9.3.3 工具描述与发现
很多人做 Agent 时,会先把工具函数接好,然后让模型自己选。 结果很快就会发现:
- 工具很多时容易选错
- 名字相近的工具容易混淆
- 参数不知道该怎么填
问题往往不在模型“不会调用”,而在于:
工具本身没有被描述清楚。
所以工具层真正的第一步,不是执行,而是:
- 描述
- 注册
- 发现
一个更适合新人的总类比
你可以把工具描述理解成:
- 给一个很大的工具箱贴清楚标签
如果工具箱里有很多把长得差不多的螺丝刀, 但每把都只写了模糊名字, 那人和模型都会很容易拿错。
所以工具描述的意义不是“多写点字段”,而是:
- 让系统更容易在正确场景里拿到正确工具
学习目标
- 理解为什么工具元数据会直接影响调用质量
- 学会设计更清楚的工具描述结构
- 理解工具发现是如何把“用户需求”映射到“候选工具”的
- 通过可运行示例看懂一个最小工具注册与发现系统
为什么工具不能只靠函数名存在?
对程序员来说够清楚,对模型不一定
比如下面两个函数名:
search_docssearch_policy
人类工程师也许很快能看出差别, 但模型并不知道:
- 哪个更适合查退款规则
- 哪个更适合查知识库文章
- 两者参数是否一样
如果缺少描述,模型看到的只是两个看起来相近的名字。
工具描述本质上是在降低歧义
一个好工具描述,至少应该回答:
- 这个工具是干什么的
- 它适合什么场景
- 需要哪些参数
- 返回什么结构
- 权限和风险等级如何
这些信息越清楚, 模型就越容易做出稳定选择。
一个类比:商场导购比货架编号更重要
工具注册表很像商场导购手册。
- 函数名像货架编号
- 描述像导购说明
只有编号,没有说明, 用户和模型都很容易找错东西。
一个工具描述至少应包含什么?
名字要体现用途,而不是只体现实现细节
例如:
query_42很差search_refund_policy更好
因为模型在选择工具时,更依赖语义而不是实现细节。
描述要写清“什么时候用”
不要只写:
- 查询政策
更好的写法是:
- 查询退款、发票、地址修改等售后政策类规则,不适合查询订单实时状态
这能直接降低误调用。
参数说明要回答“如何填”
例如:
- 参数名是什么
- 类型是什么
- 举例值是什么
- 是否必须传
返回结构最好也有约定
如果工具返回结构完全随意, 模型和调度器后面都很难稳定处理。
所以最好明确:
- 成功时字段
- 失败时字段
- 错误码或错误类型
一个很适合初学者先记的工具说明卡
| 字段 | 它最少应该回答什么 |
|---|---|
| name | 工具叫啥,最好语义清楚 |
| description | 什么时候该用,什么时候不该用 |
| required_args | 参数怎么填 |
| returns | 成功后会拿到什么 |
| risk_level | 风险高不高,是否需要更严格控制 |
这个表很适合新人,因为它能把“工具描述”从抽象概念变成一个可检查的清单。
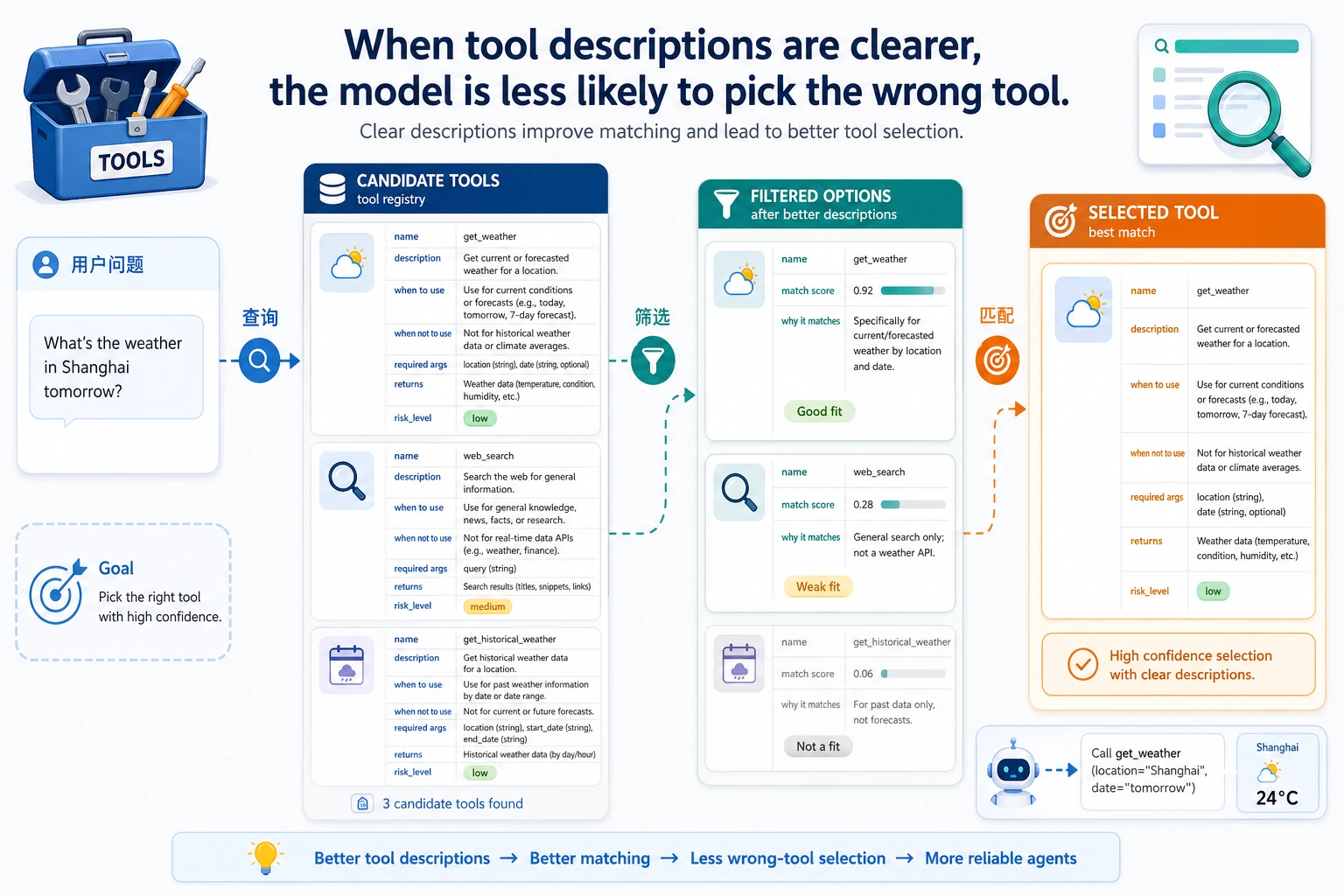
把工具描述想成“给模型看的说明书”。图里每个字段都在减少歧义:什么时候用、什么时候不用、参数怎么填、返回什么、风险多高。
先跑一个真正像样的工具注册表示例
下面这段代码会做三件事:
- 注册工具元数据
- 根据 query 和 tags 做最小发现
- 返回候选工具列表
它比只打印一个工具数组更有教学意义,因为它已经体现出:
- “工具描述”如何参与决策
TOOL_REGISTRY = [
{
"name": "search_refund_policy",
"description": "查询退款、发票、地址修改等售后政策规则",
"tags": ["policy", "refund", "invoice", "after_sales", "退款", "发票", "售后"],
"required_args": ["keyword"],
"returns": ["policy_text"],
"risk_level": "low",
},
{
"name": "get_order_status",
"description": "查询订单当前状态,例如未发货、已发货、已签收",
"tags": ["order", "status", "shipping", "after_sales", "订单", "发货", "状态"],
"required_args": ["order_id"],
"returns": ["order_status"],
"risk_level": "medium",
},
{
"name": "calculator",
"description": "做确定性数值计算,例如加减乘除和折扣金额计算",
"tags": ["math", "price", "discount", "calculation", "计算", "价格", "折扣", "多少"],
"required_args": ["expression"],
"returns": ["result"],
"risk_level": "low",
},
]
def discover_tools(query, registry, top_k=2):
cleaned = query.lower().replace("?", "").replace("?", "")
compacted = cleaned.replace(" ", "")
words = set(cleaned.split())
words.update(compacted[i : i + 2] for i in range(max(len(compacted) - 1, 0)))
scored = []
for tool in registry:
text = " ".join([tool["name"], tool["description"], " ".join(tool["tags"])]).lower()
score = sum(word in text for word in words)
scored.append((tool["name"], score))
scored.sort(key=lambda item: item[1], reverse=True)
return scored[:top_k]
queries = [
"退款政策是什么",
"订单现在发货了吗",
"299 打 8 折再减 5 等于多少",
]
for query in queries:
print(query, "->", discover_tools(query, TOOL_REGISTRY))
预期输出:
退款政策是什么 -> [('search_refund_policy', 2), ('get_order_status', 0)]
订单现在发货了吗 -> [('get_order_status', 2), ('search_refund_policy', 0)]
299 打 8 折再减 5 等于多少 -> [('calculator', 1), ('search_refund_policy', 0)]
这段代码到底在教什么?
它在教两件特别重要的事:
- 工具不是“裸函数”,而是带元数据的对象
- 工具发现本质上是在“需求”和“工具描述”之间做匹配
为什么 tags 很有用?
因为用户不一定会用和工具名完全一样的词。 例如:
- 用户说“发货了吗”
- 工具名里可能叫
get_order_status
如果没有 tags,发现阶段就容易漏掉候选工具。
为什么这里只返回候选,而不是直接执行?
因为“发现”只是第一步。 它解决的是:
- 哪些工具值得进入候选集
后面通常还要继续做:
- 参数补全
- 工具选择
- 执行和校验
再看一个最小“候选工具筛选表”示例
query = "退款政策是什么"
candidates = discover_tools(query, TOOL_REGISTRY)
for item in candidates:
print({"query": query, "candidate_tool": item[0], "score": item[1]})
预期输出:
{'query': '退款政策是什么', 'candidate_tool': 'search_refund_policy', 'score': 2}
{'query': '退款政策是什么', 'candidate_tool': 'get_order_status', 'score': 0}
这个示例很适合初学者,因为它会帮助你先看到:
- 工具发现阶段真正产出的不是答案
- 而是一组候选动作
真实系统里“发现”通常不止一种方式
关键词 / 标签匹配
这是最直观的一层,优点是:
- 简单
- 可解释
缺点是:
- 语义泛化弱
向量检索式工具发现
当工具很多时, 常见做法会变成:
- 把工具描述做成 embedding
- 对用户意图做向量匹配
这样更适合:
- 工具数量大
- 工具描述比较长
显式路由规则
在一些高风险系统里, 甚至不会把工具发现完全交给模型, 而会先加规则:
- 订单类请求先看订单工具
- 删除类操作必须进人工确认
这说明工具发现不是纯召回问题, 也是策略问题。
第一次做工具系统时,最稳的默认顺序
更稳的顺序通常是:
- 先把工具描述写清楚
- 先做最简单的候选召回
- 先看候选集是不是合理
- 再补参数填充和执行
这样会比一开始就盯模型能不能“自动选对”更稳。
返回结构为什么也属于“工具描述”的一部分?
因为发现不只是“找到工具”,还要知道能不能接上后续流程
例如:
search_refund_policy返回policy_textget_order_status返回order_status
如果后续系统需要把它们整合到同一个答复里, 返回字段越清楚,后面越稳。
一个简单的统一返回约定
def normalize_tool_result(ok, data=None, error=None):
return {
"ok": ok,
"data": data or {},
"error": error,
}
print(normalize_tool_result(True, data={"policy_text": "7 天内可退款"}))
print(normalize_tool_result(False, error="missing_order_id"))
预期输出:
{'ok': True, 'data': {'policy_text': '7 天内可退款'}, 'error': None}
{'ok': False, 'data': {}, 'error': 'missing_order_id'}
统一返回结构的好处是:
- 调度器更容易处理
- 日志更容易分析
- Agent 更容易读 observation
工具描述最容易踩的坑
误区一:函数签名清楚就够了
对程序员可能够, 对模型通常不够。
误区二:工具描述越短越好
太短会导致歧义。 描述真正重要的是:
- 精准
- 可区分
而不是一味短。
误区三:发现只要能召回一个工具就行
如果候选集质量差, 后面的选择和执行都会跟着差。
所以工具发现是系统质量的重要前置层。
如果把它做成笔记或项目,最值得展示什么
最值得展示的通常不是:
- 一堆工具函数定义
而是:
- 工具说明卡
- 用户问题 -> 候选工具列表
- 为什么某个工具被排在前面
- 工具返回结构怎么统一
这样别人会更容易看出:
- 你理解的是工具系统的发现层
- 不只是把函数接进模型
小结
这节最重要的,不是记住多少字段名, 而是建立一个清楚判断:
Agent 之所以能稳定选工具,不是因为模型“神奇地懂了所有函数”,而是因为工具被描述成了可发现、可区分、可校验的对象。
只要这条主线建立起来, 后面你再学:
- 工具路由
- 工具安全
- 多工具协作
就会知道为什么“先把工具描述清楚”是第一步。
练习
- 给示例里的注册表再加一个
search_faq工具,看看它和search_refund_policy会不会产生混淆。 - 为什么说 tags 往往比工具名更适合做第一层召回?
- 想一想:一个高风险工具的描述里,除了用途和参数,你还会额外写什么?
- 如果工具越来越多,你会优先加强“工具描述”还是“工具执行器”?为什么?