7.4.4 事前学習エンジニアリング【選択】
もし前の2節が次のことに答えていたなら:
- どんなデータを使うのか
- 何を学習目標にするのか
この節が答えるのは次のことです。
データもモデルも大きくなって、1台のマシンや1枚のGPUでは無理になったとき、事前学習をどうやって継続的かつ安定的に回し続けるのか。
ここで大事なのは、今すぐ100 GPUのクラスタを組むことではなく、
まず最も重要なエンジニアリングの直感を身につけることです。
- なぜ分割するのか
- なぜストリーミングで読むのか
- なぜ checkpoint と再開が付属機能ではないのか
- なぜスループットの安定性それ自体が学習品質の一部なのか
学習目標
- 事前学習エンジニアリングと普通の小規模実験の最大の違いを理解する
- データ分割、ストリーミング読み込み、checkpoint 再開が必要な理由を理解する
- 実行可能な例を通して「中断後に学習状態をどう復元するか」を理解する
- スループット、障害復旧、データバージョン管理の基本を身につける
一、なぜ事前学習はすぐに「モデルを書く」から「システムを作る」に変わるのか?
データが大きく、時間が長く、失敗コストが高いから
小さな実験では、たとえば次の程度で済むかもしれません。
- 数千ステップ
- 1つのローカルデータセット
- 数分または数時間
でも事前学習は通常、次のような意味を持ちます。
- とても長い学習期間
- とても大きなデータ量
- たくさんの shard
- とても高い中断コスト
このとき本当に難しいのは、モデルの forward が正しいかどうかだけではなく、
次の点です。
- データを安定して供給できるか
- 学習が中断した後に復元できるか
- 各ステップのスループットが安定しているか
たとえで言うと:1回プログラムを動かすのではなく、生産ラインを運営する
事前学習は、工場の生産ラインに似ています。
- データ分割は原材料倉庫
- dataloader はベルトコンベア
- checkpoint は生産進捗の保存
- 障害復旧は停電後の再稼働
どこか1つでも不安定だと、
全体のコストがすぐに大きくなります。
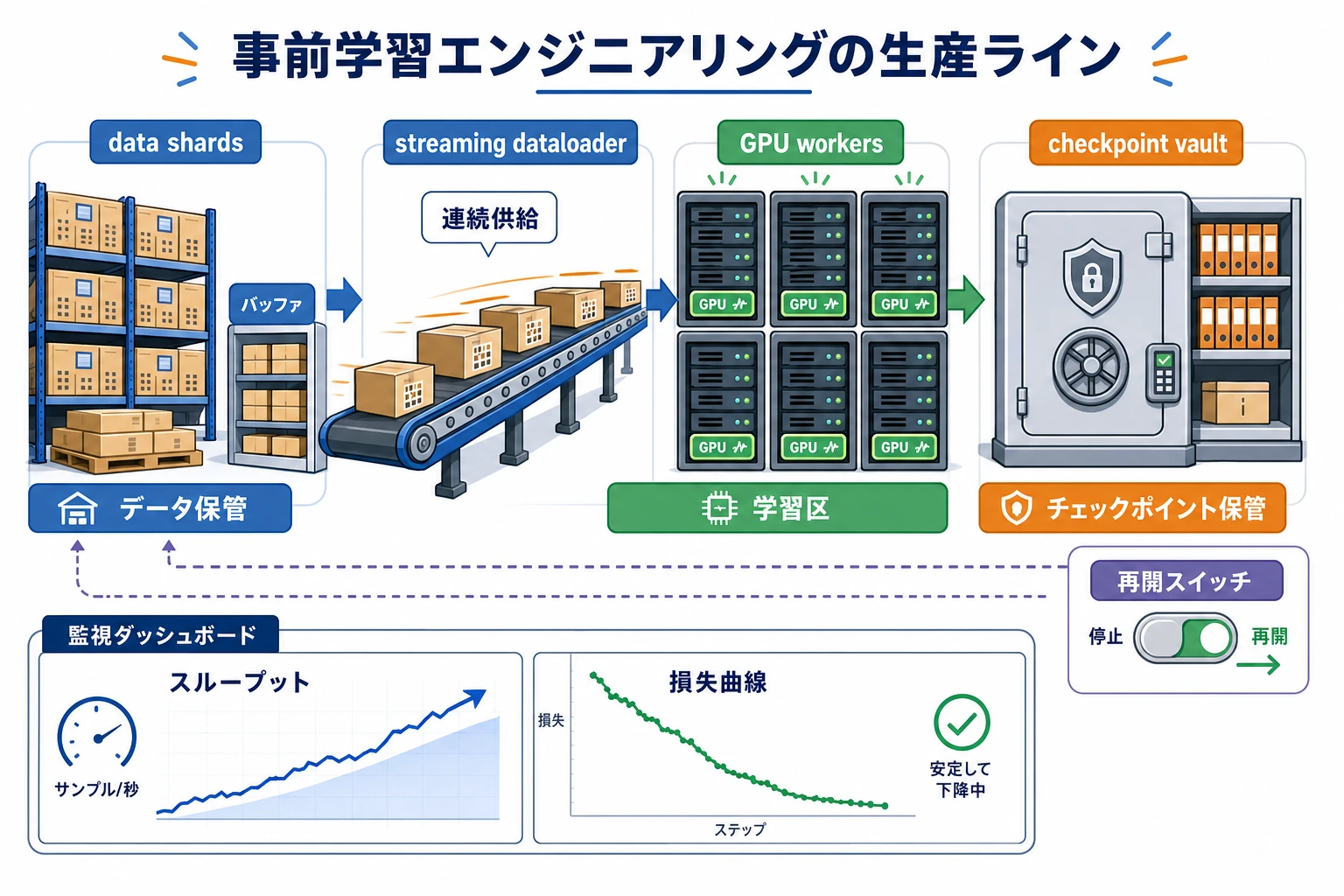
この図では、事前学習を1本の生産ラインとして見ています。shards は原材料倉庫、streaming dataloader はベルトコンベア、checkpoint は進捗の保存、resume は停電後の再稼働です。事前学習エンジニアリングの要点は、「1回動けばよい」ではなく、長時間安定して動かし続けられることです。
二、事前学習エンジニアリングで最も重要な3つの問題
データをどう入れるか?
データ量が非常に大きいときは、
通常、全部を一度にメモリへ読み込むのではなく、次のようにします。
- shard に分けて保存する
- ストリーミングで読む
- 読みながら token block にまとめる
学習が中断したらどうするか?
長時間の学習で、故障が一切起きないことを保証するのはほぼ不可能です。
そのため checkpoint は「ついでに保存するもの」ではなく、
次のものを必ず含む必要があります。
- モデルパラメータ
- optimizer の状態
- 全体の step 数
- データの読み取り位置
これが揃って初めて、中断後に混乱せずに再開できます。
なぜスループットが重要なのか?
事前学習は時間をとても使うからです。
毎秒の token スループットが安定しないと、
学習計画もコスト見積もりもずれていきます。
エンジニアリングでは、よく次の指標を追います。
- tokens/s
- step time
- data wait time
- GPU 利用率
三、まずは「分割 + 再開」の最小例を動かしてみる
以下の例では、とても小さな事前学習データの流れを再現します。
- データを shard に分ける
- 毎回1つの batch を取り出す
- 学習の途中で「中断」する
- 状態を記録してから再開する
おもちゃ版ではありますが、事前学習エンジニアリングで最も大事な再開ロジックを捉えています。
shards = {
"shard_00": ["doc_0", "doc_1", "doc_2"],
"shard_01": ["doc_3", "doc_4", "doc_5"],
"shard_02": ["doc_6", "doc_7", "doc_8"],
}
def stream_batches(shard_map, batch_size, state=None):
shard_names = sorted(shard_map)
shard_index = 0 if state is None else state["shard_index"]
sample_index = 0 if state is None else state["sample_index"]
global_step = 0 if state is None else state["global_step"]
while shard_index < len(shard_names):
shard_name = shard_names[shard_index]
shard_data = shard_map[shard_name]
while sample_index < len(shard_data):
batch = shard_data[sample_index: sample_index + batch_size]
next_sample_index = sample_index + batch_size
next_state = {
"shard_index": shard_index,
"sample_index": next_sample_index,
"global_step": global_step + 1,
}
if next_sample_index >= len(shard_data):
next_state["shard_index"] = shard_index + 1
next_state["sample_index"] = 0
yield shard_name, batch, next_state
sample_index = next_sample_index
global_step += 1
shard_index += 1
sample_index = 0
saved_state = None
print("最初の実行:")
for shard_name, batch, state in stream_batches(shards, batch_size=2):
print(f"step={state['global_step']:02d} shard={shard_name} batch={batch}")
if state["global_step"] == 3:
saved_state = state
print("クラッシュをシミュレートします。state を保存 =", saved_state)
break
print("\n再開:")
for shard_name, batch, state in stream_batches(shards, batch_size=2, state=saved_state):
print(f"step={state['global_step']:02d} shard={shard_name} batch={batch}")
期待される出力:
最初の実行:
step=01 shard=shard_00 batch=['doc_0', 'doc_1']
step=02 shard=shard_00 batch=['doc_2']
step=03 shard=shard_01 batch=['doc_3', 'doc_4']
クラッシュをシミュレートします。state を保存 = {'shard_index': 1, 'sample_index': 2, 'global_step': 3}
再開:
step=04 shard=shard_01 batch=['doc_5']
step=05 shard=shard_02 batch=['doc_6', 'doc_7']
step=06 shard=shard_02 batch=['doc_8']

なぜこのコードは「shard 名を並べるだけ」より学習価値があるのか?
これは事前学習でいちばん現実的な問題に対応しているからです。
- 学習が途中で止まったら、再開後はどこから読み直すのか?
もしモデルパラメータだけを保存して、データ位置を保存しなければ、
再開後に次のようなことが起こりえます。
- 同じデータをもう一度読む
- ある範囲のデータを飛ばしてしまう
どちらも学習の安定性に悪影響があります。
なぜ state に3つの情報を同時に持たせるのか?
ここで保存しているのは次の3つです。
shard_indexsample_indexglobal_step
それぞれ意味は次の通りです。
- どの shard を読んでいるか
- shard の中のどこまで読んだか
- 学習がどこまで進んだか
これが最小の復元可能状態です。
実際のエンジニアリングでは、ほかに何を保存するのか?
通常は次も含めます。
- モデルパラメータ
- optimizer の状態
- 学習率スケジューラの状態
- 乱数 seed
- mixed precision の scaler
四、なぜデータ分割はほぼ標準のやり方なのか?
データを一度に全部メモリへ載せるのは不可能だから
コーパスが TB 級になると、
「全部読み込んでから学習する」のは現実的ではありません。
そのため、データをたくさんの shard に分けます。
- 並列読み込みしやすい
- 障害復旧しやすい
- バージョン管理しやすい
分割は複数 worker の並列処理にも役立つ
複数 GPU や複数 worker で学習するときは、
それぞれに次のような役割を持たせられます。
- 異なる shard を読む
- 同じ shard の別区間を読む
これにより、データ供給がより安定します。
よくある落とし穴:shard の大きさが揃っていない
一部の shard が極端に大きく、別の shard が小さいと、
次のようなことが起こりやすくなります。
- すぐ読み終わる worker が出る
- いつまでも遅れる worker が出る
結果として、次のように見えます。
- スループットが揺れる
- GPU がデータ待ちになる
五、なぜ「全部 tokenize してから読む」よりストリーミング読み込みの方が現実的なのか?
前処理そのものにもコストがかかるから
大規模コーパスでは、tokenization も無料ではありません。
全部を一気に処理しようとすると、次の問題が出やすいです。
- ストレージ負荷
- データバージョンの切り替えが難しい
- やり直しコストが高い
そのため、多くのシステムでは次のような方法を取ります。
- 事前に shard 化してストリーミングする
- ある部分は事前処理、ある部分はオンライン処理にする
ただし、ストリーミング読み込みには新しい問題もある
たとえば次の通りです。
- データ順序が十分にシャッフルされているか
- 複数 worker で重複読み込みしていないか
- 中断後の再開が一貫しているか
だからこそ、データパイプライン自体を丁寧に設計する必要があります。
六、なぜスループットは学習結果に直接影響するのか?
スループットが不安定だと、多くの資源が無駄になる
各ステップの学習時間が速くなったり遅くなったりする場合、
よくある原因は次の通りです。
- dataloader が遅い
- shard 切り替えのコストが高い
- I/O が揺れる
- worker の負荷が偏っている
これは総学習時間を直接伸ばします。
もっと見えにくい問題:学習計画がずれる
事前学習は通常、次のように計画します。
- 総 token 数
- 想定 wall time
- checkpoint を打つタイミング
スループットが安定しないと、次のものもずれます。
- 学習率スケジュール
- checkpoint の周期
- 予算見積もり
とても簡単なスループットログの例
step_logs = [
{"step": 1, "tokens": 8192, "seconds": 0.40},
{"step": 2, "tokens": 8192, "seconds": 0.39},
{"step": 3, "tokens": 8192, "seconds": 0.78},
]
for log in step_logs:
tps = log["tokens"] / log["seconds"]
print(f"step={log['step']} tokens/s={tps:.0f}")
期待される出力:
step=1 tokens/s=20480
step=2 tokens/s=21005
step=3 tokens/s=10503
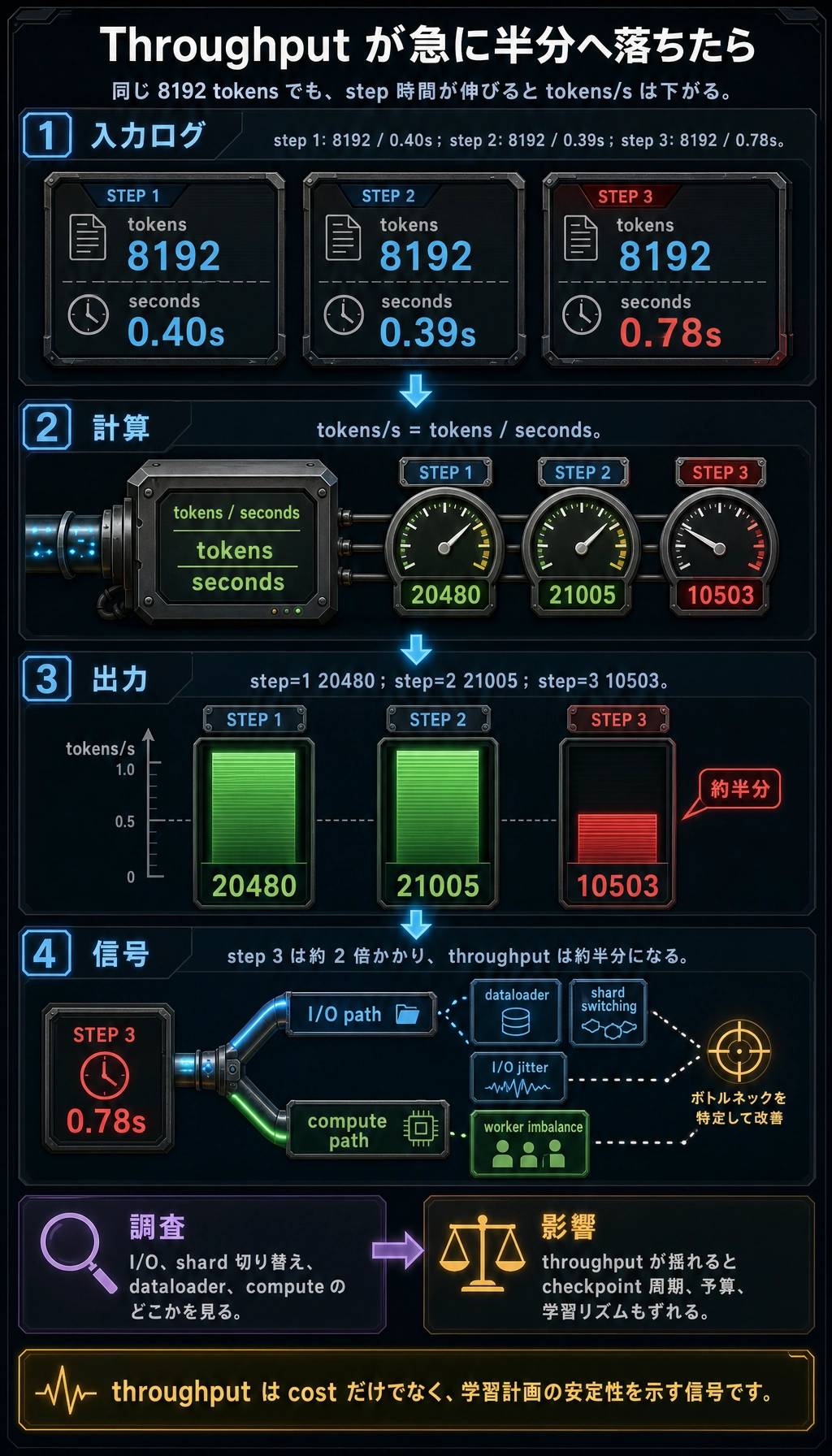
第3ステップだけ明らかに落ちているなら、
エンジニアリング上は次をさらに調べる必要があります。
- I/O の問題か
- 計算の問題か
七、事前学習エンジニアリングで見落とされやすい2つのこと
データバージョン管理
次のことを説明できなければいけません。
- 今回の学習で、どの版のデータを使ったのか
- クレンジング規則は何だったのか
- 混合比率はどうしたのか
これが曖昧だと、後で結果の変化を原因ごとに追うのがほぼ不可能になります。
復元可能性のテスト
多くのチームは次を丁寧に確認します。
- モデルを学習できるか
しかし次はあまり丁寧に確認しません。
- 中断後に安定して復元できるか
でも長時間学習では、
復元能力は「あると便利」ではなく、必要条件であることが多いです。
八、よくある誤解
誤解1:まずモデルを正しく書いて、エンジニアリングは後で足せばいい
事前学習では、エンジニアリングは後付けの飾りではありません。
実験を本当に動かすための前提です。
誤解2:checkpoint はモデルパラメータだけ保存すれば十分
十分ではありません。
データ位置と optimizer の状態がなければ、再開後に整合しない可能性があります。
誤解3:スループットはコストの問題だけで、学習品質には関係ない
スループット自体が直接 loss を決めるわけではありません。
ただし、学習計画、安定性、資源利用に影響し、
結果として全体の品質や実験の進み方に間接的に影響します。
まとめ
この節で最も大事なのは、分散学習の用語をたくさん覚えることではなく、
まず現実的な見方を持つことです。
事前学習は、少し長いスクリプトではなく、データを継続供給でき、途中で止まっても再開でき、安定したスループットを維持できるシステム工学の連鎖である。
この感覚が身につけば、
今後次のような要素を見たときも、
- データ分割
- streaming
- checkpoint
- スループット監視
それらを「周辺の雑務」とは思わなくなります。
練習
- 例の
batch_sizeを1や3に変えて、復元状態がどう変わるか観察してみましょう。 - なぜ「モデルパラメータだけ保存して、データ読み取り位置を保存しない」と、学習再開が信頼できなくなるのでしょうか?
- shard の一部がとても大きく、別の一部がとても小さいと、スループットにどんな影響がありますか?
- 自分の言葉で説明してみましょう。なぜ事前学習エンジニアリングは最終的に「モデルを書く」だけではなく「システムを作る」ことになるのでしょうか?