5.1.5 機械学習の歴史的ブレークスルーの流れ
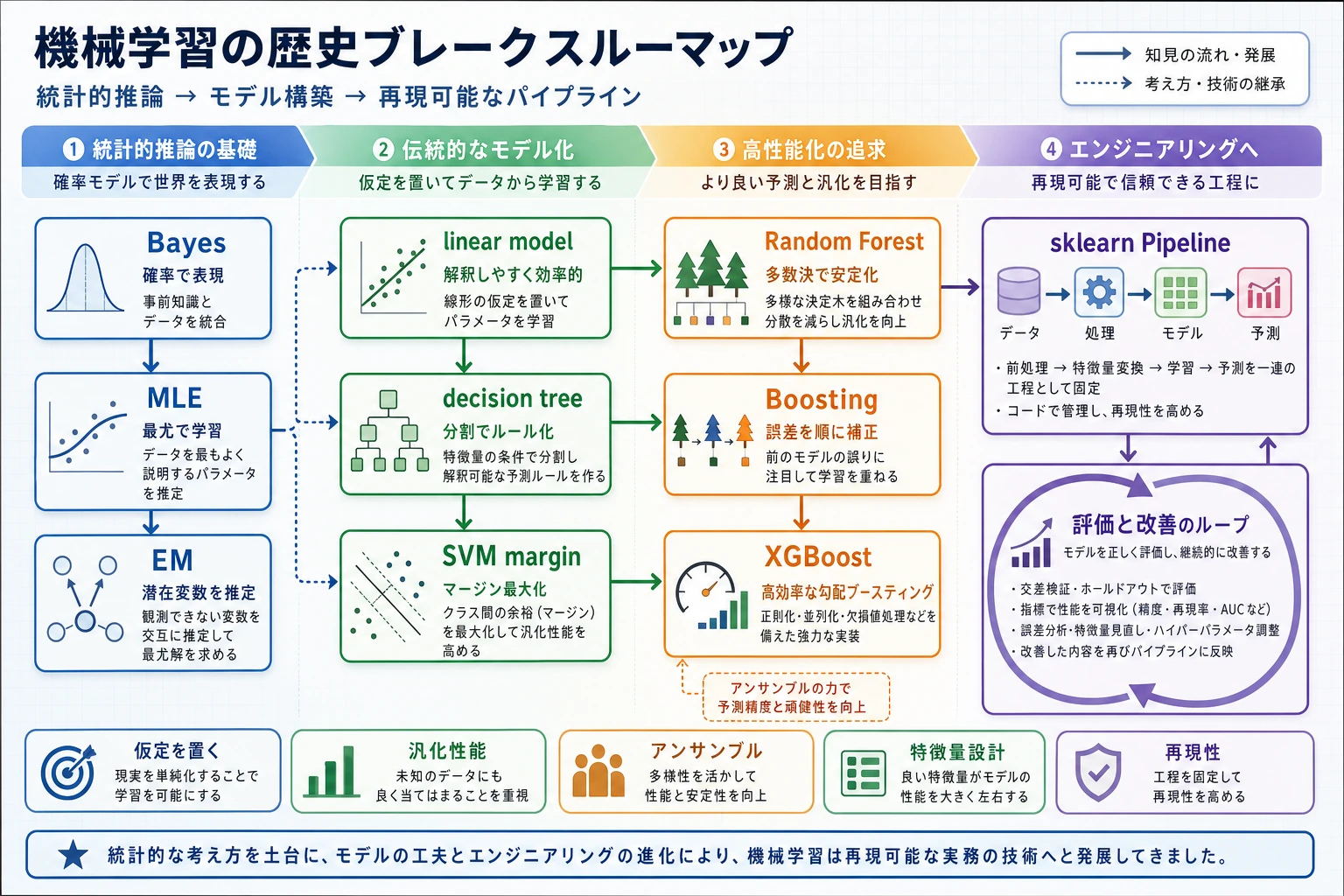
この節は、年号を暗記するためのものではありません。次のことを理解する助けにするためのものです。
- それぞれの機械学習ブレークスルーの前に、何でつまずいていたのか
- 新しい方法は、いったい何を解決したのか
- この章のどの位置に置いて学ぶべきか
- プロジェクトをするとき、この歴史的な節目がどんな工程力になるのか
一、まず一言で機械学習の歴史の主線をつかもう
機械学習の歴史は、まず「人がルールを書く」世界から「データから規則を学ぶ」世界へ向かう流れとして理解できます。
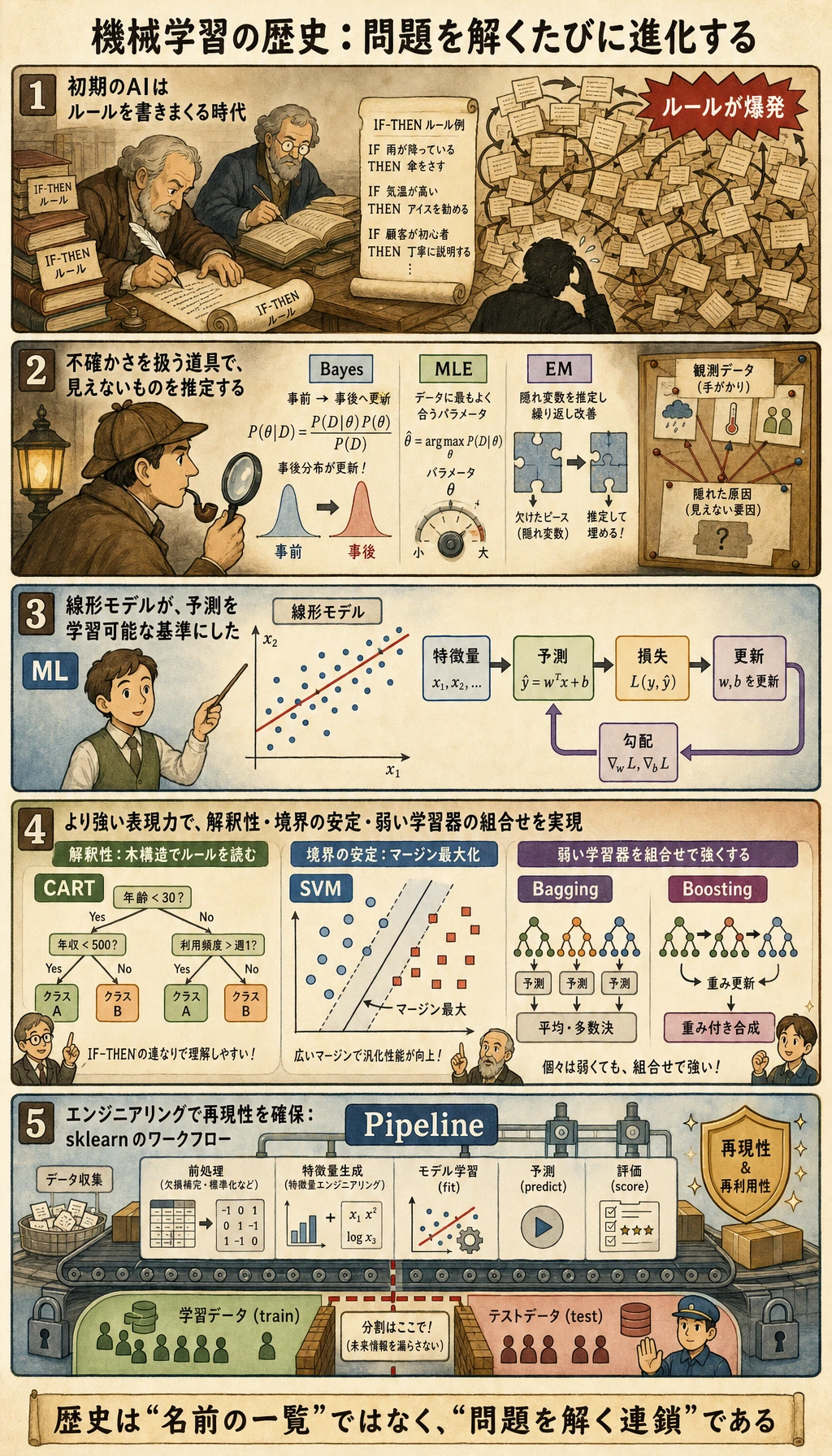
この漫画は問題が順番に解かれていく流れとして読んでください。手書きルールは壊れやすく、確率は不確実性を扱えるようにし、線形モデルは学習を具体化し、木・SVM・集成法は構造と安定性を強め、最後に sklearn が再現可能な工程にまとめました。
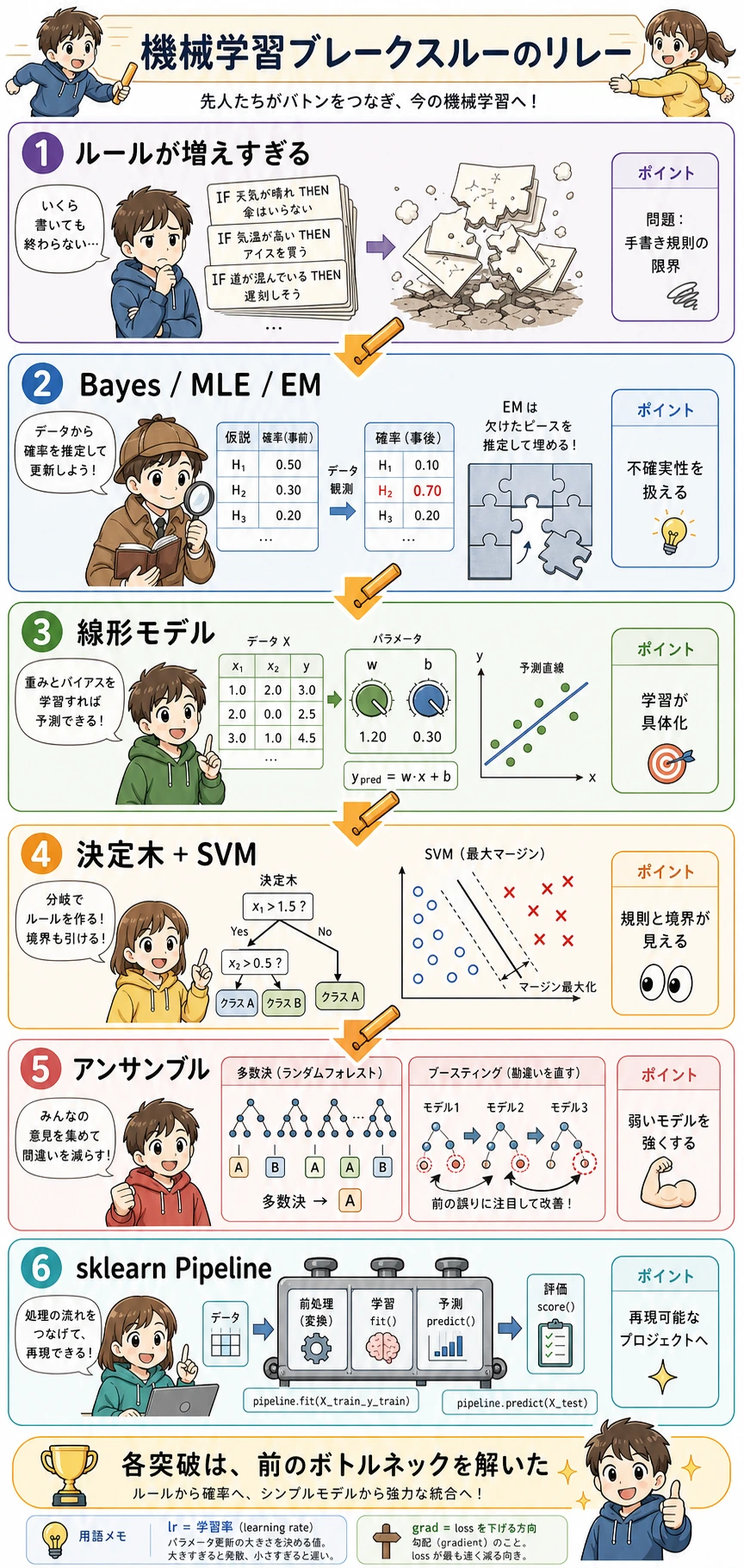
このリレー図は、「なぜ次の方法が必要になったのか」をつかむのに役立ちます。確率的手法は不確実性を扱えるようにし、線形モデルは学習を見える形にし、木と SVM は構造と境界を分かりやすくし、アンサンブルは不安定なモデルを強くし、最後に sklearn が全体を再現可能なプロジェクトにしました。
初期の AI は、人手で書いたルールに強く依存していました。人間の専門家が知識を if-else や記号ルールとして書き出し、システムはそのルールに従って推論します。この考え方は、ルールがはっきりした場面では役に立ちますが、タスクが複雑になるとルールが爆発的に増えてしまいます。たとえば、あるメールがスパムかどうかを判定する場合、すべてのルールを事前に書き切るのはとても難しいです。
機械学習の重要な転換はこうです。ルールを直接手で書くのではなく、データを用意し、目的を定義し、モデルを選んで、モデル自身に事例から規則を学ばせるのです。第 5 章で身につけたいのは「アルゴリズム名を覚えること」ではなく、このモデリングの考え方です。
| 歴史的な変化 | この章で対応する力 |
|---|---|
| ルールからデータへ | どんなときに機械学習を使うべきか分かる |
| 一度きりの当てはまりから評価へ | train/test、指標、汎化を学ぶ |
| 単一モデルからモデル群へ | baseline、木モデル、集成法を比べられる |
| 手書きの流れから工程化へ | sklearn、Pipeline、レポートで振り返る |
このページのキーワードを先にほどく
| キーワード | 正式名 / 意味 | 初学者向けの説明 |
|---|---|---|
AI | Artificial Intelligence、人工知能 | より大きな目標:機械が知的なふるまいを見せること |
ML | Machine Learning、機械学習 | AI の一分野。手書きルールだけでなく、データから規則を学ぶ |
MLE | Maximum Likelihood Estimation、最尤推定 | 観測データが最も起こりやすく見えるパラメータを選ぶ考え方 |
EM | Expectation-Maximization | 隠れた情報を推定し、パラメータを更新する流れを交互に繰り返す |
SVM | Support Vector Machine、サポートベクターマシン | クラス間に広く安定した余白を取ろうとする分類器 |
CART | Classification and Regression Trees | 分類木と回帰木を体系的に作る方法 |
Bagging | Bootstrap Aggregating | 複数モデルを並列に学習し、投票や平均でまとめる |
Boosting | 逐次的な誤り修正 | モデルを順番に学習し、後のモデルが前の間違いを重点的に直す |
GBDT | Gradient Boosting Decision Tree | 小さな木を重ねながら予測を改善する Boosting 系手法 |
XGBoost | Extreme Gradient Boosting | 高速で実務向けに整えられた GBDT 系実装 |
baseline | 最初の妥当な比較モデル | 改善を主張する前に、まず超えるべきシンプルな基準 |
Pipeline | 再現可能な処理の連鎖 | 前処理、学習、予測を同じ順序でつなぐ仕組み |
二、ブレークスルー1:ベイズ、最尤法、EM が「不確実性」を扱えるようにした
現実の多くの問題では、データは完全に確定していません。ユーザーは迷いますし、センサーにはノイズがあります。サンプルが欠けることもありますし、ラベルが完璧でないこともあります。
このとき機械学習は、次の問いに答える必要があります。
情報が不完全でノイズもある状況で、どうすれば最も合理的な判断ができるのか?
ベイズの法則は、「新しい証拠を見たあとで判断を更新する」方法を与えてくれます。最尤推定は、観測データから最もありそうなパラメータを逆算する方法です。EM アルゴリズムはさらにやっかいな状況を扱います。つまり、データに隠れ変数や欠損情報があるときに、まず隠れた部分を推定し、そのあとでパラメータを更新し、これを繰り返します。
初心者向けには、次のようにたとえられます。
| 方法 | 生活でのたとえ | この章とのつながり |
|---|---|---|
| Bayes | 探偵が新しい証拠を見て容疑者の確率を更新する | 確率の直感、ナイーブベイズの選修 |
| MLE | 過去の売上から、もっともありそうな需要の規則を逆算する | 損失関数、パラメータ推定 |
| EM | いくつか欠けたジグソーパズルを、まず欠けた部分を推測し、そのあと全体を修正する | クラスタリング、潜在変数モデルの背景 |
この一群の方法は、第 5 章の主線で細かく導出するとは限りませんが、機械学習に確率、損失、パラメータ推定が欠かせない理由を説明してくれます。
おすすめの学習対応は次の通りです。
| 対応する場所 | 持ち帰るべきこと |
|---|---|
| 第 4 章 確率統計 | 確率は試験問題ではなく、不確実性を表す言語だと分かる |
| 本章 1.5 数学がどう本当に機械学習へ流れ込むのか | パラメータ、損失、最適化が訓練ループにつながる仕組みを理解する |
| 選修モジュール 伝統的 ML | ナイーブベイズ、LDA などの伝統的手法が確率の考え方をどう使うか学ぶ |
三、ブレークスルー2:線形モデルが「予測」を訓練可能な baseline に変えた
線形回帰とロジスティック回帰は一見シンプルですが、機械学習ではとても重要です。なぜなら、初心者がはじめて完全な訓練の流れを見ることができるからです。
- 入力特徴を受け取る
- 予測を計算する
- 誤差を測る
- パラメータを調整する
- テスト集で評価する
線形回帰は連続値の予測を扱い、ロジスティック回帰は分類確率を扱います。これらは「古いアルゴリズム」ではなく、多くの複雑なモデルの骨組みです。ニューラルネットワークも、たくさんの線形変換と非線形活性化を積み重ねたものとして理解できます。
おすすめの学習対応は次の通りです。
| 対応する場所 | この歴史的ブレークスルーで重視すべき学習ポイント |
|---|---|
| 2.2 線形回帰 | 「モデル、損失、パラメータ更新」を初めて理解する |
| 2.3 ロジスティック回帰 | 連続予測から分類確率と決定境界へ進む |
| 第 6 章 ニューラルネットワーク | ニューロンがなぜ「訓練可能な線形モデル + 活性化関数」のように見えるのかを理解する |
四、ブレークスルー3:決定木で機械学習の結果が人に読めるルールに近づいた
線形モデルは安定していますが、直感的とは限りませんし、複雑な非線形ルールを表すのは得意ではありません。決定木のブレークスルーはここにあります。
学習した規則を、説明しやすい一連の判断として組み立てる。
決定木は「20の質問」ゲームのように考えられます。モデルは毎回、ある特徴を使って分岐を選び、ノード内のサンプルをどんどん純粋にしていきます。CART などの方法は分類木と回帰木を体系化し、木モデルを機械学習の中でもっとも説明しやすいモデルの一つにしました。
ただし、単一の木にははっきりした弱点があります。深くなりすぎると、訓練データのノイズまで覚えてしまいやすいのです。ここから自然に、ランダムフォレストと Boosting へつながります。
おすすめの学習対応は次の通りです。
| 対応する場所 | この歴史的ブレークスルーで重視すべき学習ポイント |
|---|---|
| 2.4 決定木 | ルール分岐、純度、剪定、説明しやすさ |
| 4.3 バイアス・バリアンス | なぜ木が深すぎると過学習するのか |
| 5.5 Pipeline | 木モデルを完全なモデリングの流れにどう組み込むか |
五、ブレークスルー4:SVM が「境界線は安定しているべき」とはっきり示した
SVM の核心は、初心者が分類境界を理解するのにとても向いています。
2 本の線がどちらもサンプルを分けられるなら、どちらがよいのでしょうか。SVM の答えはこうです。
2 つのクラスのサンプルから、できるだけ遠い境界を選ぶ。
これが最大マージンの考え方です。訓練サンプルにぴったり張りついた危ない切り分けではなく、できるだけ安全な余裕を残すようにします。さらにカーネル法によって、SVM は非線形境界にも対応できます。
今の時代、SVM が毎回のプロジェクトで第一選択とは限りませんが、歴史的には非常に重要です。「汎化の境界」と「安定した分類」をとてもきれいに説明してくれたからです。
おすすめの学習対応は次の通りです。
| 対応する場所 | この歴史的ブレークスルーで重視すべき学習ポイント |
|---|---|
| 選修モジュール:SVM | 最大マージン、サポートベクター、カーネル法 |
| 本章 モデル評価 | 訓練スコアが高いことが、境界の安定性を意味するわけではない |
| 本章 特徴量エンジニアリング | SVM は特徴量のスケーリングに非常に敏感 |
六、ブレークスルー5:ランダムフォレストと Boosting が弱いモデルを組み合わせて強いモデルにした
単一の木は過学習しやすいですが、木には大きな利点があります。非線形性や特徴量同士の相互作用を扱えることです。そこで機械学習は、とても重要な段階に入ります。
単一モデルを信じ切るのではなく、複数のモデルを組み合わせる。
ランダムフォレストは Bagging の考え方を使い、複数の木を並列に学習させて、投票や平均で単一の木の不安定さを下げます。Boosting は順番にモデルを学習し、各ステップで前のモデルが間違えたサンプルに注目して、少しずつ誤りを直していきます。
この流れは、特に表形式データのタスクで産業向け機械学習に大きな影響を与えました。XGBoost、LightGBM、CatBoost などのツールによって、Boosting は実務やコンペで強力な baseline になりました。
おすすめの学習対応は次の通りです。
| 対応する場所 | この歴史的ブレークスルーで重視すべき学習ポイント |
|---|---|
| 2.5 集成学習 | Bagging と Boosting の違い |
| 4.1 指標の選択 | 強いモデルでも、正しい指標で比較しなければならない |
| 6.4 Kaggle 入門 | なぜ表形式データのプロジェクトは XGBoost 系モデルから始めることが多いのか |
七、ブレークスルー6:sklearn が伝統的機械学習を統一された工程にした
アルゴリズムのブレークスルーは重要ですが、工程化も同じくらい重要です。scikit-learn の価値は、たくさんのモデルを提供することだけではありません。伝統的機械学習を、とても安定した一つのインターフェースにまとめたことにあります。
model.fit(X_train, y_train)
pred = model.predict(X_test)
score = metric(y_test, pred)
これによって初心者は、まず統一された流れを学び、そのあとで各モデルの違いを少しずつ理解できます。また、プロジェクトの再現、比較、整理もしやすくなります。
おすすめの学習対応は次の通りです。
| 対応する場所 | この歴史的ブレークスルーで重視すべき学習ポイント |
|---|---|
| 1.4 Scikit-learn フレームワーク入門 | fit / predict / score の統一された考え方 |
| 5.5 Pipeline | データリークと流れの乱れを防ぐ |
| 第 6 段階のプロジェクト | 訓練、評価、レポートを再現可能なプロジェクトにする |
八、歴史的ブレークスルーを第 5 章の学習ルートに割り当てる
次の表に沿って、具体的な章へ戻って学習できます。
| 歴史的ブレークスルー | 解決した問題 | 本コースの対応章 |
|---|---|---|
| Bayes / MLE / EM | 不確実性、パラメータ推定、隠れ変数 | 第 4 章 確率統計、本章 1.5、選修 伝統的 ML |
| 線形回帰 | 連続値予測の、最も基本的で訓練可能なモデル | 2.2 線形回帰 |
| ロジスティック回帰 | 分類確率と線形決定境界 | 2.3 ロジスティック回帰 |
| CART / 決定木 | 説明しやすいルールと非線形分割 | 2.4 決定木 |
| SVM | 最大マージンと安定した分類境界 | 選修モジュール 伝統的 ML |
| Random Forest | 複数の木の投票で分散を下げる | 2.5 集成学習 |
| AdaBoost / GBDT / XGBoost | 直列的な誤り修正で表形式データの baseline を強くする | 2.5 集成学習、6.4 Kaggle |
| sklearn / Pipeline | アルゴリズムを再現可能な工程にまとめる | 1.4 sklearn、5.5 Pipeline |
九、この節を学び終えたときに身につけたい直感
機械学習の歴史は「古いアルゴリズムの一覧」ではなく、一つひとつの問題が少しずつ解かれてきた過程です。
| 以前の問題 | 新しいブレークスルー | 今あなたが鍛えるべき力 |
|---|---|---|
| 人手ルールは書き切れない | データから規則を学ぶ | タスク定義とデータ準備 |
| 一回のスコアは信用しきれない | train/test と交差検証 | モデルが汎化しているか判断する |
| 単一モデルは不安定 | 集成学習 | baseline と強いモデルを比較する |
| 流れが乱れやすい | sklearn / Pipeline | 再現可能なモデリングプロジェクトを作る |
この節を学んだあとで線形回帰、決定木、集成学習、評価を見直すと、より分かりやすくなります。これらの技術は突然出てきた名前ではなく、機械学習の歴史の中で何度も現れた現実の問題を解決するために生まれたものだと分かるはずです。