8.1.5 検索戦略
学習目標
この節を終えると、あなたは次のことができるようになります。
- 検索戦略が RAG の品質を直接左右する理由を理解する
- キーワード検索、ベクトル検索、ハイブリッド検索の違いを見分ける
- rerank、query rewrite などのよく使う強化手法を理解する
- 実行可能な例でハイブリッド検索の考え方を体験する
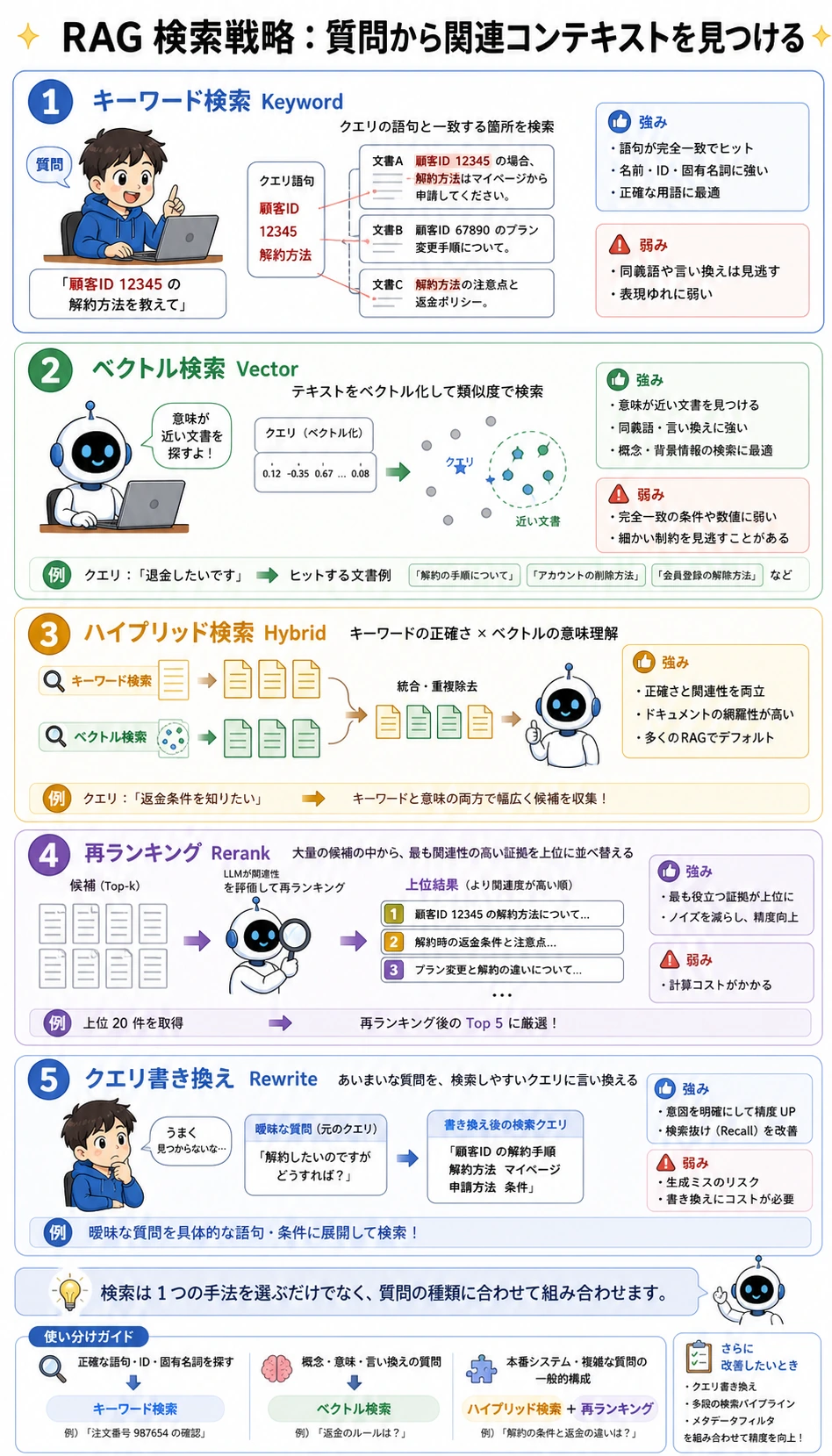
一、検索は「top-k だけ」ではない
キーワード検索:はっきりした語を探すのに向いている
キーワード検索は、もっと「目次を引く」感じです。
得意なのは次のようなものです。
- 正確な専門用語
- 製品名
- エラーコード
- 法令番号
たとえば、ユーザーがこう聞いたとします。
「エラーコード 403 って何ですか?」
このような場面では、キーワード検索はとても強いです。
ベクトル検索:意味が近い内容を探すのに向いている
ベクトル検索は、もっと「意味で似ているものを探す」感じです。
得意なのは次のようなものです。
- 同義表現
- 言い換えた質問
- 口語的な質問
たとえば、
「講座をやめたいです」
と、
「コース購入後 7 日以内なら返金申請できます」
は、使われている言葉は違いますが、ベクトル検索なら結びつけられる可能性があります。
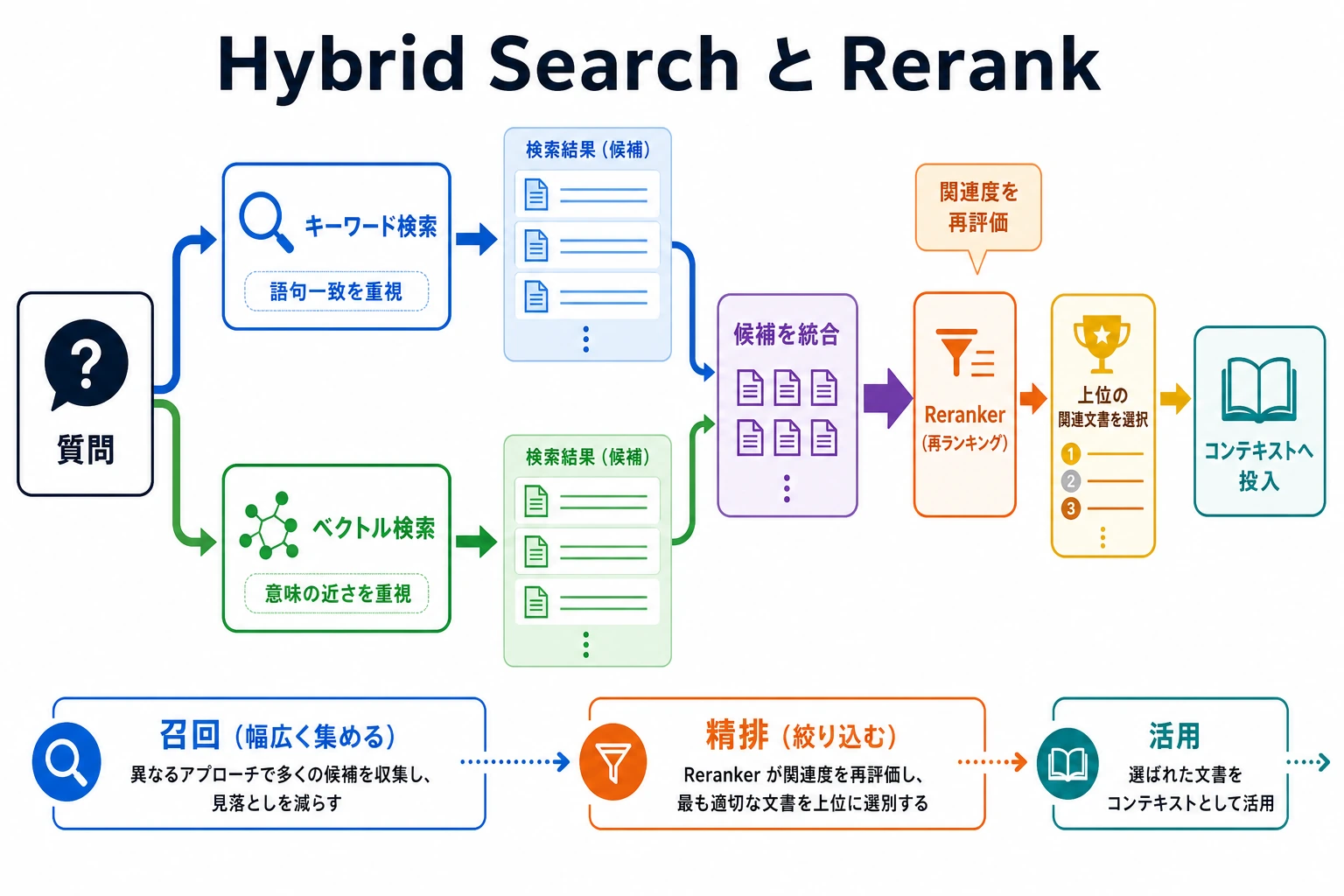
二、なぜ多くのプロジェクトは最後にハイブリッド検索へ向かうのか?
キーワードと意味には、それぞれ弱点があるから
キーワードだけを使うと、
- 意味は近いのに、表現が違う内容を取りこぼしやすい
ベクトルだけを使うと、
- とても重要な固有語を見落とすことがある
そのため、多くのシステムでは次のようにします。
キーワードスコア + ベクトルスコア = ハイブリッドスコア
これは「表面の文字」と「意味」の両方を見るのに近い
人間が資料を探すときも、だいたい同じです。
- まず明確なキーワードがあるかを見る
- 次に、同じ内容を言っているかを判断する
ハイブリッド検索は、この 2 つの判断を合わせたものです。
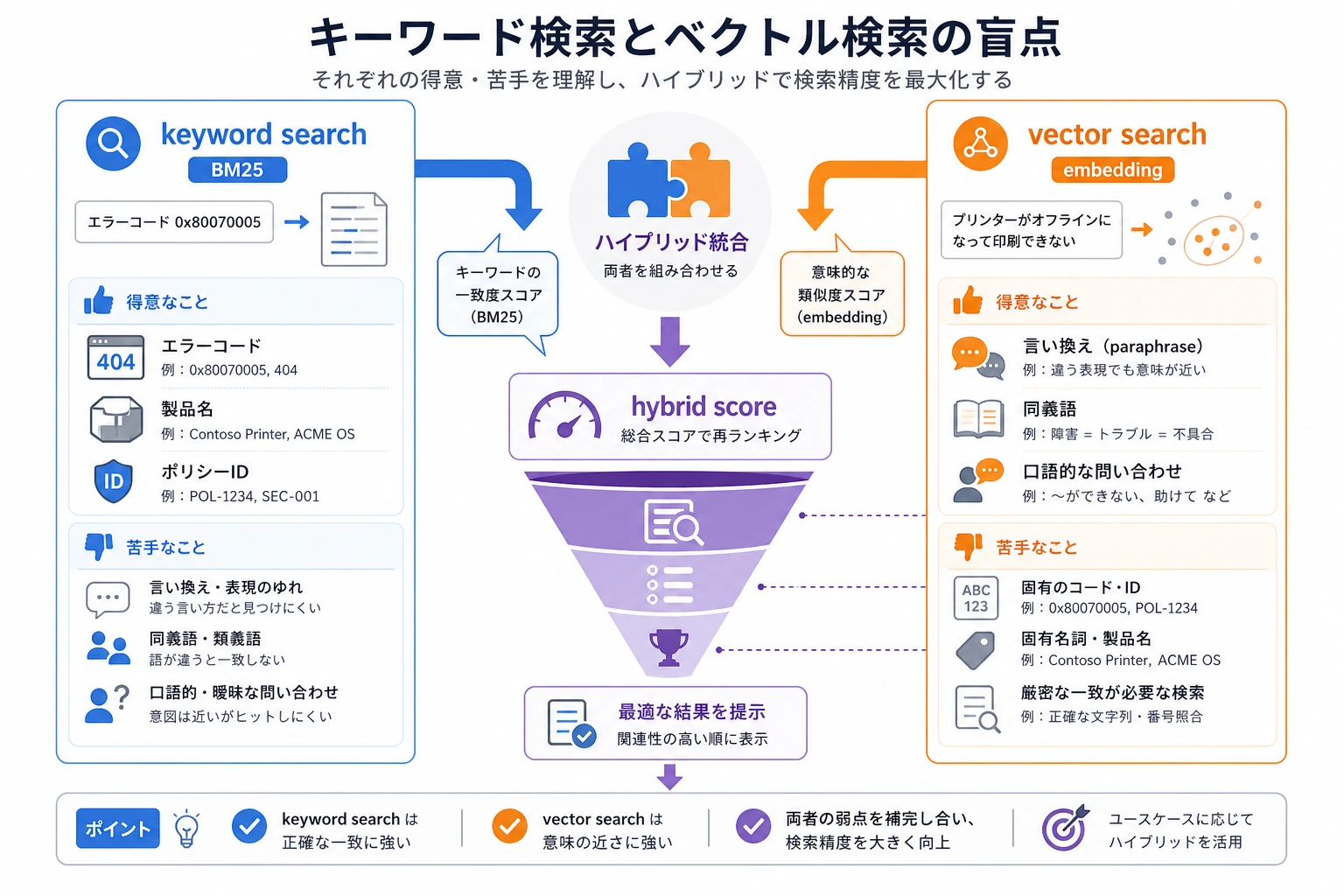
BM25 は、古典的なキーワード順位付けの方法です。多くのハイブリッド検索では、BM25 風のスコアとベクトル類似度を組み合わせ、最後に rerank で並び順を整えます。
左は「文字が一致するか」、右は「意味が近いか」を見ています。Hybrid Search の価値は複雑さではなく、エラーコード、専門用語、口語的な質問にそれぞれ通り道を作り、すべての負担を embedding に押しつけないことです。
三、最小構成のハイブリッド検索の例
次の例では、
keyword_scoreがキーワード一致をまねるvector_scoreが意味の近さをまねる- 最後に 2 つを重み付きで組み合わせる
import math
import re
from collections import Counter
import numpy as np
docs = [
{
"id": "d1",
"text": "講座購入後 7 日以内なら返金申請できます",
"vector": np.array([0.95, 0.10, 0.05])
},
{
"id": "d2",
"text": "すべてのプロジェクトを完了し、テストに合格すると証明書を取得できます",
"vector": np.array([0.10, 0.95, 0.10])
},
{
"id": "d3",
"text": "まず Python を学び、その後に機械学習と深層学習を学ぶのがおすすめです",
"vector": np.array([0.20, 0.30, 0.95])
}
]
query = "講座をやめて返金したい"
query_vector = np.array([0.90, 0.10, 0.10])
def tokenize(text):
words = re.findall(r"[a-zA-Z0-9_]+", text.lower())
cjk_chars = re.findall(r"[\u4e00-\u9fff\u3040-\u30ff]", text)
cjk_bigrams = ["".join(cjk_chars[i:i + 2]) for i in range(len(cjk_chars) - 1)]
return words + cjk_bigrams
def keyword_score(query, text):
q = Counter(tokenize(query))
t = Counter(tokenize(text))
return sum(min(q[k], t[k]) for k in q)
def cosine_similarity(a, b):
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
results = []
for doc in docs:
kw = keyword_score(query, doc["text"])
vec = cosine_similarity(query_vector, doc["vector"])
hybrid = 0.4 * kw + 0.6 * vec
results.append((hybrid, kw, vec, doc["id"], doc["text"]))
for hybrid, kw, vec, doc_id, text in sorted(results, reverse=True):
print(doc_id, "hybrid=", round(hybrid, 4), "kw=", kw, "vec=", round(vec, 4), "->", text)
期待される出力:
d1 hybrid= 1.399 kw= 2 vec= 0.9983 -> 講座購入後 7 日以内なら返金申請できます
d3 hybrid= 0.1977 kw= 0 vec= 0.3295 -> まず Python を学び、その後に機械学習と深層学習を学ぶのがおすすめです
d2 hybrid= 0.1337 kw= 0 vec= 0.2228 -> すべてのプロジェクトを完了し、テストに合格すると証明書を取得できます
この例は簡略化されていますが、実際のシステムの核心にかなり近い考え方です。
四、Rerank:まず広く集めて、あとで細かく並べ替える
なぜ rerank が必要なのか?
多くのシステムでは、最初から「一発で正確に並べる」ことを目指しません。代わりに、
- まず、比較的安い方法で候補を集める
- 次に、より強力だが高コストな方法で並べ替える
これを rerank と呼びます。
直感的なたとえ
就職活動でいうと、
- 1 次選考ではキーワードで履歴書をふるいにかける
- 2 次選考では、本当に合っているかを丁寧に見る
RAG でも同じです。
五、Query Rewrite:ユーザーの質問は、そのままだと検索に向いていないことがある
ユーザーの質問が、よい検索語とは限らない
ユーザーはこう言うかもしれません。
「この場合、まだ返金できますか?」
でも、ナレッジベースにはこう書かれているかもしれません。
「購入後 7 日以内かつ学習進捗が 20% 未満の場合は返金可能」
このとき、システムは質問を検索しやすい形に書き換えることがあります。
おもちゃ版のクエリ書き換え
def rewrite_query(query):
replacements = {
"講座をやめたい": "返金したい",
"コースをやめてもいい?": "返金できますか?",
"証明書を取りたい": "証明書を取得したい",
"講座をやめる": "返金",
"コースをやめる": "返金",
"証明書を取る": "証明書",
"卒業証書": "証明書"
}
new_query = query
for old, new in replacements.items():
new_query = new_query.replace(old, new)
return new_query
queries = ["講座をやめたい", "証明書を取りたい", "コースをやめてもいい?"]
for q in queries:
print(q, "->", rewrite_query(q))
期待される出力:
講座をやめたい -> 返金したい
証明書を取りたい -> 証明書を取得したい
コースをやめてもいい? -> 返金できますか?
実際のシステムでは、query rewrite を LLM が担当することもあります。
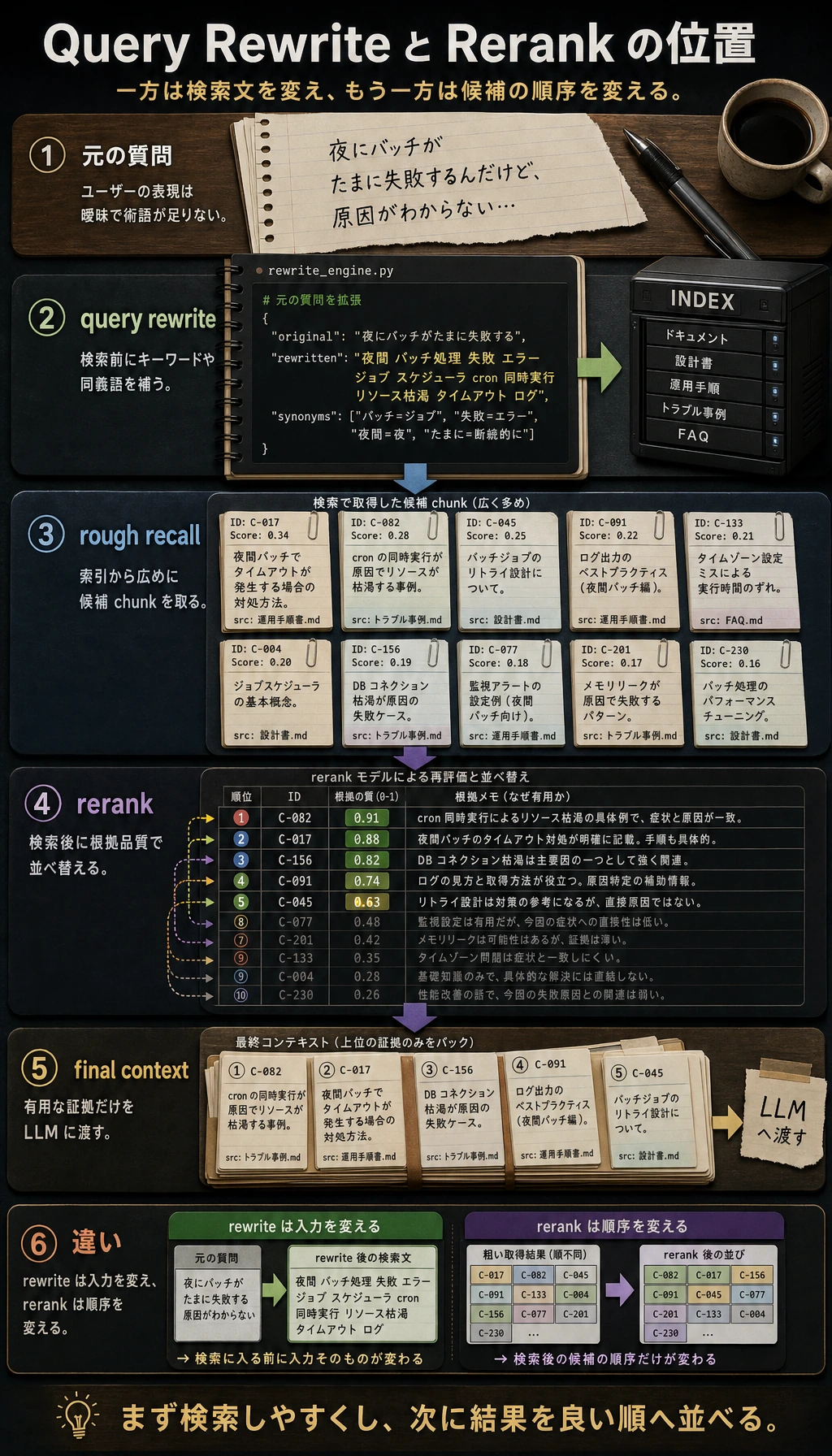
Query Rewrite は検索の前に行い、ユーザーの質問を探しやすくします。Rerank は広く集めた後に行い、候補の並びを整えます。役割は別なので、同じものとして考えないでください。
六、ほかにはどんな検索強化戦略があるのか?
Multi-query
1 つの質問を複数の言い換えに変えて、それぞれ検索し、結果をまとめます。
Metadata filter
まず業務条件で範囲を絞ってから、意味検索を行います。
Parent-child retrieval
まず小さな chunk を検索し、そのあとでより大きなまとまりや元の段落に戻ります。
Self-query retrieval
モデル自身に、必要なフィルター条件や検索フィールドを判断させます。
七、どの検索戦略を選べばいいのか?
専門用語が多い場合
次の方法をより重視します。
- キーワード検索
- ハイブリッド検索
- メタデータフィルター
ユーザーの表現がかなり口語的な場合
次の方法をより重視します。
- ベクトル検索
- query rewrite
- rerank
ナレッジベースの構造化が進んでいる場合
次のような構成も考えられます。
- まずルーティングする
- 次に対象を絞って検索する
- 最後に並べ替える
八、目標が「ナレッジベース駆動の教材生成アシスタント」なら、検索戦略はどう考えるべきか?
この種のプロジェクトでは、検索は単に「関連する内容を見つける」ことではありません。
むしろ、2 段階の選択のようなものです。
- まず、内部資料を見るか、外部資料で補うかを決める
- 次に、知識ポイントを探すのか、例題を探すのか、練習問題を探すのかを決める
そのため、検索条件は次のように整理するとよいです。
| 条件 | 何を制御するか |
|---|---|
topic | 現在のテーマ |
content_type | 概念 / 例題 / 練習 |
source_origin | 内部資料 / 外部資料 |
grade | 学年や対象者 |
この線は、まず次の一文として覚えるとよいです。
教材生成プロジェクトの検索は、単に「関連を探す」のではなく、「欄ごとに合う資料を探す」ことです。
最小のフィルター例は、まず次のように書けます。
items = [
{"topic": "割引の応用問題", "content_type": "concept", "source_origin": "internal", "text": "割引 = 定価 × 割引率"},
{"topic": "割引の応用問題", "content_type": "example", "source_origin": "internal", "text": "商品が 100 円で、2 割引の後はいくらになりますか?"},
{"topic": "割引の応用問題", "content_type": "note", "source_origin": "external", "text": "外部資料の補足:割引のよくある誤解。"},
]
hits = [
x for x in items
if x["topic"] == "割引の応用問題" and x["content_type"] in {"concept", "example"}
]
for hit in hits:
print(hit)
期待される出力:
{'topic': '割引の応用問題', 'content_type': 'concept', 'source_origin': 'internal', 'text': '割引 = 定価 × 割引率'}
{'topic': '割引の応用問題', 'content_type': 'example', 'source_origin': 'internal', 'text': '商品が 100 円で、2 割引の後はいくらになりますか?'}
この例は特に初心者に向いています。なぜなら、次のことが分かるからです。
- metadata filter は、しばしば「より大きなモデルに変える」より先に効く
九、初学者がよくやる間違い
ベクトル検索だけを試して、キーワード検索を試さない
企業の現場では、キーワード検索は弱くありません。むしろ土台になることも多いです。
検索戦略を最初から複雑にしすぎる
まずは次の順で始めるのがおすすめです。
- baseline を作る
- 明確な評価セットを用意する
- 1 回で変える戦略は 1 つだけにする
召回だけ見て、最終回答を見ない
検索スコアが高くても、最終的な答えが必ず良くなるとは限りません。
生成の段階でも結果は変わります。
検索戦略の調整表
検索を調整するときは、ただ「うまくいかない」と言うのではなく、現象を調整可能なレバーに対応づけることが大切です。
| 現象 | まず調整するもの | 理由 |
|---|---|---|
| 明確な専門用語やエラーコードが見つからない | キーワード検索またはハイブリッド検索を増やす | ベクトル検索では正確な語が弱まることがある |
| ユーザーの口語的な質問が見つからない | query rewrite、multi-query、ベクトル検索 | ユーザー表現と文書表現が一致しない |
| top-k の中で関連内容の順位が低い | rerank | 召回はできていても、並びが十分に正確でない |
| 検索結果のテーマは合っているのに版が違う | metadata filter | 版、日付、出典で範囲を絞る必要がある |
| 回答に複数の断片が必要 | parent-child retrieval、またはより適切な chunk 化 | 小さな chunk は当たっても、文脈が足りない |
この表は、評価セットと一緒に使うのに向いています。毎回 1 つだけ戦略を変え、Hit@k、MRR、引用の質、失敗サンプルの変化を記録してください。
検索実験の記録テンプレート
| 実験 | 戦略 | top-k | rerank あり | 結果 | 結論 |
|---|---|---|---|---|---|
| baseline | キーワード | 3 | いいえ | 正確な語には当たるが、同義表現を取りこぼす | エラーや専門用語に向いている |
| exp-1 | ベクトル | 3 | いいえ | 同義表現には強いが、専門用語は不安定なことがある | キーワード経路を残す必要がある |
| exp-2 | ハイブリッド | 5 | はい | 全体的に最もよいが、遅延は増える | 標準版として使える |
検索改善のポイントは、一度で完璧な戦略を見つけることではなく、変更ごとに記録があり、指標があり、失敗サンプルがある状態にすることです。
まとめ
この節で最も大切な理解は次の通りです。
RAG の「資料を探す」工程は機械的な作業ではなく、繰り返し設計し、改善できるシステムの一部です。
多くの場合、検索戦略を改善する効果は、より大きなモデルに変えることよりも直接的です。
練習
- ハイブリッド検索の例で重みを変え、キーワード重視とベクトル重視で並び順がどう変わるか比べてみましょう。
- 文書に「講座をやめる」という語を含む文を 1 つ追加し、キーワード検索の強みを観察してみましょう。
- もっと豊富な
rewrite_query()のルール表を自分で作ってみましょう。