7.4.4 Pretraining Engineering [Optional]
If the previous two sections answered:
- What data to use
- What training objective to use
then this section answers:
When the data and model are both too large for a single machine or single GPU to be realistic, how can pretraining keep running continuously and stably?
The focus here is not to make you set up a hundred-GPU cluster right now, but to build the most important engineering intuition first:
- Why sharding is needed
- Why streaming reads are needed
- Why checkpointing and resuming are not optional features
- Why throughput stability itself is part of training quality
Learning Objectives
- Understand the biggest difference between pretraining engineering and ordinary small experiments
- Understand why data sharding, streaming reads, and checkpoint resume are necessary
- Use a runnable example to see how to recover training state after an interruption
- Build a basic understanding of throughput, fault recovery, and data version management
Why does pretraining quickly go from “writing a model” to “building a system”?
Because the data is large, the training time is long, and the cost of failure is high
In a small experiment, you might only train on:
- A few thousand steps
- One local dataset
- A few minutes or a few hours
But pretraining usually means:
- A very long training cycle
- A very large amount of data
- Many shards
- A high cost when training is interrupted
At that point, the hard part is no longer just whether the model forward pass is correct, but also:
- Can data be supplied steadily?
- Can training resume after interruption?
- Is the throughput stable at each step?
An analogy: not running a program once, but operating a production line
Pretraining is more like a factory production line:
- Data shards are like raw material warehouses
- The dataloader is like a conveyor belt
- Checkpoints are like progress save points
- Fault recovery is like restarting after a power outage
If any link is unstable, the overall cost will grow quickly.
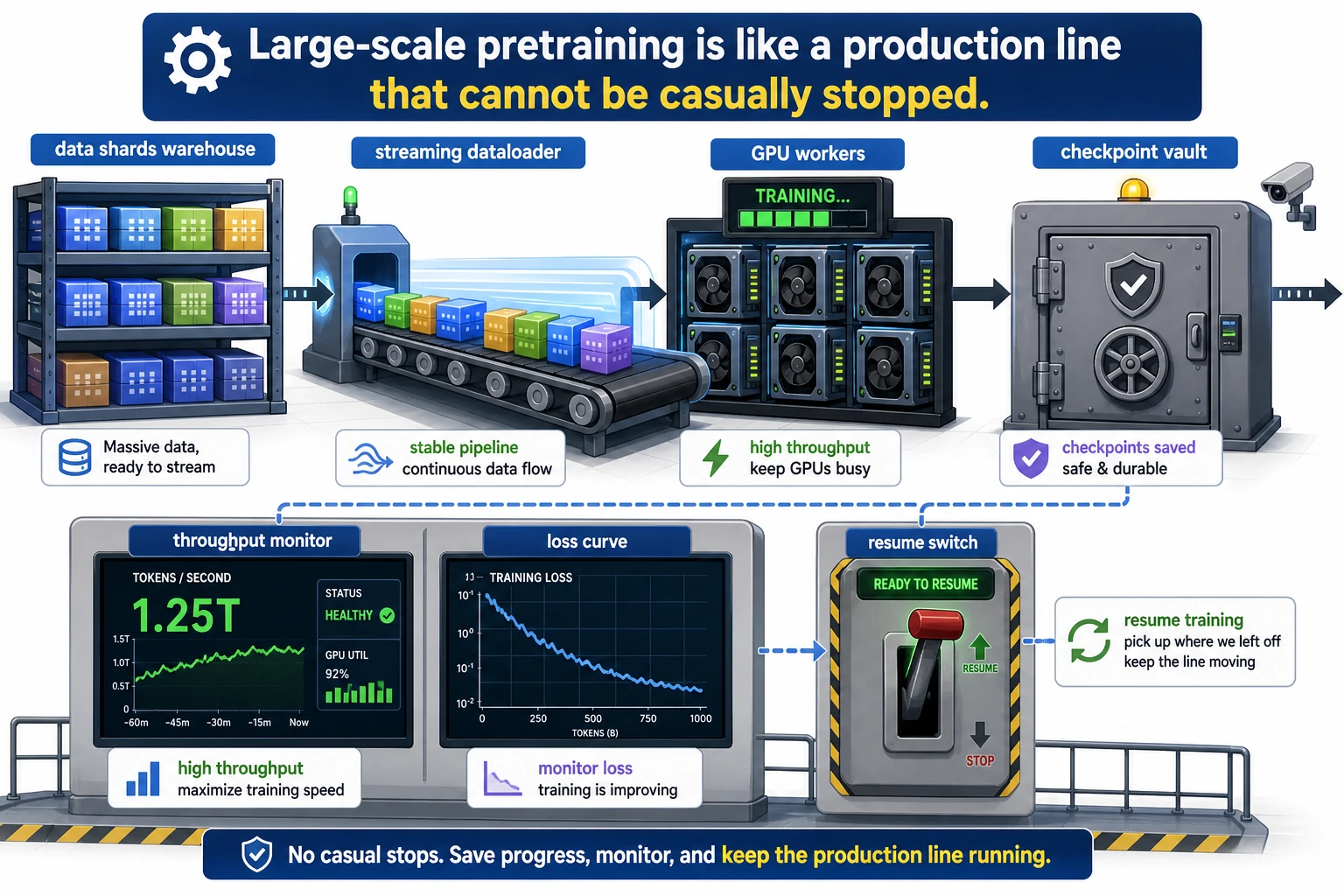
This diagram treats pretraining as a production line: shards are the raw material warehouse, the streaming dataloader is the conveyor belt, checkpoint is the progress save point, and resume is restarting after a power outage. The key to pretraining engineering is not “can it run once,” but “can it run stably for a long time.”
The three most important problems in pretraining engineering
How do you feed the data in?
When the dataset is very large, it is usually not loaded into memory all at once. Instead, people use:
- Sharded storage
- Streaming reads
- Reading and packing into token blocks on the fly
What if training is interrupted?
Long training runs can hardly guarantee that nothing will ever go wrong. So checkpointing is not just “saving occasionally,” but something that must include:
- Model parameters
- Optimizer state
- Global step count
- Data reading position
Only then can recovery after interruption be correct.
Why does throughput matter?
Because pretraining is very time-consuming. If token throughput per second is unstable, your training plan and cost estimate will drift.
In engineering practice, people often keep an eye on:
- tokens/s
- step time
- data wait time
- GPU utilization
First, run a minimal example of “sharding + resume”
The example below simulates a very small pretraining data stream:
- Data is split into shards
- One batch is taken at a time
- Training is “interrupted” halfway through
- The state is saved and then resumed
Although it is only a toy version, it captures the most important recovery logic in pretraining engineering.
shards = {
"shard_00": ["doc_0", "doc_1", "doc_2"],
"shard_01": ["doc_3", "doc_4", "doc_5"],
"shard_02": ["doc_6", "doc_7", "doc_8"],
}
def stream_batches(shard_map, batch_size, state=None):
shard_names = sorted(shard_map)
shard_index = 0 if state is None else state["shard_index"]
sample_index = 0 if state is None else state["sample_index"]
global_step = 0 if state is None else state["global_step"]
while shard_index < len(shard_names):
shard_name = shard_names[shard_index]
shard_data = shard_map[shard_name]
while sample_index < len(shard_data):
batch = shard_data[sample_index: sample_index + batch_size]
next_sample_index = sample_index + batch_size
next_state = {
"shard_index": shard_index,
"sample_index": next_sample_index,
"global_step": global_step + 1,
}
if next_sample_index >= len(shard_data):
next_state["shard_index"] = shard_index + 1
next_state["sample_index"] = 0
yield shard_name, batch, next_state
sample_index = next_sample_index
global_step += 1
shard_index += 1
sample_index = 0
saved_state = None
print("first run:")
for shard_name, batch, state in stream_batches(shards, batch_size=2):
print(f"step={state['global_step']:02d} shard={shard_name} batch={batch}")
if state["global_step"] == 3:
saved_state = state
print("simulate crash, save state =", saved_state)
break
print("\nresume:")
for shard_name, batch, state in stream_batches(shards, batch_size=2, state=saved_state):
print(f"step={state['global_step']:02d} shard={shard_name} batch={batch}")
Expected output:
first run:
step=01 shard=shard_00 batch=['doc_0', 'doc_1']
step=02 shard=shard_00 batch=['doc_2']
step=03 shard=shard_01 batch=['doc_3', 'doc_4']
simulate crash, save state = {'shard_index': 1, 'sample_index': 2, 'global_step': 3}
resume:
step=04 shard=shard_01 batch=['doc_5']
step=05 shard=shard_02 batch=['doc_6', 'doc_7']
step=06 shard=shard_02 batch=['doc_8']

Why is this code more educational than just listing a few shard names?
Because it corresponds to one of the most realistic problems in pretraining:
- If training stops halfway, where should it continue reading from after recovery?
If you only save model parameters and not the data position, recovery may:
- Re-read the same batch of data
- Or skip over part of the data directly
Both will affect training stability.
Why does state need to record three things at the same time?
Here we save:
shard_indexsample_indexglobal_step
They answer:
- Which shard has been read?
- Where inside the shard are we?
- How far has training progressed?
This is the minimal recoverable state.
What else is usually saved in real systems?
Usually also:
- Model parameters
- Optimizer state
- Learning rate scheduler state
- Random seeds
- Mixed-precision scaler
Why is data sharding almost the default approach?
Because data cannot all fit into memory at once
When the corpus reaches TB scale, “read everything into memory and then train” is simply unrealistic.
So data is split into many shards:
- Easier to read in parallel
- Easier to recover from failures
- Easier to manage versions
Sharding also helps multiple workers run in parallel
In multi-GPU or multi-worker training, different workers can:
- Read different shards
- Or read different sections of the same shard
This makes data supply more stable.
A very common pitfall: shards are too uneven
If some shards are much larger and some are much smaller, then it is easy for:
- Some workers to finish reading very quickly
- Other workers to keep dragging behind
This eventually shows up as:
- Throughput jitter
- GPUs waiting for data
Why is streaming reading more practical than “tokenize everything first, then read”?
Because preprocessing itself can be expensive
In large-scale corpora, tokenization is not free either. If you try to preprocess all the data at once, you often run into:
- Storage pressure
- Difficulty switching data versions
- High cost of rerunning
So many systems use:
- Pre-sharding + streaming reads
- Or partial preprocessing plus partial online processing
But streaming reads also bring new problems
For example:
- Whether the data order is shuffled enough
- Whether multiple workers read duplicates
- Whether checkpoint recovery is consistent
That is why the data pipeline itself must be designed very carefully.
Why does throughput directly affect training results?
Unstable throughput means many resources are wasted
If the training time per step changes a lot, common reasons may be:
- The dataloader is too slow
- Shard switching is expensive
- I/O is unstable
- Worker load is uneven
This directly slows down total training time.
A more hidden problem: the training plan becomes inaccurate
Pretraining is often planned by:
- Total training tokens
- Expected wall time
- Expected checkpoint points
If throughput is unstable, your:
- Learning rate schedule
- Checkpoint interval
- Budget estimate
may all drift as well.
A very simple throughput log example
step_logs = [
{"step": 1, "tokens": 8192, "seconds": 0.40},
{"step": 2, "tokens": 8192, "seconds": 0.39},
{"step": 3, "tokens": 8192, "seconds": 0.78},
]
for log in step_logs:
tps = log["tokens"] / log["seconds"]
print(f"step={log['step']} tokens/s={tps:.0f}")
Expected output:
step=1 tokens/s=20480
step=2 tokens/s=21005
step=3 tokens/s=10503

If you see step 3 drop significantly, engineers need to keep digging:
- Is it an I/O issue?
- Or a compute issue?
Two easily overlooked things in pretraining engineering
Data version management
If you cannot clearly state:
- Which version of the data was used for the current training run
- What the cleaning rules were
- How the mixing ratios were set
then later changes in results are almost impossible to attribute.
Recoverability testing
Many teams carefully test:
- Whether the model can be trained
but do not carefully test:
- Whether it can resume reliably after interruption
Yet for long training runs, recovery ability is often required, not optional.
Common misunderstandings
Misunderstanding 1: First write the model correctly, and fix the engineering later
For pretraining, engineering is not a later decoration, but the prerequisite for actually getting the experiment to run.
Misunderstanding 2: It is enough to save only the model parameters in a checkpoint
Not enough. Without data position and optimizer state, recovery will likely be inconsistent.
Misunderstanding 3: Throughput is only a cost issue and does not affect training quality
Throughput does not directly determine the loss, but it does affect the training plan, stability, and resource utilization, which in turn affects overall results and experiment rhythm.
Summary
The most important thing in this section is not to memorize distributed training jargon, but to build a realistic judgment first:
Pretraining is not just a slightly longer script, but a systems engineering chain that must continuously supply data, support checkpoint recovery, and maintain stable throughput.
Once you build this awareness, when you look at:
- Data sharding
- Streaming
- Checkpoints
- Throughput monitoring
you will no longer treat them as “peripheral chores.”
Exercises
- Change the
batch_sizein the example to1or3, and observe how the recovery state changes. - Why does saving only the model parameters, without saving the data reading position, make training recovery unreliable?
- Think about it: if some shards are much larger and some are much smaller, what impact will that have on throughput?
- Explain in your own words: why does pretraining engineering eventually become “building a system” rather than just “writing a model”?