9.3.3 ツールの説明と発見
Agent を作るとき、多くの人はまずツール関数をつなぎ、そのあとモデルに自分で選ばせます。
すると、すぐに次のような問題が起きます。
- ツールが多いと選び間違えやすい
- 似た名前のツールを混同しやすい
- どのパラメータを入れればいいか分からない
問題はたいてい、モデルが「呼び出せない」ことではなく、次の点にあります。
ツールそのものの説明が不十分。
そのため、ツール層の本当の最初の一歩は実行ではなく、次の3つです。
- 説明する
- 登録する
- 発見できるようにする
初学者向けの、より分かりやすい全体イメージ
ツールの説明は、こんなふうに考えると分かりやすいです。
- 大きな工具箱に、分かりやすいラベルを貼る
もし工具箱の中に、よく似たドライバーがたくさん入っていて、
それぞれにあいまいな名前しか書かれていなければ、
人もモデルも簡単に取り違えてしまいます。
つまり、ツール説明の意味は「項目をたくさん増やすこと」ではなく、次のことです。
- システムが正しい場面で正しいツールを選びやすくすること
学習目標
- ツールの metadata が呼び出し品質に直接影響する理由を理解する
- より分かりやすいツール説明の構造を設計できるようにする
- ツール発見が「ユーザーの要求」を「候補ツール」にどう対応づけるかを理解する
- 実行できるサンプルを通して、最小限のツール登録・発見システムを理解する
なぜツールは関数名だけでは足りないのか?
プログラマーには十分でも、モデルには十分とは限らない
たとえば、次の2つの関数名を見てください。
search_docssearch_policy
人間のエンジニアなら、すぐに違いが分かるかもしれません。
でもモデルは次のことを知りません。
- どちらが返金ルールの確認に向いているのか
- どちらがナレッジベース記事の確認に向いているのか
- 両方の引数が同じなのか
説明がなければ、モデルに見えるのは「似た名前の2つの関数」だけです。
ツール説明の本質は、あいまいさを減らすこと
よいツール説明は、少なくとも次の5つに答える必要があります。
- このツールは何をするのか
- どんな場面で使うのか
- どのパラメータが必要か
- 何を返すのか
- 権限やリスクはどの程度か
これらが明確であるほど、
モデルは安定して選びやすくなります。
たとえ話:棚番号より売り場案内のほうが大事
ツール登録表は、商業施設の案内図のようなものです。
- 関数名は棚番号のようなもの
- 説明は案内文のようなもの
番号だけあって説明がなければ、
ユーザーもモデルも簡単に間違えてしまいます。
ツールの説明には少なくとも何が必要か?
名前は「実装」ではなく「用途」が伝わるようにする
たとえば:
query_42はよくないsearch_refund_policyのほうがよい
なぜなら、モデルがツールを選ぶときは、実装の細かさよりも意味を重視するからです。
説明には「いつ使うか」を書く
単に次のように書くだけでは不十分です。
- 政策を検索する
よりよい書き方は次のようになります。
- 返金、請求書、住所変更などのアフターサービス規則を検索する。注文のリアルタイム状態の確認には使わない。
これだけで、誤った呼び出しをかなり減らせます。
パラメータ説明は「どう入れるか」に答える
たとえば、次の情報が必要です。
- パラメータ名
- 型
- 例の値
- 必須かどうか
返却構造にもルールがあるとよい
ツールの返却構造が毎回バラバラだと、
モデルもスケジューラも後で安定して扱いにくくなります。
そのため、次を明確にしておくとよいです。
- 成功時のフィールド
- 失敗時のフィールド
- エラーコードやエラー種別
初学者がまず覚えるとよいツール説明カード
| フィールド | 最低限、何に答えるべきか |
|---|---|
| name | ツール名。できれば意味が分かりやすいこと |
| description | いつ使うべきか、いつ使うべきでないか |
| required_args | パラメータをどう入れるか |
| returns | 成功したときに何が得られるか |
| risk_level | リスクが高いか、より厳しく制御すべきか |
この表は初心者にとても向いています。
「ツール説明」という抽象的な概念を、確認できるチェックリストに変えられるからです。
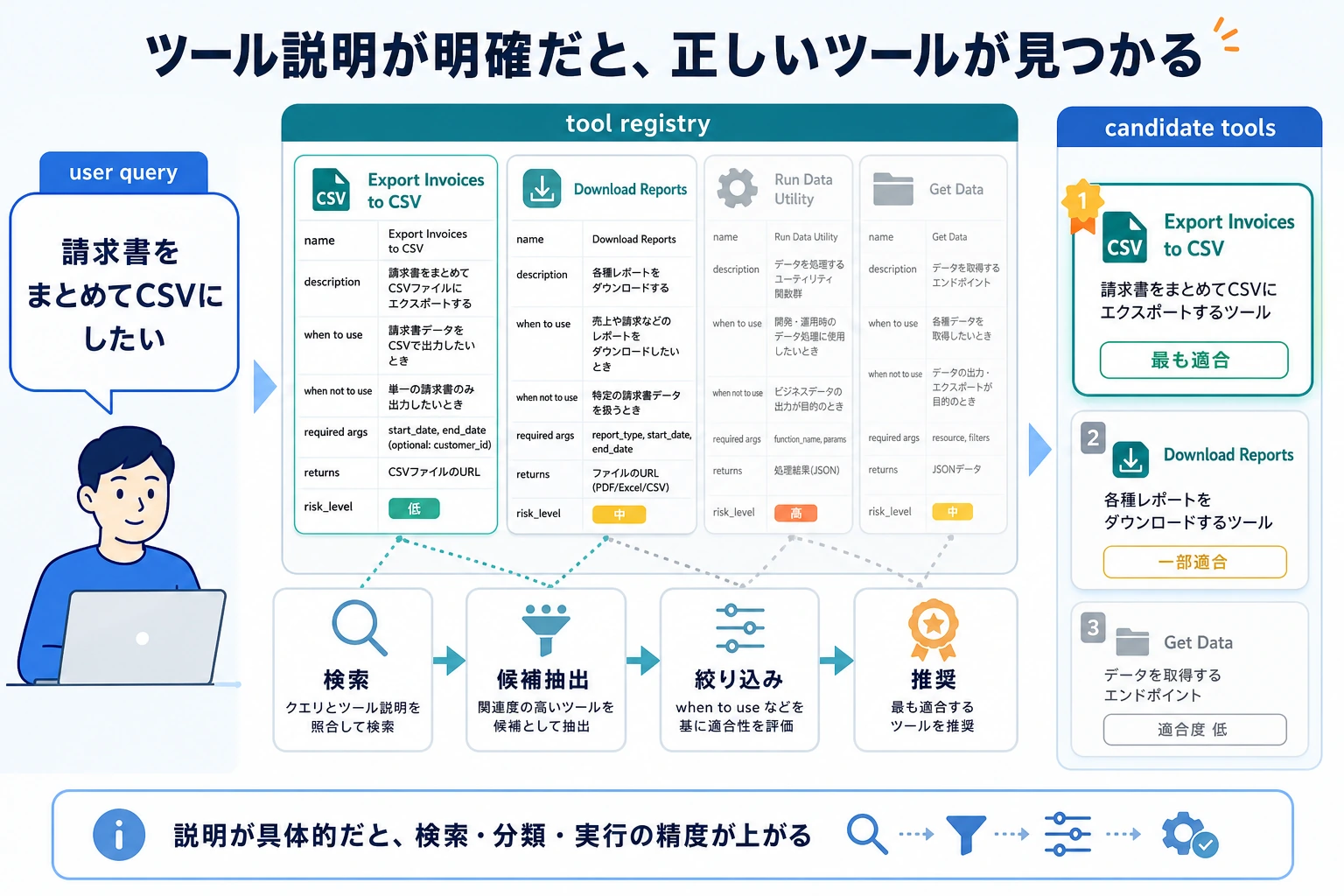
ツール説明は「モデル向けの説明書」だと考えてください。図の各項目は、あいまいさを減らしています。いつ使うか、いつ使わないか、パラメータをどう入れるか、何が返るか、どれくらい危険か、という点です。
まずは、ちゃんとしたツール登録表の例を見てみよう
以下のコードは3つのことを行います。
- ツールの metadata を登録する
- query と tags に基づいて最小限の発見を行う
- 候補ツール一覧を返す
単にツール配列を表示するだけより、学習効果があります。
なぜなら、ここではすでに次の点が見えるからです。
- 「ツール説明」がどのように意思決定に関わるか
TOOL_REGISTRY = [
{
"name": "search_refund_policy",
"description": "返金、請求書、住所変更などのアフターサービス規則を検索する",
"tags": ["policy", "refund", "invoice", "after_sales", "返金", "請求書", "サポート"],
"required_args": ["keyword"],
"returns": ["policy_text"],
"risk_level": "low",
},
{
"name": "get_order_status",
"description": "注文の現在状態を確認する。たとえば、未発送、発送済み、配達済みなど",
"tags": ["order", "status", "shipping", "after_sales", "注文", "発送", "状態"],
"required_args": ["order_id"],
"returns": ["order_status"],
"risk_level": "medium",
},
{
"name": "calculator",
"description": "加減乗除や割引額の計算など、決定的な数値計算を行う",
"tags": ["math", "price", "discount", "calculation", "計算", "価格", "割引", "いくつ"],
"required_args": ["expression"],
"returns": ["result"],
"risk_level": "low",
},
]
def discover_tools(query, registry, top_k=2):
cleaned = query.lower().replace("?", "").replace("?", "")
compacted = cleaned.replace(" ", "")
words = set(cleaned.split())
words.update(compacted[i : i + 2] for i in range(max(len(compacted) - 1, 0)))
scored = []
for tool in registry:
text = " ".join([tool["name"], tool["description"], " ".join(tool["tags"])]).lower()
score = sum(word in text for word in words)
scored.append((tool["name"], score))
scored.sort(key=lambda item: item[1], reverse=True)
return scored[:top_k]
queries = [
"返金ポリシーは何ですか",
"注文はもう発送されましたか",
"299 が 8 割引で、さらに 5 引くといくつですか",
]
for query in queries:
print(query, "->", discover_tools(query, TOOL_REGISTRY))
期待される出力:
返金ポリシーは何ですか -> [('search_refund_policy', 1), ('get_order_status', 0)]
注文はもう発送されましたか -> [('get_order_status', 2), ('search_refund_policy', 0)]
299 が 8 割引で、さらに 5 引くといくつですか -> [('calculator', 3), ('search_refund_policy', 0)]
このコードは何を教えているのか?
このコードは、特に重要な2つのことを教えています。
- ツールは「むき出しの関数」ではなく、metadata を持つオブジェクトである
- ツール発見は本質的に、「要求」と「ツール説明」の対応づけである
なぜ tags が役に立つのか?
ユーザーは、ツール名とまったく同じ言葉を使うとは限らないからです。
たとえば:
- ユーザーは「発送された?」と言う
- ツール名は
get_order_statusかもしれない
tags がなければ、発見の段階で候補ツールを見落としやすくなります。
なぜここでは直接実行せず、候補だけ返すのか?
「発見」は最初の一歩だからです。
ここで解決したいのは次のことです。
- どのツールが候補集に入る価値があるか
その後には、普通はさらに次の処理があります。
- パラメータ補完
- ツール選択
- 実行と検証
さらに小さな「候補ツールの絞り込み表」の例
query = "返金ポリシーは何ですか"
candidates = discover_tools(query, TOOL_REGISTRY)
for item in candidates:
print({"query": query, "candidate_tool": item[0], "score": item[1]})
期待される出力:
{'query': '返金ポリシーは何ですか', 'candidate_tool': 'search_refund_policy', 'score': 1}
{'query': '返金ポリシーは何ですか', 'candidate_tool': 'get_order_status', 'score': 0}
この例は初心者にとても向いています。
なぜなら、まず次のことが見えるからです。
- ツール発見の段階で本当に出力されるのは答えではない
- 候補となるアクションの集合である
実際のシステムでは「発見」は1種類ではない
キーワード / タグマッチ
これは最も直感的な層です。利点は次のとおりです。
- シンプル
- 説明しやすい
欠点は次のとおりです。
- 意味の一般化が弱い
ベクトル検索型のツール発見
ツールが多くなると、よくある方法は次のようになります。
- ツール説明を embedding にする
- ユーザー意図とベクトルで照合する
これは次のような場合に向いています。
- ツール数が多い
- ツール説明が長い
明示的なルーティングルール
高リスクなシステムでは、
ツール発見を完全にモデルに任せないこともあります。
その代わりに、先にルールを追加します。
- 注文関連のリクエストは先に注文ツールを見る
- 削除系の操作は必ず人間の確認を入れる
これは、ツール発見が単なる recall の問題ではなく、
方針の問題でもあることを示しています。
初めてツールシステムを作るときの、最も安定した順番
より安定した順番は、たいてい次のとおりです。
- まずツール説明を分かりやすく書く
- 次に、いちばん簡単な候補 recall を作る
- 候補集が妥当か確認する
- その後でパラメータ補完と実行を追加する
最初から「モデルが自動で正しく選べるか」に集中するより、ずっと安定します。
返却構造も、なぜツール説明の一部なのか?
発見は「ツールを見つける」だけでなく、後続フローにつながるかも重要だから
たとえば:
search_refund_policyはpolicy_textを返すget_order_statusはorder_statusを返す
後続システムがこれらを1つの回答にまとめる必要があるなら、
返却フィールドが明確であるほど、後の処理は安定します。
シンプルな統一返却ルールの例
def normalize_tool_result(ok, data=None, error=None):
return {
"ok": ok,
"data": data or {},
"error": error,
}
print(normalize_tool_result(True, data={"policy_text": "7日以内は返金可能です"}))
print(normalize_tool_result(False, error="missing_order_id"))
期待される出力:
{'ok': True, 'data': {'policy_text': '7日以内は返金可能です'}, 'error': None}
{'ok': False, 'data': {}, 'error': 'missing_order_id'}
統一された返却構造には、次のような利点があります。
- スケジューラが処理しやすい
- ログを分析しやすい
- Agent が observation を読みやすい
ツール説明でよくある落とし穴
誤解1: 関数シグネチャが分かれば十分
プログラマーにとっては十分でも、
モデルにとってはたいてい不十分です。
誤解2: ツール説明は短いほどよい
短すぎると、あいまいになります。
本当に大事なのは次の2つです。
- 正確であること
- 区別できること
単に短ければよいわけではありません。
誤解3: 発見は1つでもツールを返せればよい
候補集の質が悪ければ、
その後の選択も実行も悪くなります。
そのため、ツール発見はシステム品質にとって重要な前段階です。
これをノートやプロジェクトにするなら、何を見せるとよいか
見せる価値が高いのは、次のようなものです。
- たくさんのツール関数定義
- ではなく、
- ツール説明カード
- ユーザー質問 -> 候補ツール一覧
- なぜそのツールが上位に来たのか
- ツール返却構造をどう統一したか
こうすると、見る人には次のことが伝わりやすくなります。
- あなたはツールシステムの「発見層」を理解している
- 単に関数をモデルに接続しただけではない
まとめ
この節で最も大事なのは、たくさんの項目名を覚えることではありません。
次の1つの判断軸を持つことです。
Agent が安定してツールを選べるのは、モデルが「すごく賢くて全関数を理解している」からではなく、ツールが発見可能で、区別可能で、検証可能な対象として説明されているから。
この主線が分かれば、
次に学ぶ次の内容も理解しやすくなります。
- ツールルーティング
- ツールの安全性
- 複数ツールの協調
そして、「まずツール説明を分かりやすくすること」が第一歩だと分かるはずです。
練習
- サンプルの登録表に
search_faqツールを追加して、search_refund_policyと混同されるか見てみましょう。 - なぜ
tagsは、ツール名よりも第一段階の recall に向いていることが多いのでしょうか? - 考えてみましょう:高リスクなツールの説明には、用途とパラメータのほかに、何を書き足しますか?
- ツールがどんどん増えるとき、まず強化したいのは「ツール説明」と「ツール実行器」のどちらですか? なぜですか?