9.3.8 代码生成与执行 Agent
很多人提到代码 Agent,第一反应是:
- 它会自动写代码
这当然是其中一部分。 但真正能工作的代码 Agent,远不只是“生成一段代码”。
它通常至少要完成一条闭环:
读上下文 -> 形成修改计划 -> 产出改动 -> 执行验证 -> 根据结果继续修。
如果没有这条闭环,系统更像代码补全器,不像真正的代码 Agent。
学习目标
- 理解代码 Agent 和普通代码生成的根本差别
- 理解代码 Agent 的最小工作循环
- 通过可运行示例理解“读-改-跑-验”为什么必须闭环
- 理解沙箱、测试和回滚在代码 Agent 里为什么关键
代码 Agent 和“让模型写代码”到底差在哪?
普通代码生成更像一次性输出
例如:
- “帮我写个快速排序”
模型输出一段代码后, 任务通常就结束了。
代码 Agent 更像在一个真实仓库里工作
它面对的任务更可能是:
- 修一个 bug
- 给函数补测试
- 改配置
- 看报错后再修第二轮
也就是说,它必须处理:
- 上下文
- 版本状态
- 运行反馈
- 错误恢复
一个类比:写样例答案 vs 真进项目修问题
“生成代码”像面试时白板写题。 “代码 Agent”更像你真的进一个仓库里:
- 先读项目
- 找文件
- 改一处
- 跑测试
- 看错误
- 再修一轮
两者难度完全不是一个层级。
代码 Agent 的最小闭环是什么?
Read:先读上下文
它通常需要知道:
- 相关文件在哪
- 函数现在怎么写
- 测试怎么组织
Plan:形成修改方案
例如:
- 改实现
- 补测试
- 调配置
Act:真正做改动
这一步才是大家最容易想到的“写代码”。
Verify:执行验证
例如:
- 跑单测
- 跑脚本
- 看输出
Repair:根据反馈继续修
这也是代码 Agent 和普通生成器最大的差别之一:
- 它会读执行反馈,再进入下一轮
先跑一个最小的“代码 Agent 闭环”示例
下面这个例子不会真的改文件, 但它会完整模拟一条非常重要的循环:
- 发现函数实现有 bug
- 生成补丁函数
- 跑测试
- 如果测试通过,就接受改动
def buggy_discount(price, discount_rate):
# 错误:把 8 折当成减 8
return price - discount_rate
def generate_patch():
def fixed_discount(price, discount_rate):
return price * discount_rate
return fixed_discount
def run_tests(fn):
cases = [
((100, 0.8), 80.0),
((50, 0.5), 25.0),
]
failures = []
for args, expected in cases:
actual = fn(*args)
if actual != expected:
failures.append(
{
"args": args,
"expected": expected,
"actual": actual,
}
)
return failures
current_impl = buggy_discount
failures = run_tests(current_impl)
print("before patch failures:", failures)
if failures:
candidate_impl = generate_patch()
candidate_failures = run_tests(candidate_impl)
print("after patch failures:", candidate_failures)
if not candidate_failures:
current_impl = candidate_impl
print("patch accepted")
预期输出:
before patch failures: [{'args': (100, 0.8), 'expected': 80.0, 'actual': 99.2}, {'args': (50, 0.5), 'expected': 25.0, 'actual': 49.5}]
after patch failures: []
patch accepted
这段代码在真实世界里对应什么?
它对应的是代码 Agent 最核心的一条闭环:
- 不是只产出代码
- 而是要让代码接受验证
这一步一旦缺失, 系统就很容易:
- 写了看似合理的代码
- 但根本不能跑
为什么 run_tests 比 generate_patch 更值得重视?
因为真正把系统拉回现实的, 往往不是生成能力,而是验证能力。
没有验证,代码 Agent 很容易停留在:
- 看起来像对
为什么这就是 Agent 而不只是“函数替换”?
因为它有:
- 当前状态
- 候选动作
- 外部反馈
- 决策更新
这已经是一个最小的 agentic loop。
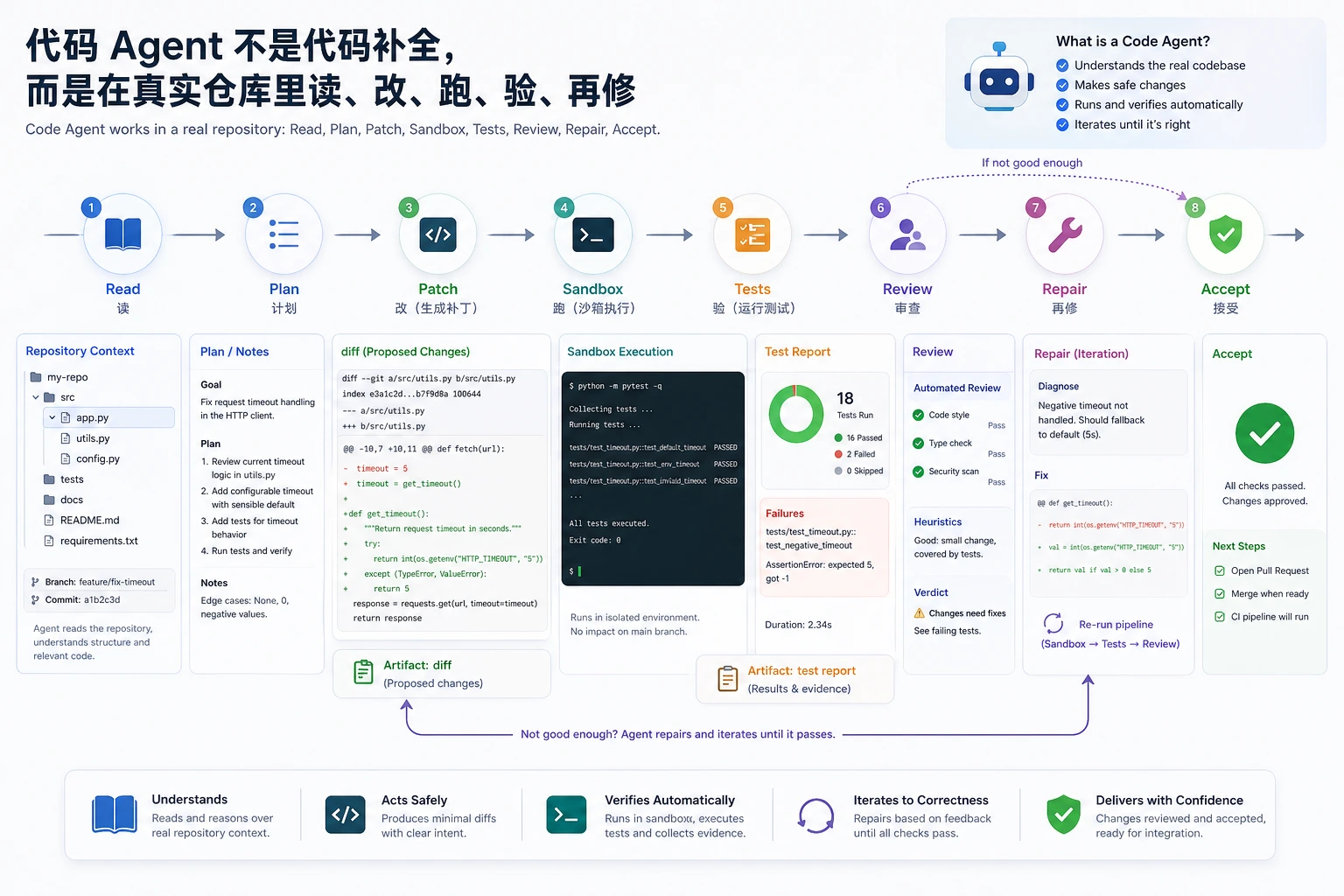
代码 Agent 的重点不是“会写代码”,而是能在沙箱里读上下文、生成 patch、跑测试、看失败、再修一轮。图中的 Verify 和 Review 是把想法拉回现实的关键。
真实代码 Agent 还会多出哪些关键环节?
文件定位与读取
真实仓库里首先要解决的是:
- 改哪个文件
- 看哪段实现
- 哪些测试相关
Patch 形式而不是整文件重写
更稳的做法通常是:
- 生成 patch
- 或局部 diff
因为这样:
- 改动更小
- 更容易 review
- 更容易回滚
执行环境隔离
代码 Agent 很多时候需要:
- 跑代码
- 跑测试
- 读写文件
这就涉及:
- 沙箱
- 权限边界
- 超时
回滚和重试
如果候选补丁跑挂了, 系统最好能:
- 保留原始版本
- 丢弃失败改动
- 再试下一种修法
为什么代码 Agent 特别依赖验证?
因为代码任务往往有客观反馈
相比纯文本任务,代码任务的一个巨大优势是:
- 很多时候能跑出明确结果
例如:
- 测试是否通过
- 程序是否报错
- 输出是否符合预期
这让代码 Agent 非常适合“试错式迭代”
它可以:
- 先改一版
- 跑反馈
- 根据失败再修
这也是为什么代码 Agent 往往是 Agent 系统里最容易形成强闭环的一类。
但也不能过度乐观
因为“测试通过”不一定等于:
- 没有回归
- 逻辑真的完备
所以验证虽然很强, 但仍然不是万能。
代码 Agent 最常见的失败点
没读懂上下文就改
这会导致:
- 改错文件
- 改坏接口约定
- 和现有风格冲突
只修表面报错,不理解根因
典型表现是:
- 补一个 if
- 压掉异常
- 让测试“刚好过”
但真正问题还在。
验证不充分
例如只跑单个 happy path, 没有覆盖:
- 边界输入
- 回归风险
- 相关模块
代码 Agent 在工程上最该守住什么?
可回滚
任何自动改动都应该:
- 能撤销
小步提交
越小的 patch 越容易:
- review
- 定位问题
- 做下一轮修复
明确边界
例如:
- 只能改指定目录
- 只能跑某些命令
- 高风险命令必须人工确认
小结
这节最重要的,不是把代码 Agent 理解成“会写代码的模型”, 而是理解它真正的闭环:
代码 Agent 的核心,是围绕真实仓库上下文,在读、改、跑、验、再修之间形成稳定循环。
只要这条闭环理解清楚了, 你后面再看更复杂的:
- 自动修 bug
- 自动补测试
- 自动重构
都会知道它们真正难在哪。
练习
- 把示例里的
buggy_discount换成你自己的 bug 函数,再设计一版 patch。 - 为什么说代码 Agent 比普通代码生成更依赖“反馈闭环”?
- 想一想:如果没有测试,代码 Agent 还能依赖什么验证方式?
- 为什么 patch 越小,通常越适合代码 Agent?