5.2.4 決定木
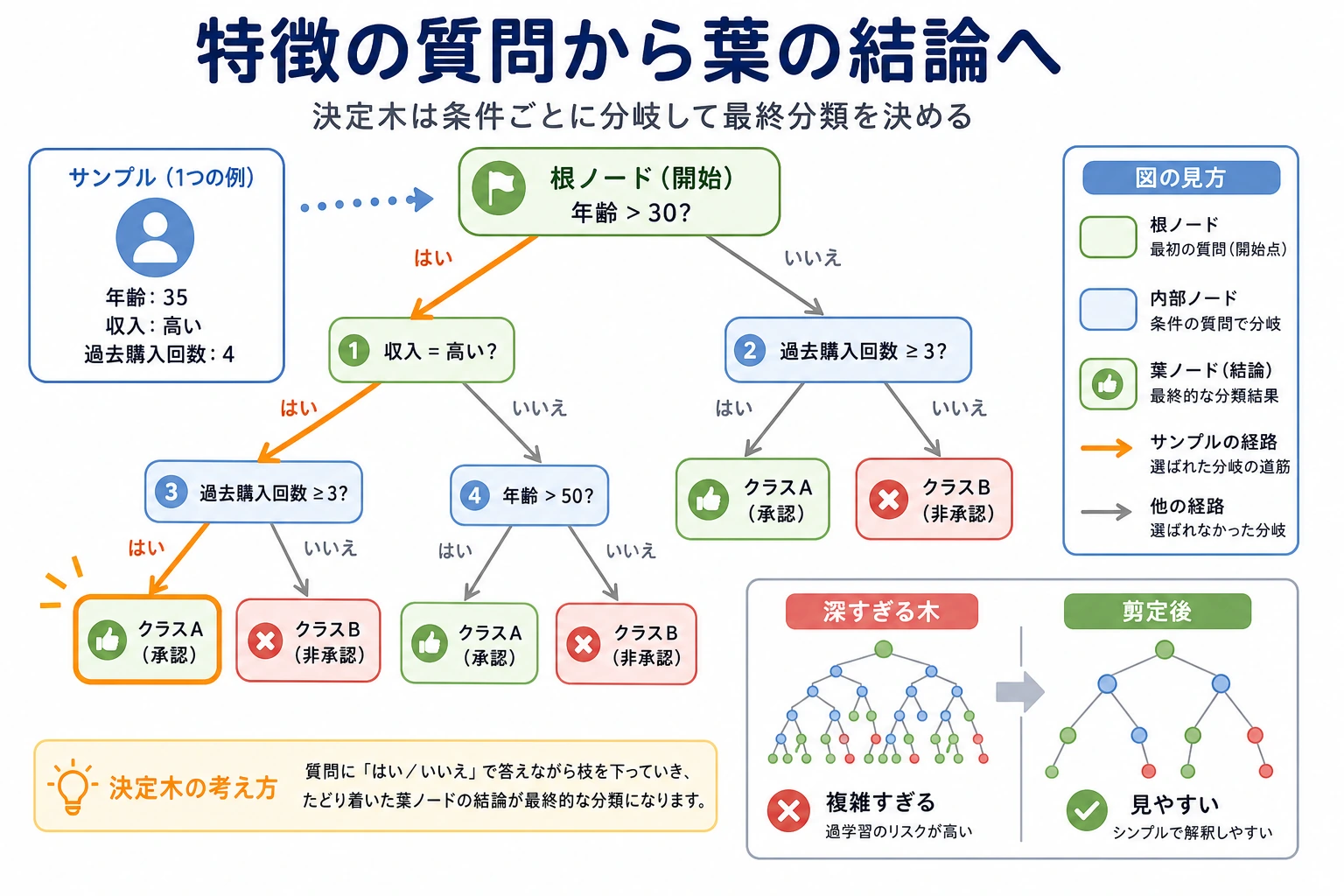
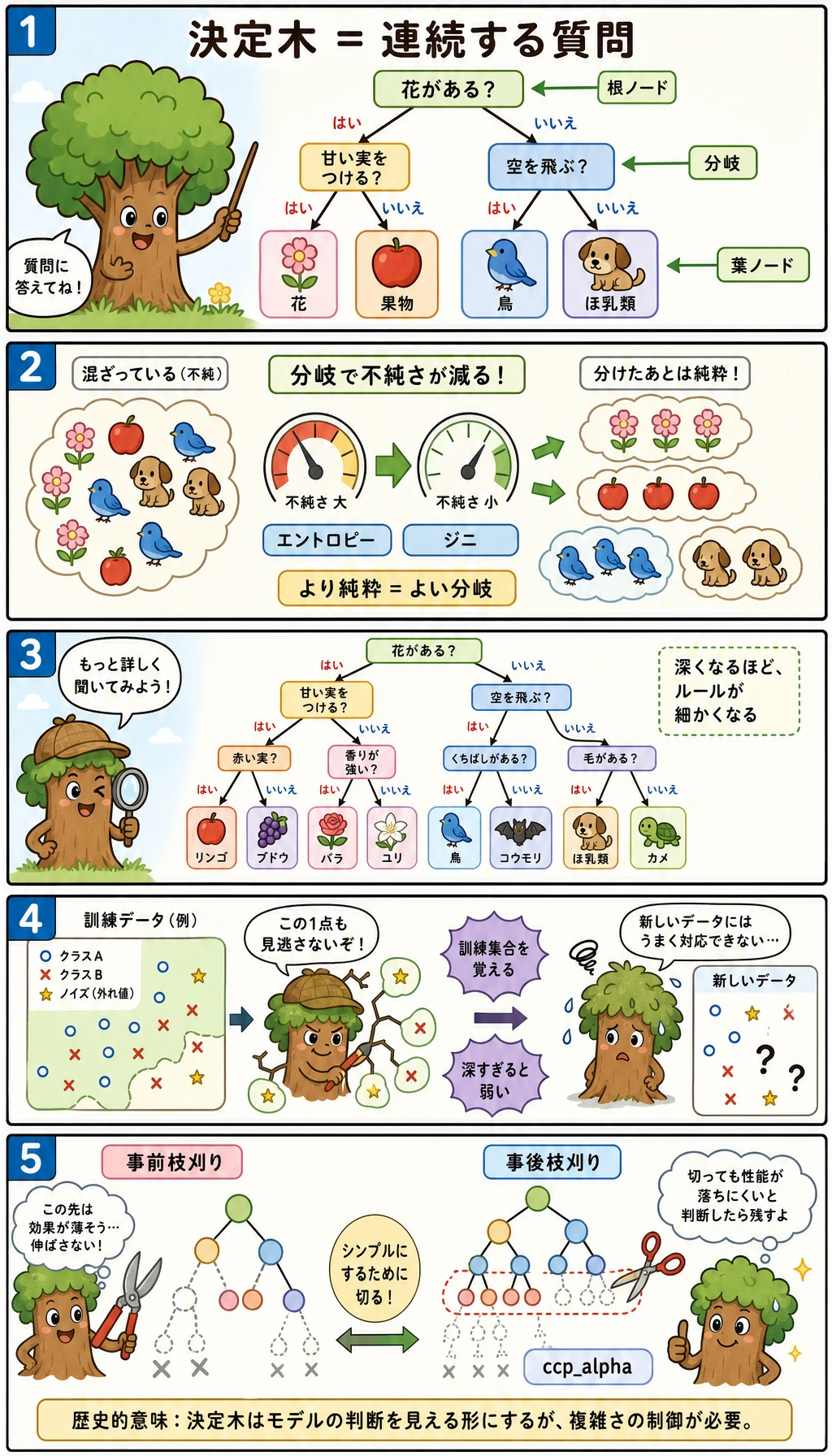
決定木は、質問を積み重ねて作るモデルです。各予測がルールの道筋をたどるので読みやすい一方、ルールが細かくなりすぎるとすぐ過学習します。
作るもの
この節では 1 つのスクリプトで次を確認します。
- 木の深さが train/test accuracy にどう影響するか;
- 読める形で木のルールを表示する方法;
- 特徴量重要度が分割からどう計算されるか;
ccp_alphaによる後枝刈りで葉の数がどう変わるか;- 回帰木が階段状の数値予測をする理由。
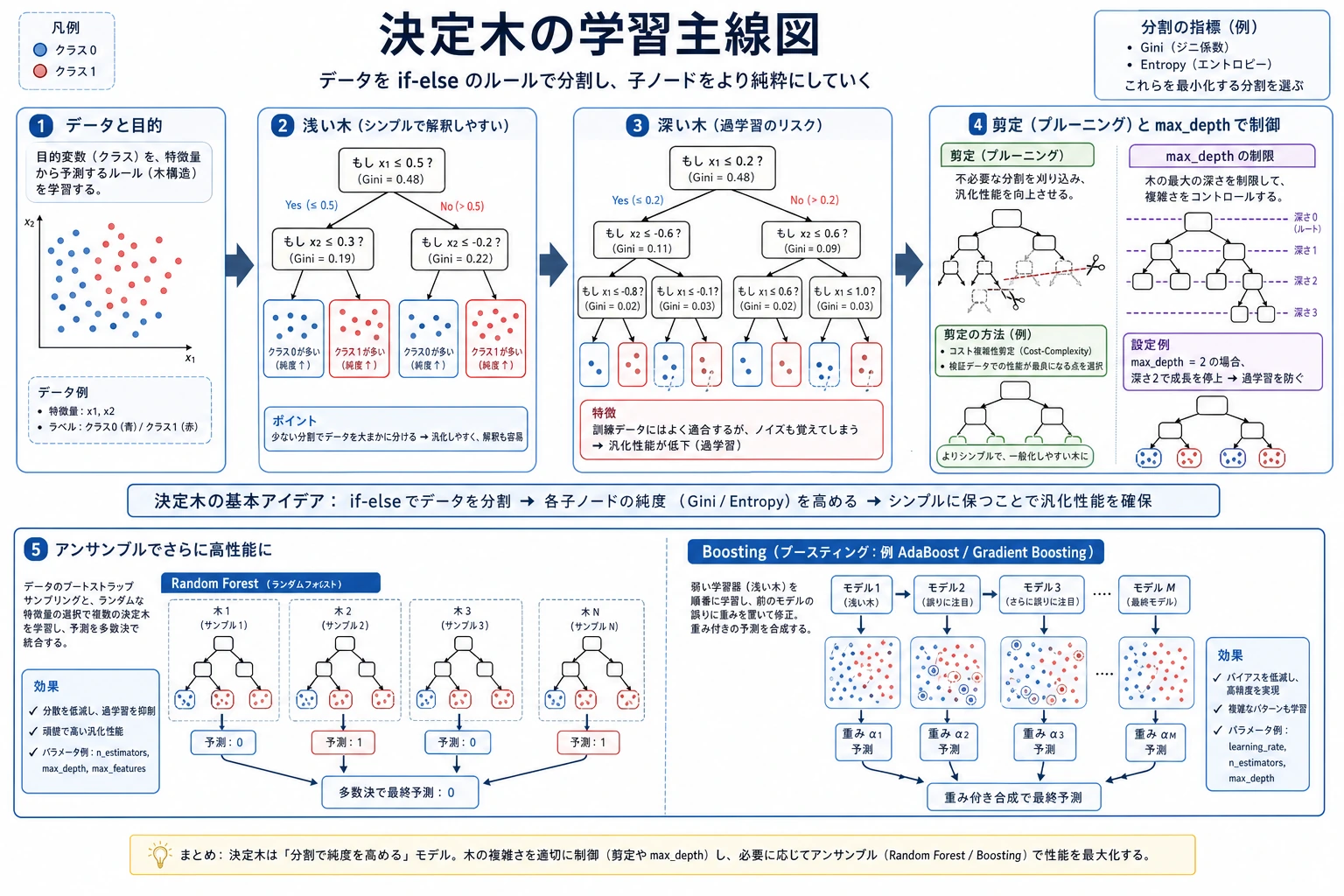
まず図を見てください。決定木は単なる if-else ではなく、「if-else + 分割の評価 + 複雑さの制御」です。
セットアップ
python -m pip install -U scikit-learn
この節では sklearn の CART 風の DecisionTreeClassifier と DecisionTreeRegressor を使います。CART は Classification and Regression Trees の略で、同じ木の考え方で分類も回帰も扱えるという意味です。
完全な実験を実行する
decision_tree_lab.py を作成します。
from sklearn.datasets import load_diabetes, load_iris
from sklearn.metrics import accuracy_score, mean_absolute_error
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor, export_text
iris = load_iris()
X = iris.data[:, 2:4] # petal length and petal width, easier to read
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
print("classification_depth_lab")
for depth in [1, 2, 3, None]:
tree = DecisionTreeClassifier(max_depth=depth, min_samples_leaf=3, random_state=42)
tree.fit(X_train, y_train)
train_acc = accuracy_score(y_train, tree.predict(X_train))
test_acc = accuracy_score(y_test, tree.predict(X_test))
print(
f"max_depth={str(depth):<4} "
f"train={train_acc:.3f} test={test_acc:.3f} "
f"leaves={tree.get_n_leaves()} depth={tree.get_depth()}"
)
best_tree = DecisionTreeClassifier(max_depth=3, min_samples_leaf=3, random_state=42)
best_tree.fit(X_train, y_train)
print("tree_rules")
print(export_text(best_tree, feature_names=["petal length", "petal width"], decimals=2, max_depth=3))
print("feature_importance")
for name, value in zip(["petal length", "petal width"], best_tree.feature_importances_):
print(f"- {name}: {value:.3f}")
print("pruning_lab")
path = DecisionTreeClassifier(random_state=42).cost_complexity_pruning_path(X_train, y_train)
for alpha in path.ccp_alphas[[0, 1, -2]]:
pruned = DecisionTreeClassifier(random_state=42, ccp_alpha=float(alpha))
pruned.fit(X_train, y_train)
print(
f"ccp_alpha={alpha:.4f} "
f"test={accuracy_score(y_test, pruned.predict(X_test)):.3f} "
f"leaves={pruned.get_n_leaves()}"
)
print("regression_tree_lab")
diabetes = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(
diabetes.data, diabetes.target, test_size=0.25, random_state=42
)
for depth in [2, 4, None]:
reg = DecisionTreeRegressor(max_depth=depth, min_samples_leaf=10, random_state=42)
reg.fit(X_train, y_train)
pred = reg.predict(X_test)
print(f"max_depth={str(depth):<4} mae={mean_absolute_error(y_test, pred):.1f} leaves={reg.get_n_leaves()}")
実行します。
python decision_tree_lab.py
期待される出力:
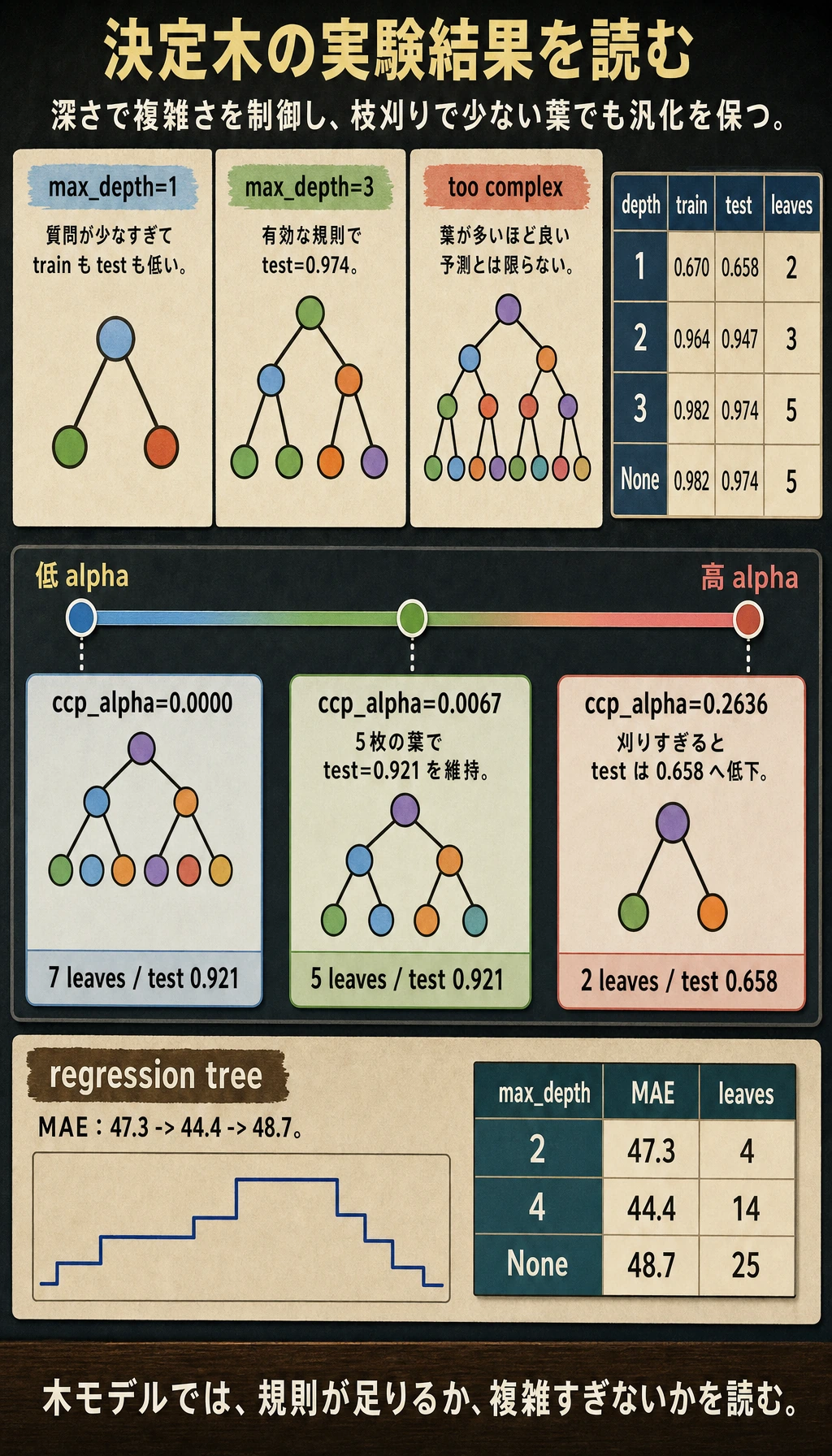
classification_depth_lab
max_depth=1 train=0.670 test=0.658 leaves=2 depth=1
max_depth=2 train=0.964 test=0.947 leaves=3 depth=2
max_depth=3 train=0.982 test=0.974 leaves=5 depth=3
max_depth=None train=0.982 test=0.974 leaves=5 depth=3
tree_rules
|--- petal length <= 2.45
| |--- class: 0
|--- petal length > 2.45
| |--- petal width <= 1.70
| | |--- petal length <= 4.95
| | | |--- class: 1
| | |--- petal length > 4.95
| | | |--- class: 2
| |--- petal width > 1.70
| | |--- petal length <= 4.95
| | | |--- class: 2
| | |--- petal length > 4.95
| | | |--- class: 2
feature_importance
- petal length: 0.588
- petal width: 0.412
pruning_lab
ccp_alpha=0.0000 test=0.921 leaves=7
ccp_alpha=0.0067 test=0.921 leaves=5
ccp_alpha=0.2636 test=0.658 leaves=2
regression_tree_lab
max_depth=2 mae=47.3 leaves=4
max_depth=4 mae=44.4 leaves=14
max_depth=None mae=48.7 leaves=25
出力を読む
最初のブロックが一番重要です。
max_depth=1 train=0.670 test=0.658 leaves=2 depth=1
max_depth=3 train=0.982 test=0.974 leaves=5 depth=3
max_depth=1 は 1 つの質問しかできないので単純すぎます。max_depth=3 は数回の追加質問ができ、かなり良くなります。この小さなデータセットでは、max_depth=None でも深くなりすぎません。min_samples_leaf=3 が小さすぎる葉を防ぎ、データ自体も単純だからです。
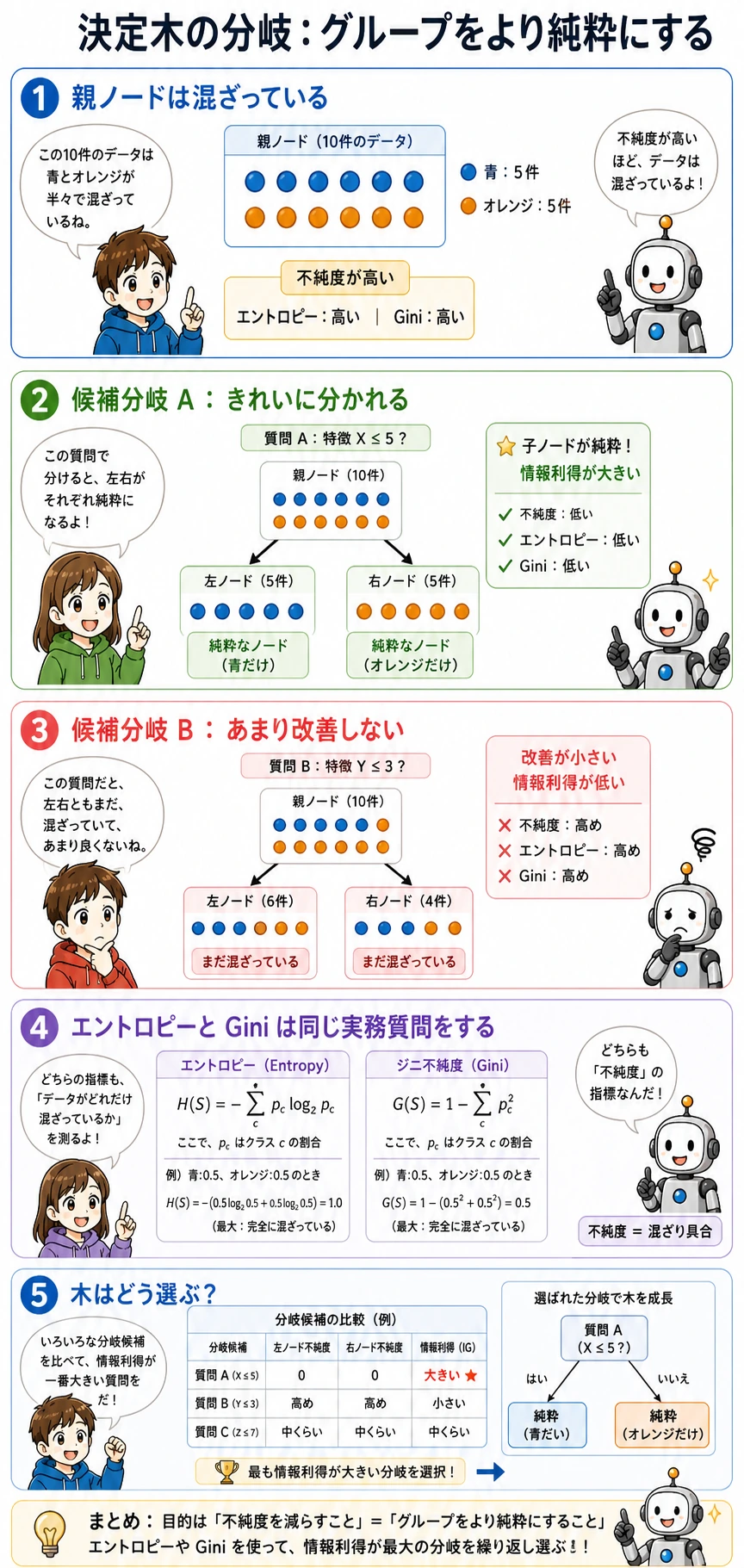
各ノードでは次のような質問を探します。
petal length <= 2.45?
良い分割とは、子ノードが親ノードより「きれい」になる分割です。きれいとは、ノード内のラベルが混ざりにくいということです。
Gini、エントロピー、情報利得
初回からすべての式を覚える必要はありません。まず役割を押さえます。
| 用語 | 実用上の意味 |
|---|---|
Gini | ノード内のラベルの混ざり具合。sklearn 分類木の既定値 |
entropy | 別の混ざり具合の指標。情報理論とつながる |
information gain | 分割後に混ざり具合がどれだけ下がったか |
criterion | 評価ルールを選ぶ設定。例:criterion="gini"、criterion="entropy" |
特別な理由がなければ、まず gini で十分です。多くの表形式データでは、Gini と entropy の違いより、深さ、葉サイズ、枝刈りの調整のほうが効きます。
複雑さを制御する
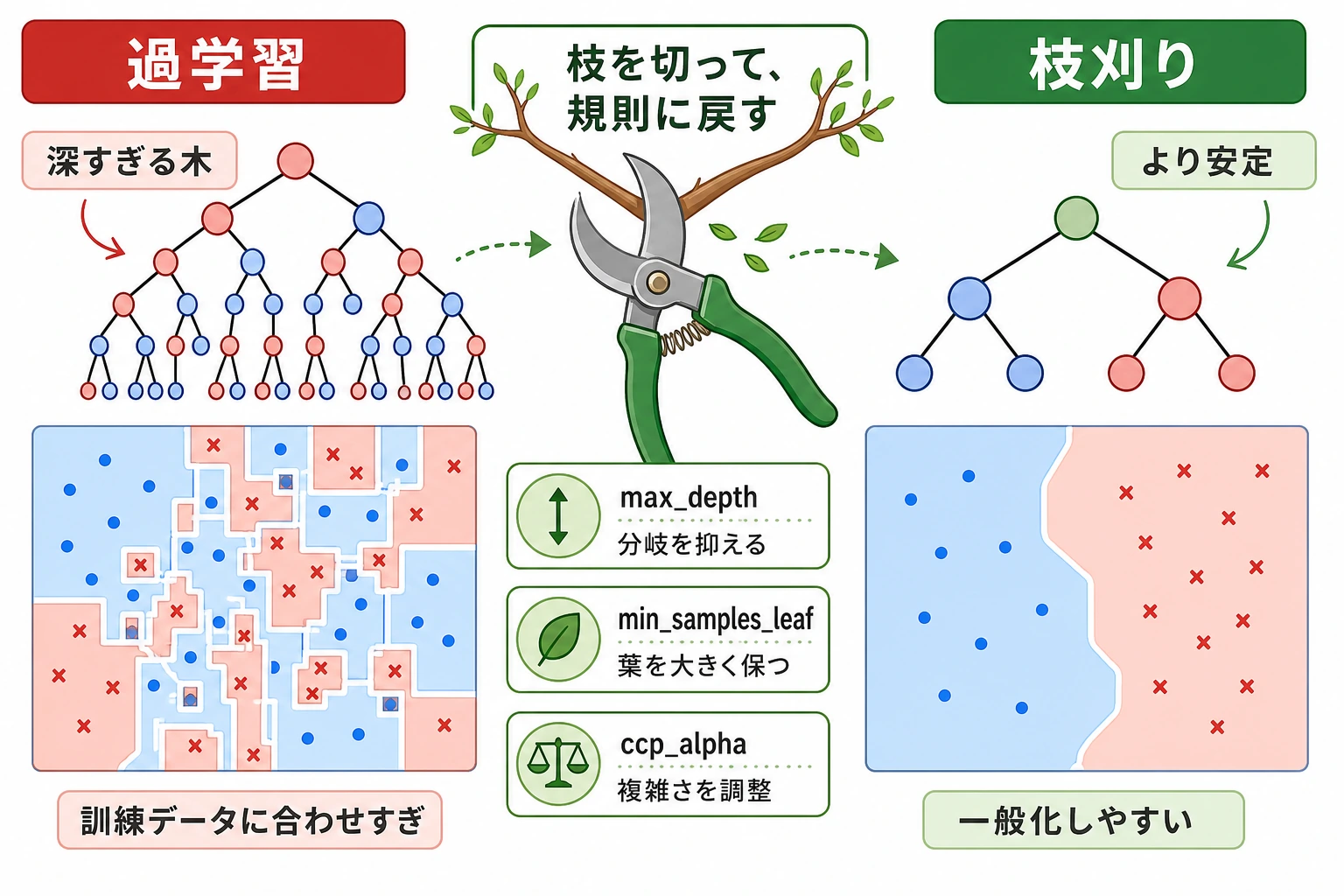
実務での調整順は次の通りです。
max_depthで木が深くなりすぎないようにする。min_samples_leafで各葉に十分なサンプルを残す。ccp_alphaで、成長後の木を後枝刈りする。
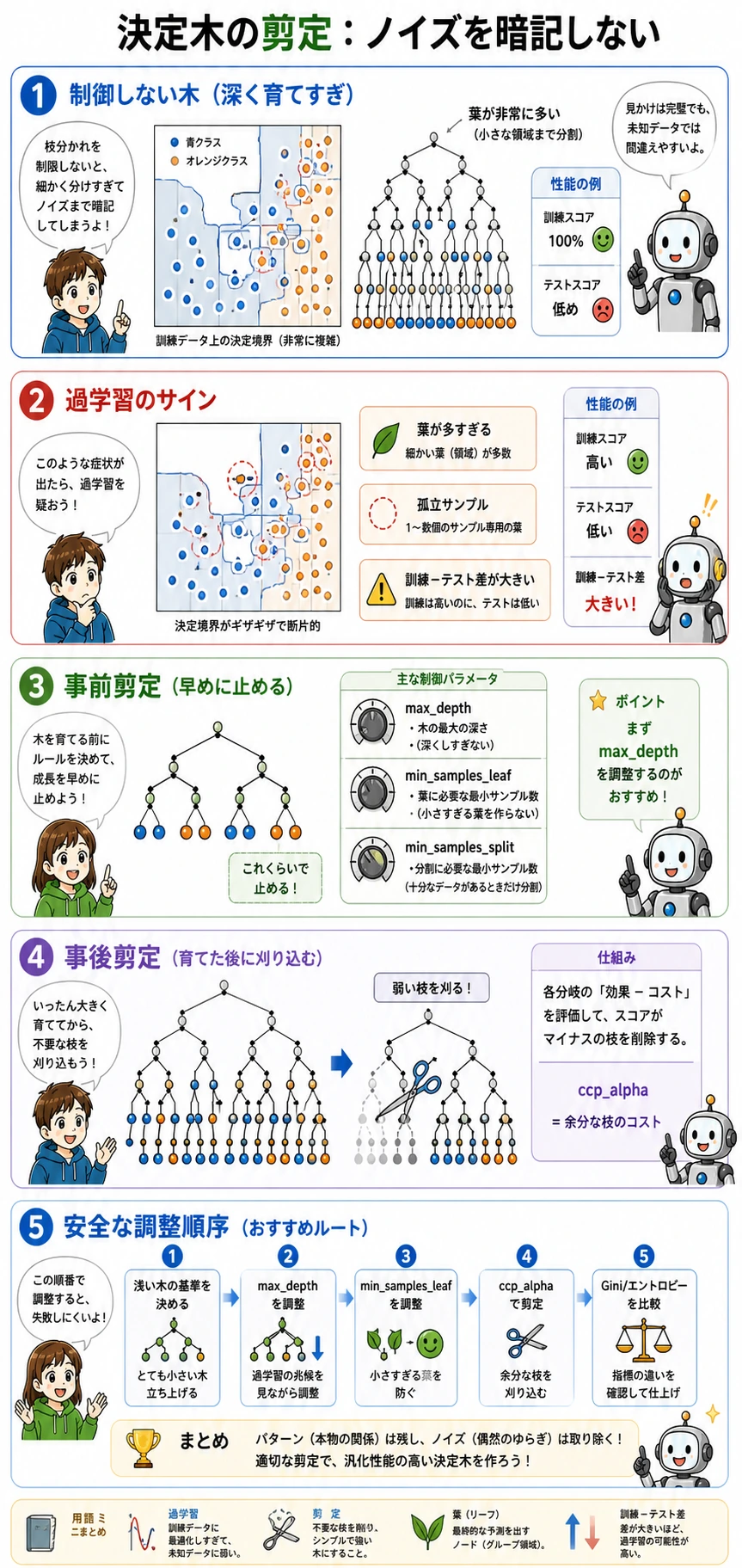
枝刈りの出力はトレードオフを示しています。
ccp_alpha=0.0000 test=0.921 leaves=7
ccp_alpha=0.0067 test=0.921 leaves=5
ccp_alpha=0.2636 test=0.658 leaves=2
少し枝刈りすると、テストスコアを保ったまま葉が減りました。枝刈りしすぎると葉が 2 つだけになり、有用なルールも失われます。
解釈性
export_text() は、サンプルがたどるルールの道筋を表示します。チームメイトに予測理由を説明するときに便利です。
|--- petal length <= 2.45
| |--- class: 0
特徴量重要度も便利ですが、読み方には注意が必要です。
- この学習済みの木で、どの特徴量が不純度を多く下げたかを示す;
- 分割候補が多い特徴量を有利に扱うことがある;
- 相関した特徴量は重要度を分け合ったり隠したりする;
- 因果的な重要度とは限らない。
より慎重に解釈したい場合は、あとで permutation importance と比較します。
回帰木
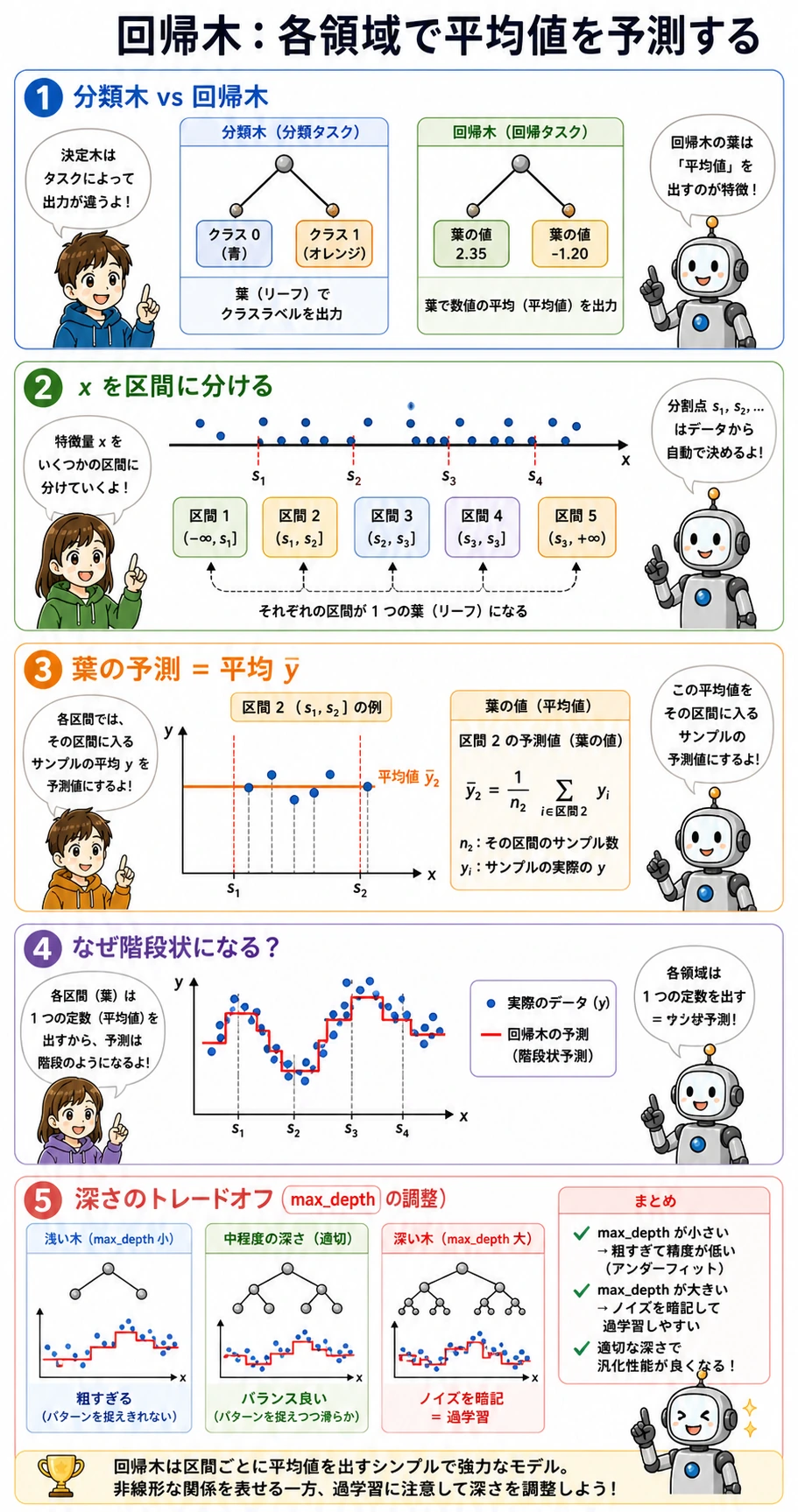
回帰木は数値を予測しますが、考え方は同じです。特徴空間を複数の領域に分け、各葉で目的変数の平均を出します。
そのため、回帰木の予測はなめらかな線ではなく、階段のように見えることがあります。実験では:
max_depth=4 mae=44.4 leaves=14
max_depth=None mae=48.7 leaves=25
深い木は葉が増えますが、テスト MAE は悪化しました。ルールが多ければ汎化が良い、とは限りません。
単体の決定木を使う場面
単体の木が向いている場面:
- すばやく説明しやすいベースラインが必要;
- 業務ルールとしてモデルの分岐を取り出したい;
- 非線形な分割を図で説明したい;
- Random Forest や boosting に進む前の土台にしたい。
単体の木だけに頼りにくい場面:
- データが少し変わるだけで木構造が大きく変わる;
- テストスコアが訓練スコアより大きく下がる;
- 集成モデルの精度と安定性が必要。
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| train score は高いが test score が低い | 木が深すぎる | max_depth を下げ、min_samples_leaf を上げ、枝刈りを試す |
| 小さな葉が大量にある | まれなケースを記憶している | min_samples_leaf を上げる |
| 特徴量重要度が怪しい | 相関特徴量や高カーディナリティ特徴量の影響 | permutation importance で確認する |
| ルールが読みにくい | 木が大きすぎる | 小さな説明用の木を学習する、または重要経路だけ要約する |
| 回帰木の予測がブロック状 | 葉の平均値で予測するため | 線形モデル、ランダムフォレスト、勾配ブースティングと比較する |
練習
min_samples_leafを3から1、さらに10に変えてください。葉の数とテスト accuracy はどう変わりますか?criterionを"entropy"に変えてください。最初の分割は同じですか?max_depth=2のexport_text()を表示してください。説明しやすくなりますか?- Iris の 4 つすべての特徴量を使ってください。特徴量重要度は変わりますか?
- 回帰木の結果を、線形回帰レッスンのベースラインと比較してください。
合格チェック
次を説明できれば、この節はクリアです。
- 木は、子ノードがよりきれいになる分割を選んで学習する;
- 深い木は訓練データを記憶しやすい;
max_depth、min_samples_leaf、ccp_alphaは複雑さを制御する;- 特徴量重要度は便利だが、因果関係そのものではない;
- 回帰木は葉の平均値を出すので、予測が階段状になりやすい。