10.2.1 Image Classification ロードマップ:Image In、Label Out
Image classification は 1 つの問いに答えます:画像全体を見て、最も適切な class は何か。
まず classification loop を見る
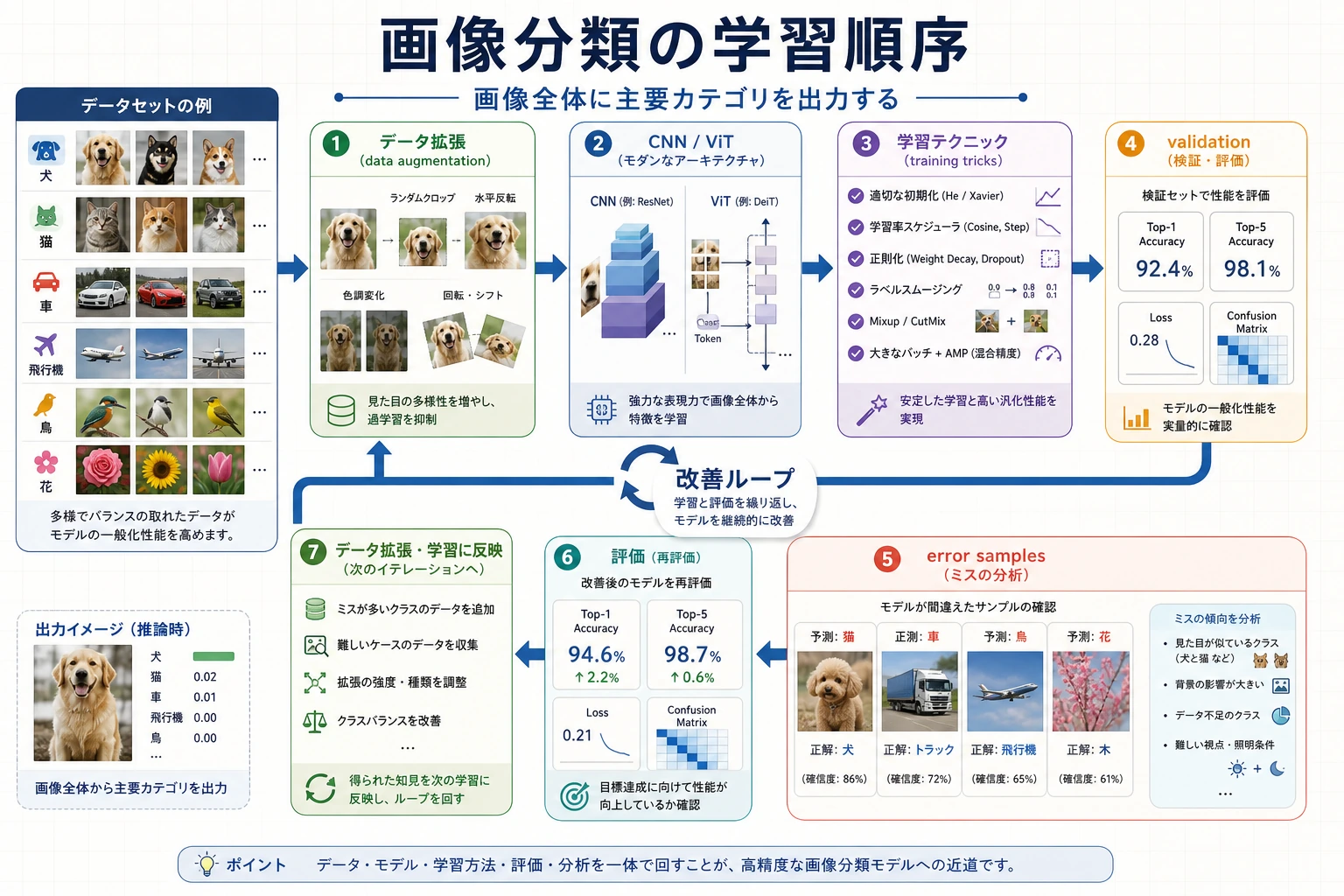
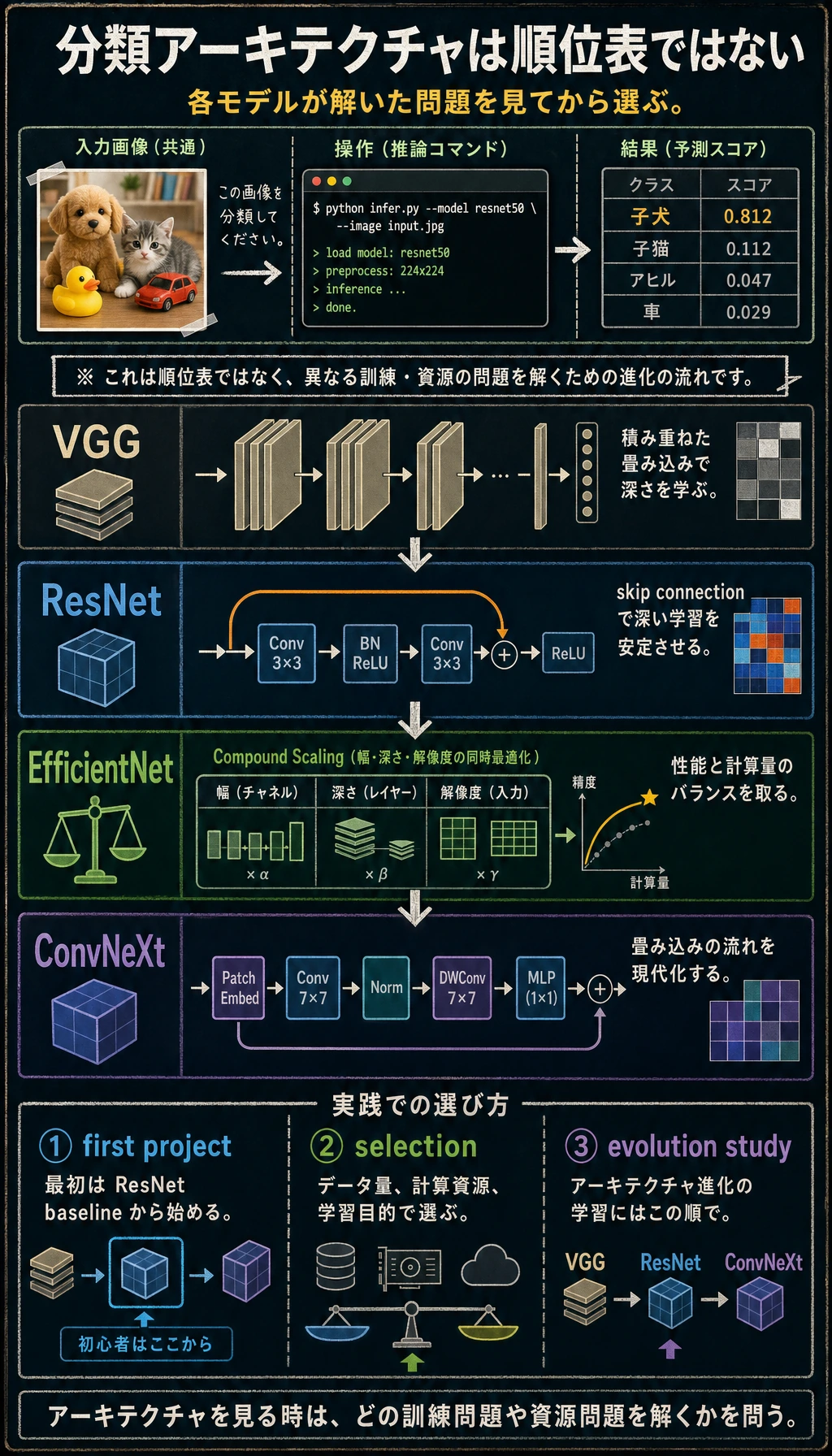

Classification は最も単純な vision output ですが、data split、augmentation、architecture、loss、metrics、error examples に依存します。
Prediction check を動かす
この script は classifier の最後の step を再現します:score が最も高い label を選びます。
labels = ["cat", "dog", "panda"]
scores = [0.12, 0.74, 0.14]
best_index = max(range(len(scores)), key=lambda index: scores[index])
print("prediction:", labels[best_index])
print("confidence:", scores[best_index])
出力:
prediction: dog
confidence: 0.74
実プロジェクトでは top class だけを見せないでください。confidence、wrong examples、confusion patterns を残します。
この順番で学ぶ
| 手順 | 読む内容 | 実践アウトプット |
|---|---|---|
| 1 | Data augmentation | class を保つ変化と risk を生む変化を説明する |
| 2 | Modern architectures | feature extractor、classifier head、pretrained backbone を比較する |
| 3 | Training techniques | split、loss、accuracy、overfitting、error samples を追跡する |
合格ライン
minimal classifier を動かし、train/validation metrics を示し、少なくとも 1 枚の failure image を説明できれば、この章は合格です。