1つが真なら真 |
not | ではない | 反転する。真は偽に、偽は真になる |
age = 25
has_id = True
has_ticket = False
# and: 2つの条件を両方満たす
can_enter = age >= 18 and has_id
print(f"入場できるか: {can_enter}") # True(年齢は足りていて、証明書もある)
# or: 少なくとも1つの条件を満たす
has_pass = has_id or has_ticket
print(f"通行証があるか: {has_pass}") # True(証明書があればよい)
# not: 反転する
is_minor = not (age >= 18)
print(f"未成年か: {is_minor}") # False
実際の例: AI モデル評価
accuracy = 92.5
loss = 0.15
training_time = 3.5 # 時間
# 良いモデルの条件: 正解率 > 90 かつ 損失 < 0.3
is_good_model = accuracy > 90 and loss < 0.3
print(f"良いモデルですか: {is_good_model}") # True
# 再学習が必要: 正解率が低すぎる、または 損失が高すぎる
need_retrain = accuracy < 80 or loss > 1.0
print(f"再学習が必要ですか: {need_retrain}") # False
# 実用的なモデル: 良いモデル かつ 学習時間が妥当
is_practical = is_good_model and not (training_time > 24)
print(f"実用的ですか: {is_practical}") # True
短絡評価
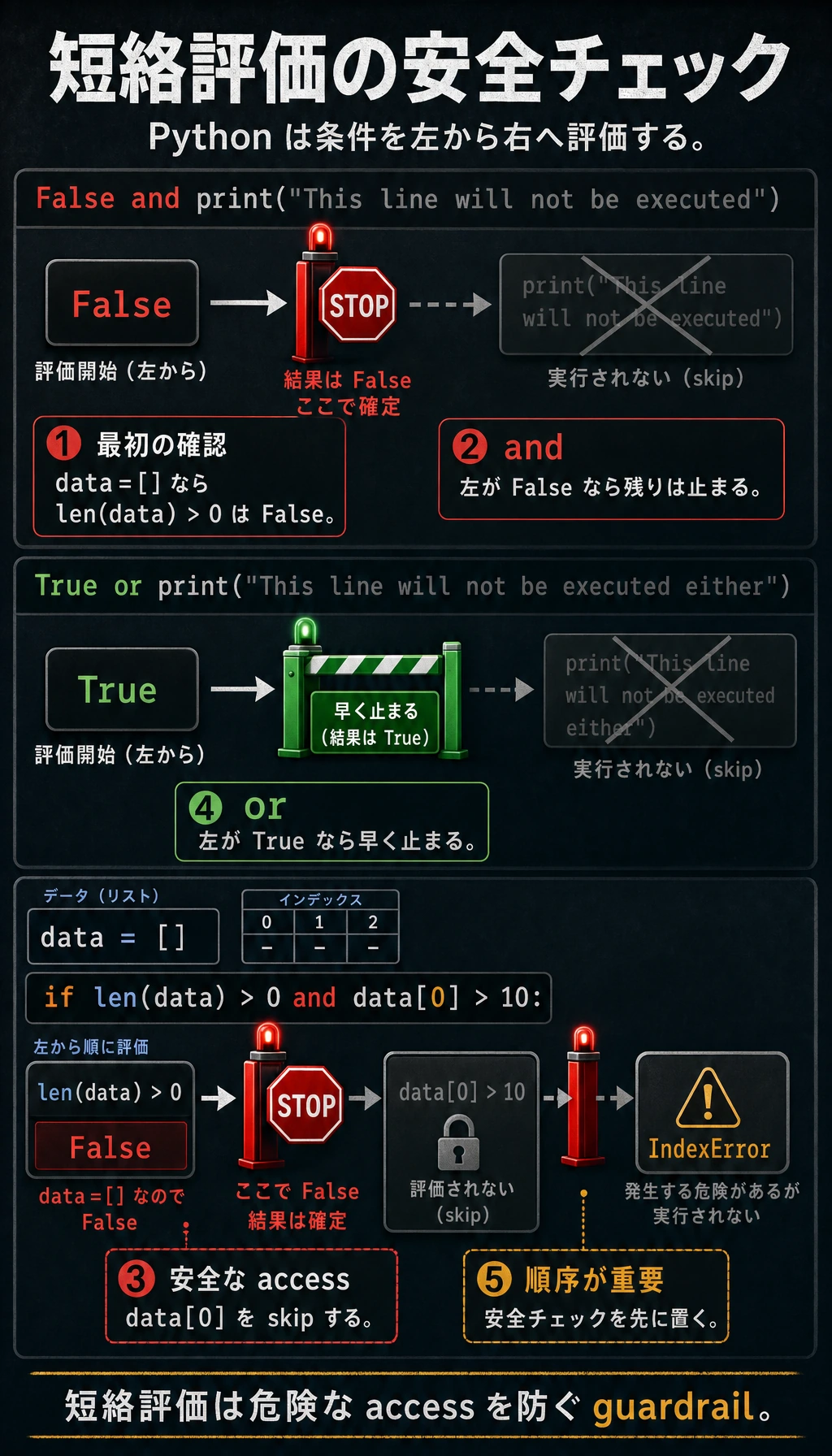
Python の and と or には、短絡評価という賢い性質があります。
# and: 1つ目の条件が False なら、2つ目は確認しない
# 1つ目がすでに False なので、結果は必ず False
False and print("この文は実行されません")
# or: 1つ目の条件が True なら、2つ目は確認しない
# 1つ目がすでに True なので、結果は必ず True
True or print("この文も実行されません")
この性質は、実際のプログラミングで安全確認によく使います。
# 先にリストが空かどうかを確認してから要素にアクセスする(エラー防止)
data = []
# data が空なら len(data) > 0 は False なので、後ろは実行されない
if len(data) > 0 and data[0] > 10:
print("最初の要素は 10 より大きい")
代入演算子
基本の = 以外にも、短く書ける形があります。
| 演算子 | 同じ意味 | 例 |
|---|---|---|
+= | a = a + b | a += 5 |
-= | a = a - b | a -= 3 |
*= | a = a * b | a *= 2 |
/= | a = a / b | a /= 4 |
//= | a = a // b | a //= 3 |
%= | a = a % b | a %= 2 |
**= | a = a ** b | a **= 3 |
score = 0
score += 10 # score = 0 + 10 = 10
score += 20 # score = 10 + 20 = 30
score -= 5 # score = 30 - 5 = 25
score *= 2 # score = 25 * 2 = 50
print(f"最終スコア: {score}") # 50
これらの短縮形は、ループで特によく使います。
# 1 から 100 までを足し合わせる
total = 0
for i in range(1, 101):
total += i
print(f"1 から 100 までの合計: {total}") # 5050
メンバーシップ演算子
in と not in は、ある値が集合の中に含まれているかどうかを調べます。
# 文字列の中から探す
print("Python" in "I love Python") # True
print("Java" in "I love Python") # False
print("Java" not in "I love Python") # True
# リストの中から探す
fruits = ["りんご", "バナナ", "オレンジ"]
print("りんご" in fruits) # True
print("スイカ" in fruits) # False
# 実用例: ファイル拡張子を確認する
filename = "model.py"
if ".py" in filename:
print("これは Python ファイルです")
同一性演算子
is と is not は、2つの変数が同じオブジェクトかどうかを調べます。値が同じかどうかではなく、メモリ上の同じものかどうかを見ます。
a = None
# None かどうかを確認する(== ではなく is を使うのが推奨)
print(a is None) # True
print(a is not None) # False
# is と == の違い
x = [1, 2, 3]
y = [1, 2, 3]
z = x
print(x == y) # True —— 値が同じ
print(x is y) # False —— 同じオブジェクトではない(別のリスト)
print(x is z) # True —— z は x を指しているので同じオブジェクト
is を使う?99% の場面では == で十分です。is は主に None との比較に使います。
- 良い例:
if x is None: - よくない例:
if x == None:
演算子の優先順位
1つの式に複数の演算子があるとき、Python は優先順位の高いものから順に計算します。
| 優先順位(高→低) | 演算子 |
|---|---|
| 1(最高) | ** べき乗 |
| 2 | +x, -x 正負記号 |
| 3 | *, /, //, % |
| 4 | +, - |
| 5 | ==, !=, >, <, >=, <= |
| 6 | not |
| 7 | and |
| 8(最低) | or |
# 括弧なし
result = 2 + 3 * 4 # 先に掛け算、その後に足し算: 2 + 12 = 14
result = 2 ** 3 ** 2 # べき乗は右から左: 2 ** 9 = 512
# 括弧をつけるとわかりやすい(おすすめ)
result = (2 + 3) * 4 # 20
result = (2 ** 3) ** 2 # 64
優先順位がわからないときは、括弧をつけましょう! 括弧は計算順序を正しくするだけでなく、コードを読みやすくもします。括弧を多く書いたからといって、誰かに笑われることはありません。
総合例: BMI 計算機
今日学んだ演算子をまとめて使ってみましょう。
# BMI 計算機
name = "小明"
weight = 70 # kg
height = 1.75 # m
# BMI を計算する: 体重 / 身長の2乗
bmi = weight / height ** 2 # 先に height**2 を計算してから割り算する
print(f"{name} の BMI: {bmi:.1f}") # 22.9
# 体重の範囲を判定する
is_underweight = bmi < 18.5
is_normal = 18.5 <= bmi < 24
is_overweight = 24 <= bmi < 28
is_obese = bmi >= 28
print(f"低体重: {is_underweight}") # False
print(f"普通体重: {is_normal}") # True
print(f"過体重: {is_overweight}") # False
print(f"肥満: {is_obese}") # False
# 総合判定
is_healthy = is_normal and not is_underweight
print(f"健康: {is_healthy}") # True
手を動かしてみよう
練習 1: 成績ランクの判定
比較演算子と論理演算子を使って成績ランクを判定しましょう。
score = 85
is_excellent = score >= 90 # 優秀
is_good = score >= 80 and score < 90 # 良い
is_pass = score >= 60 and score < 80 # 合格
is_fail = score < 60 # 不合格
# 結果を表示する
print(f"点数: {score}")
print(f"優秀: {is_excellent}")
print(f"良い: {is_good}")
print(f"合格: {is_pass}")
print(f"不合格: {is_fail}")
score の値を変えて、いろいろな点数の結果を試してみましょう。
練習 2: うるう年の判定
うるう年のルール: 4 で割り切れるが 100 では割り切れない、または 400 で割り切れる。
year = 2024
# ヒント: % を使って割り切れるかを判定し、and、or で条件を組み合わせる
is_leap = ___ # この式を完成させる
print(f"{year} はうるう年ですか? {is_leap}")
練習 3: 三角形の判定
3辺で三角形を作れるか判定しましょう(どの2辺の和も他の1辺より大きい)。
a, b, c = 3, 4, 5
# 判定条件を完成させる
is_triangle = ___
print(f"辺の長さ {a}, {b}, {c} で三角形を作れますか? {is_triangle}")
まとめ
| 演算子の種類 | よく使う記号 | 用途 |
|---|---|---|
| 算術 | +, -, *, /, //, %, ** | 数学計算 |
| 比較 | ==, !=, >, <, >=, <= | 条件判定、結果は True/False |
| 論理 | and, or, not | 複数条件の組み合わせ |
| 代入 | =, +=, -=, *= など | 変数に値を入れる |
| メンバーシップ | in, not in | 要素が集合に含まれるか調べる |
| 同一性 | is, is not | 同じオブジェクトか調べる |
演算子は、プログラミングの基本となる「動詞」です。変数やデータは「名詞」、演算子は「動詞」です。これらが組み合わさって「式」になります。つまり、コンピュータに何をさせたいかを伝えるのが式です。