5.2.3 ロジスティック回帰
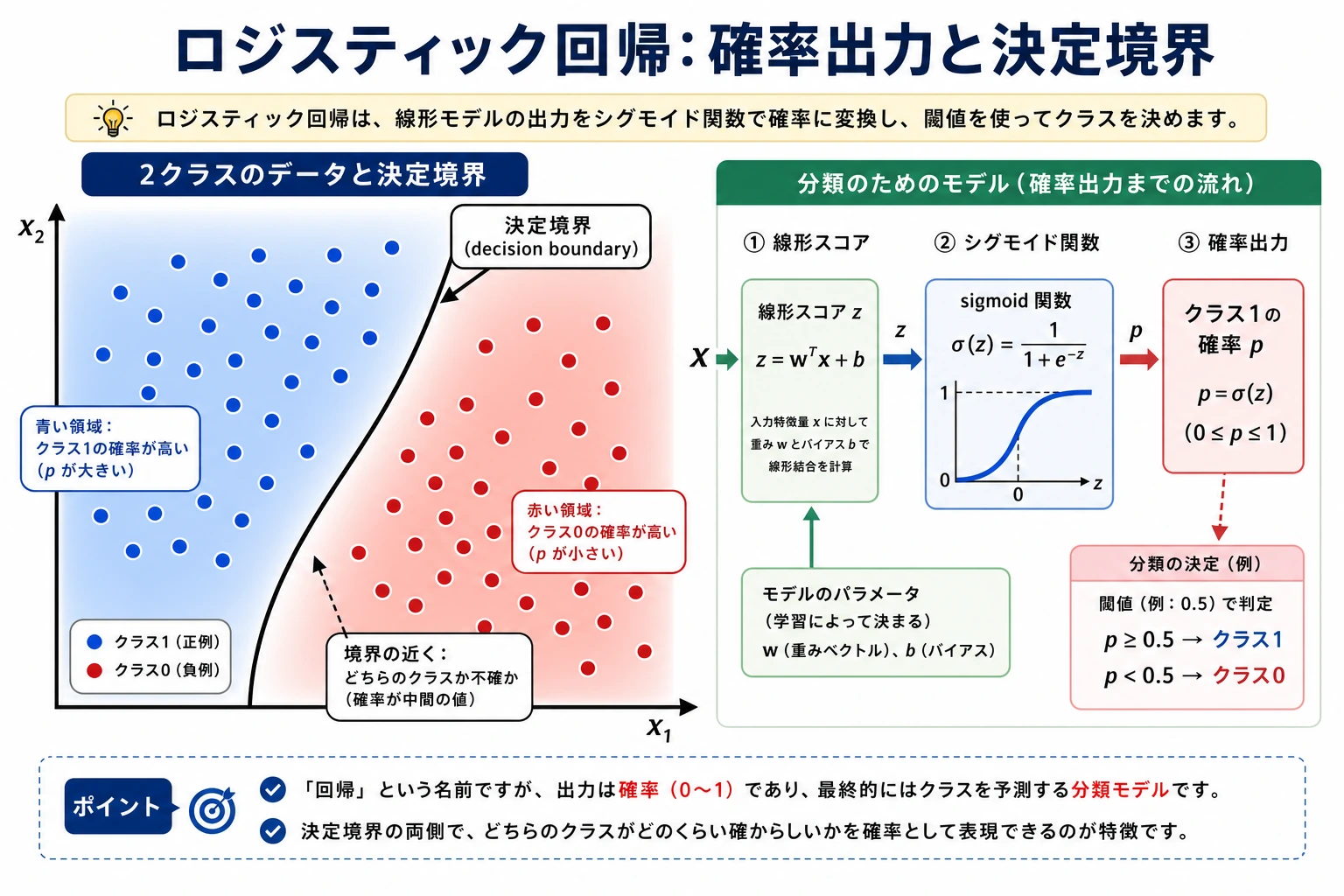
ロジスティック回帰には「回帰」という名前が入っていますが、実務では 分類モデル として使います。線形スコアを学習し、そのスコアを確率に変換し、最後にしきい値でクラスを決めます。
作るもの
このレッスンの終わりには、次の分類ワークフローを実行できるようになります。
Pipeline、StandardScaler、LogisticRegressionで二値分類器を学習する;- accuracy、precision、recall、F1、偽陽性、偽陰性を表示する;
- いつも
0.5を使うのではなく、分類しきい値を調整する; - 標準化後に効いている特徴量を確認する;
Cで正則化の強さを比較する;- 同じ書き方を多クラスデータセットにも使う。
まず下の 2 枚の図を見てからコードを実行してください。実際の出力を見たあとなら、細かい概念がかなり読みやすくなります。
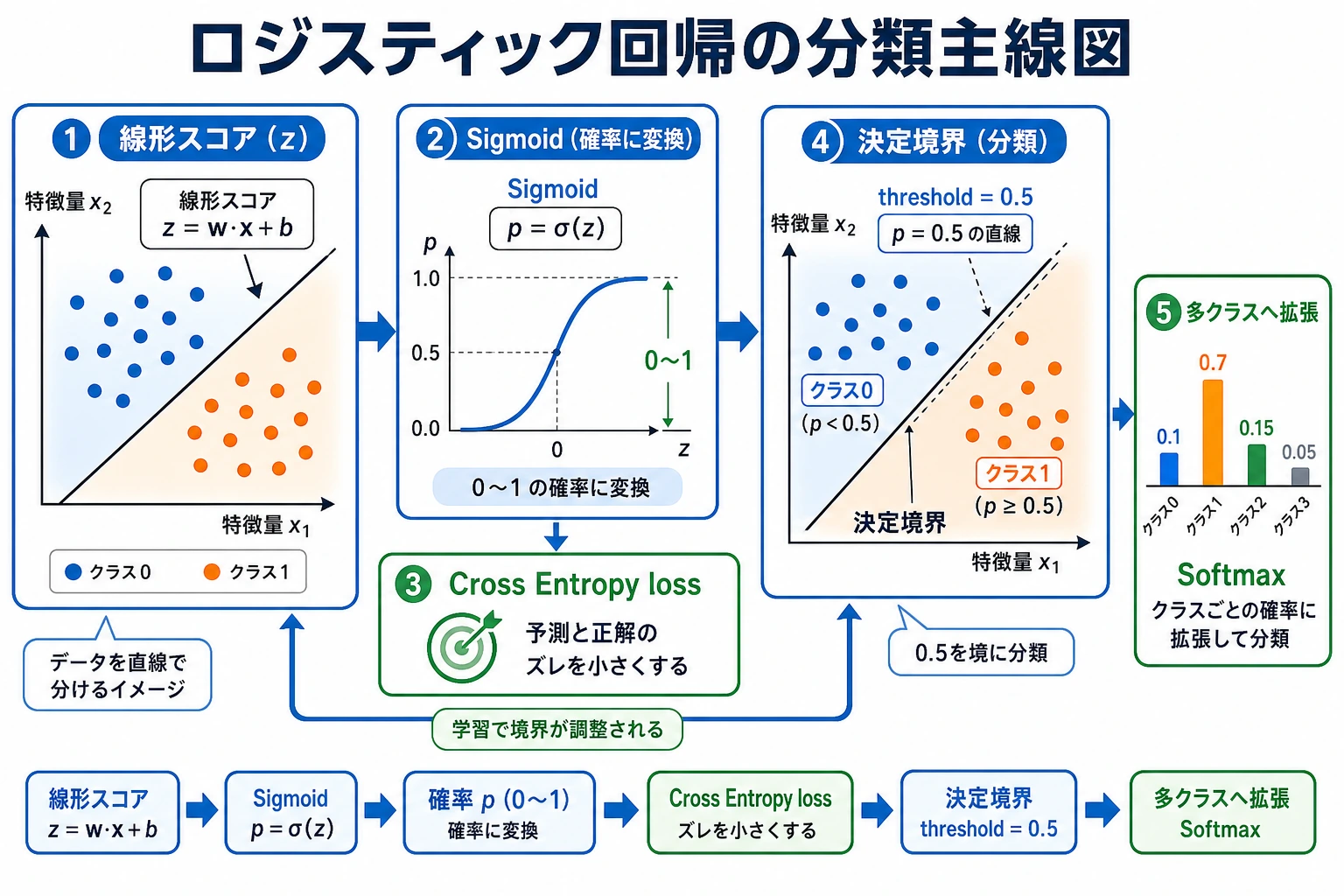
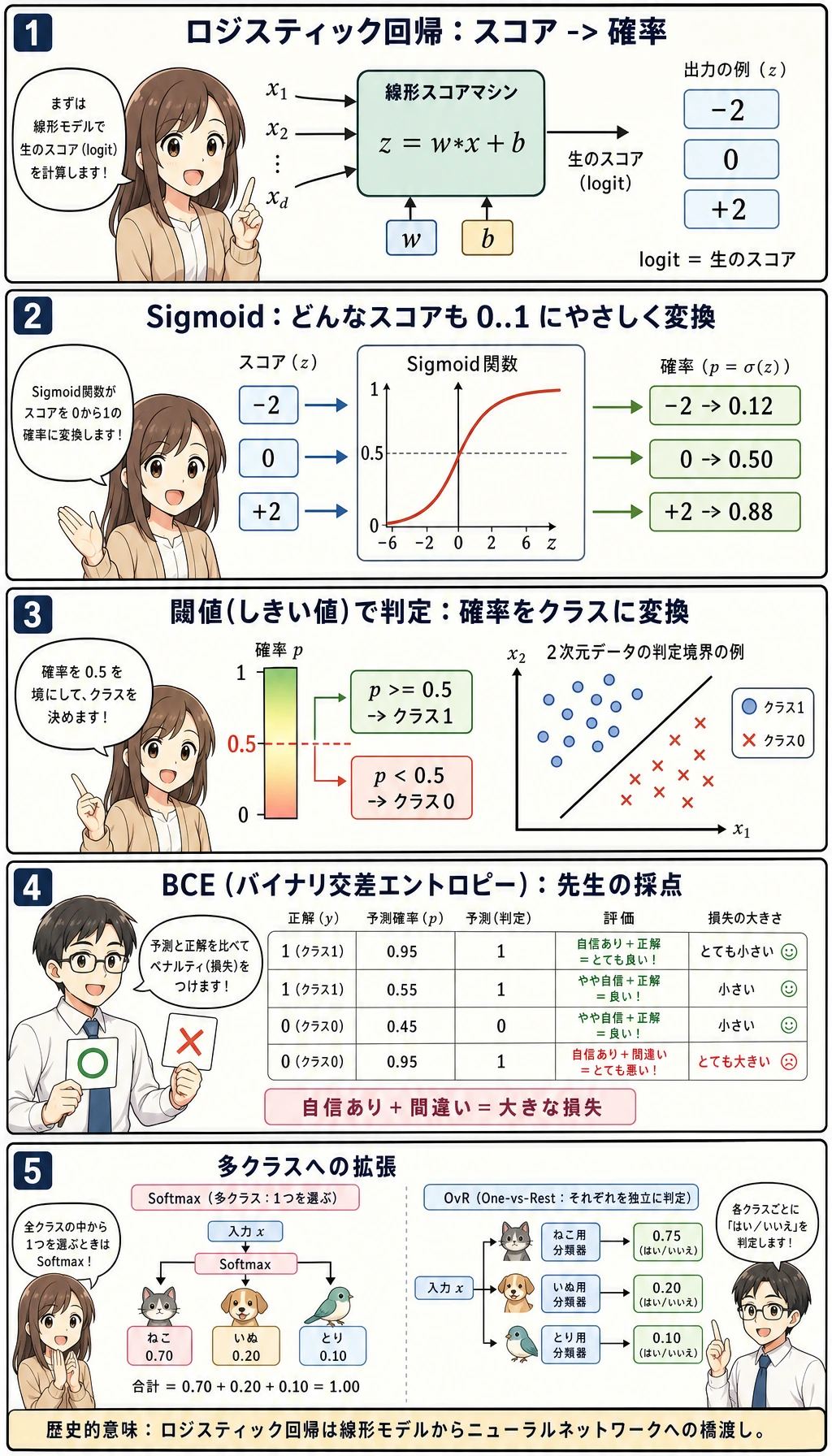
セットアップ
クリーンな仮想環境で実行します。
python -m pip install -U scikit-learn numpy
この節では、現在の安定した scikit-learn の書き方を使います。前処理の漏れを防ぐために Pipeline、数値特徴量のスケーリングに StandardScaler、分類器に LogisticRegression を使い、非推奨になりつつある古い多クラス指定は使いません。
完全な実験を実行する
logistic_lab.py を作成します。
import numpy as np
from sklearn.datasets import load_breast_cancer, load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, f1_score, precision_score, recall_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
def make_model(C=1.0):
return Pipeline([
("scale", StandardScaler()),
("clf", LogisticRegression(max_iter=2000, C=C, random_state=42)),
])
# Part 1: binary classification and threshold tuning.
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data,
cancer.target,
test_size=0.25,
random_state=42,
stratify=cancer.target,
)
model = make_model(C=1.0)
model.fit(X_train, y_train)
prob = model.predict_proba(X_test)[:, 1]
print("binary_threshold_lab")
for threshold in [0.3, 0.5, 0.7]:
pred = (prob >= threshold).astype(int)
tn, fp, fn, tp = confusion_matrix(y_test, pred).ravel()
print(
f"threshold={threshold:.1f} "
f"accuracy={accuracy_score(y_test, pred):.3f} "
f"precision={precision_score(y_test, pred):.3f} "
f"recall={recall_score(y_test, pred):.3f} "
f"f1={f1_score(y_test, pred):.3f} "
f"fp={fp} fn={fn}"
)
clf = model.named_steps["clf"]
top = np.abs(clf.coef_[0]).argsort()[-3:][::-1]
print("top_scaled_coefficients")
for idx in top:
print(f"- {cancer.feature_names[idx]}: {clf.coef_[0][idx]:.3f}")
print("regularization_check")
for C in [0.1, 1.0, 10.0]:
candidate = make_model(C=C)
candidate.fit(X_train, y_train)
pred = candidate.predict(X_test)
coef_norm = np.linalg.norm(candidate.named_steps["clf"].coef_)
print(f"C={C:<4} accuracy={accuracy_score(y_test, pred):.3f} coef_norm={coef_norm:.2f}")
# Part 2: multi-class probability output.
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data,
iris.target,
test_size=0.25,
random_state=42,
stratify=iris.target,
)
multi = make_model(C=1.0)
multi.fit(X_train, y_train)
print("multiclass_lab")
print("accuracy=", round(accuracy_score(y_test, multi.predict(X_test)), 3))
for row in multi.predict_proba(X_test[:3]):
pairs = [f"{name}:{value:.2f}" for name, value in zip(iris.target_names, row)]
print(" | ".join(pairs))
実行します。
python logistic_lab.py
期待される出力:
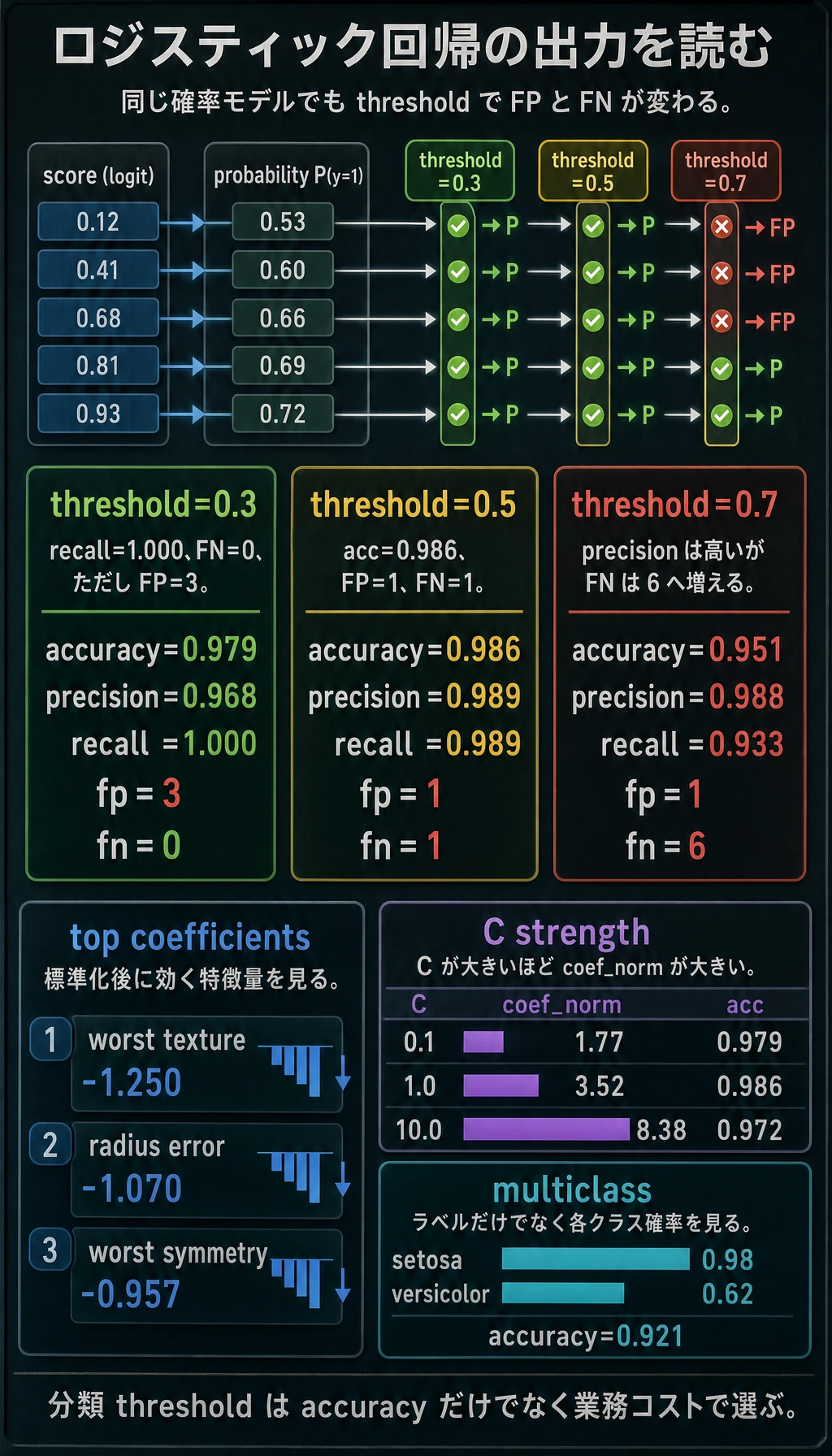
binary_threshold_lab
threshold=0.3 accuracy=0.979 precision=0.968 recall=1.000 f1=0.984 fp=3 fn=0
threshold=0.5 accuracy=0.986 precision=0.989 recall=0.989 f1=0.989 fp=1 fn=1
threshold=0.7 accuracy=0.951 precision=0.988 recall=0.933 f1=0.960 fp=1 fn=6
top_scaled_coefficients
- worst texture: -1.250
- radius error: -1.070
- worst symmetry: -0.957
regularization_check
C=0.1 accuracy=0.979 coef_norm=1.77
C=1.0 accuracy=0.986 coef_norm=3.52
C=10.0 accuracy=0.972 coef_norm=8.38
multiclass_lab
accuracy= 0.921
setosa:0.98 | versicolor:0.02 | virginica:0.00
setosa:0.03 | versicolor:0.62 | virginica:0.35
setosa:0.05 | versicolor:0.88 | virginica:0.07
パイプラインを読む
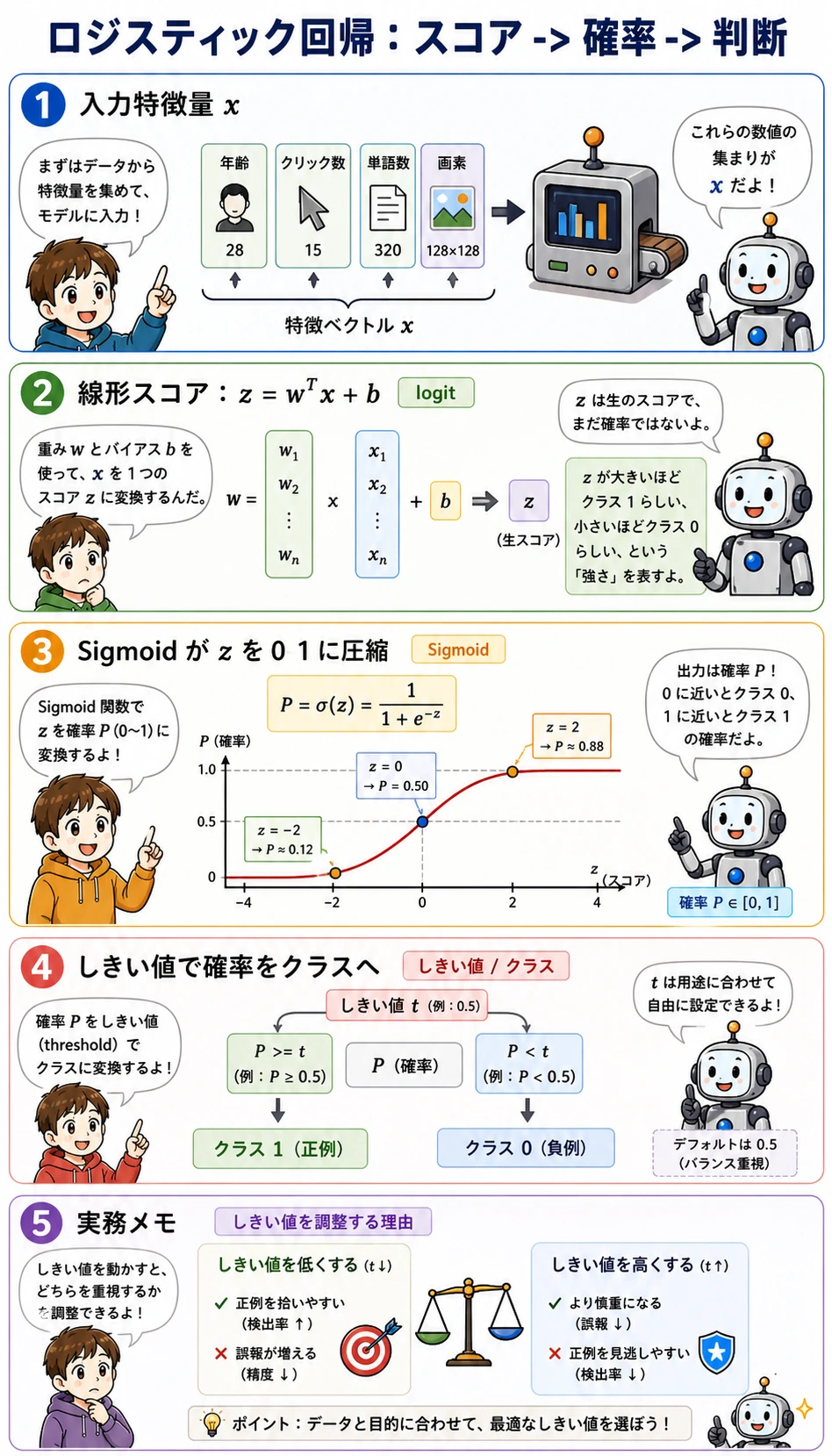
モデルは 3 つの異なる仕事をしています。
| ステップ | コード | 意味 |
|---|---|---|
| スコア | LogisticRegression 内部の z = wT x + b | 生の線形スコア。まだ確率ではない |
| 確率 | predict_proba() | スコアを 0 から 1 の値に変換する |
| 判断 | prob >= threshold | 業務ルールで確率をクラス 0 または 1 にする |
初心者がよく混乱するのは、スコア、確率、クラスを一緒に考えてしまうことです。実務では、モデルはそのままで、しきい値だけを変えることがよくあります。
最低限の理論
Sigmoid は任意の実数スコアを (0, 1) に押し込む関数です。
sigmoid(z) = 1 / (1 + exp(-z))
z = 0 のとき、確率は 0.5 です。だから二値ロジスティック回帰の標準的な決定境界は、生のスコアがゼロになる直線または超平面です。
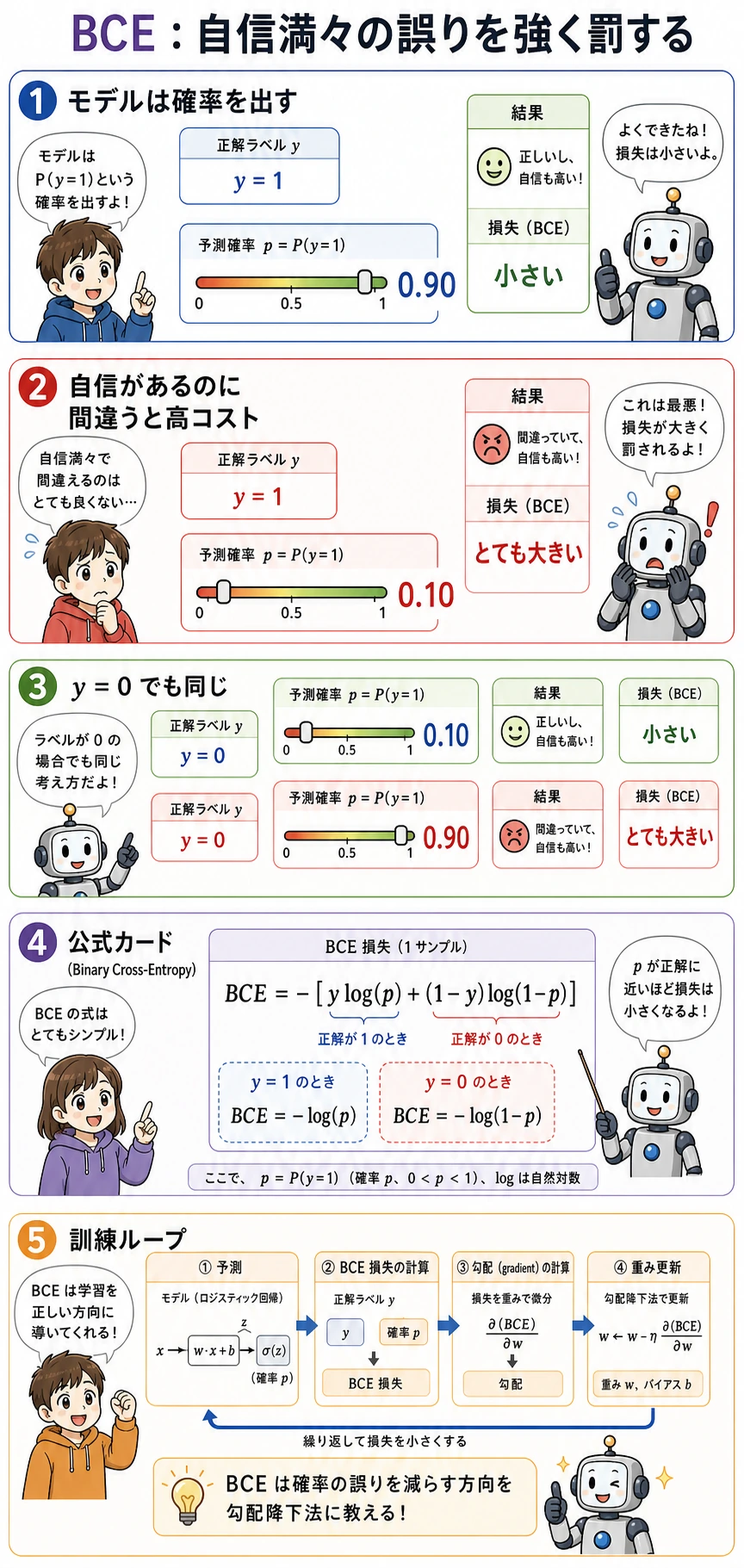
BCE は Binary Cross-Entropy(二値交差エントロピー) の略で、二値の確率予測によく使われる損失です。まずは次の直感で十分です。
- 正解が
1のとき、0.99と予測するのは良く、0.01は悪い; - 正解が
0のとき、0.01と予測するのは良く、0.99は悪い; - 自信満々に間違えるほど強く罰せられる。
そのため、線形回帰に無理やり 0 と 1 を予測させるより、ロジスティック回帰のほうが分類に向いています。
しきい値はプロダクト判断
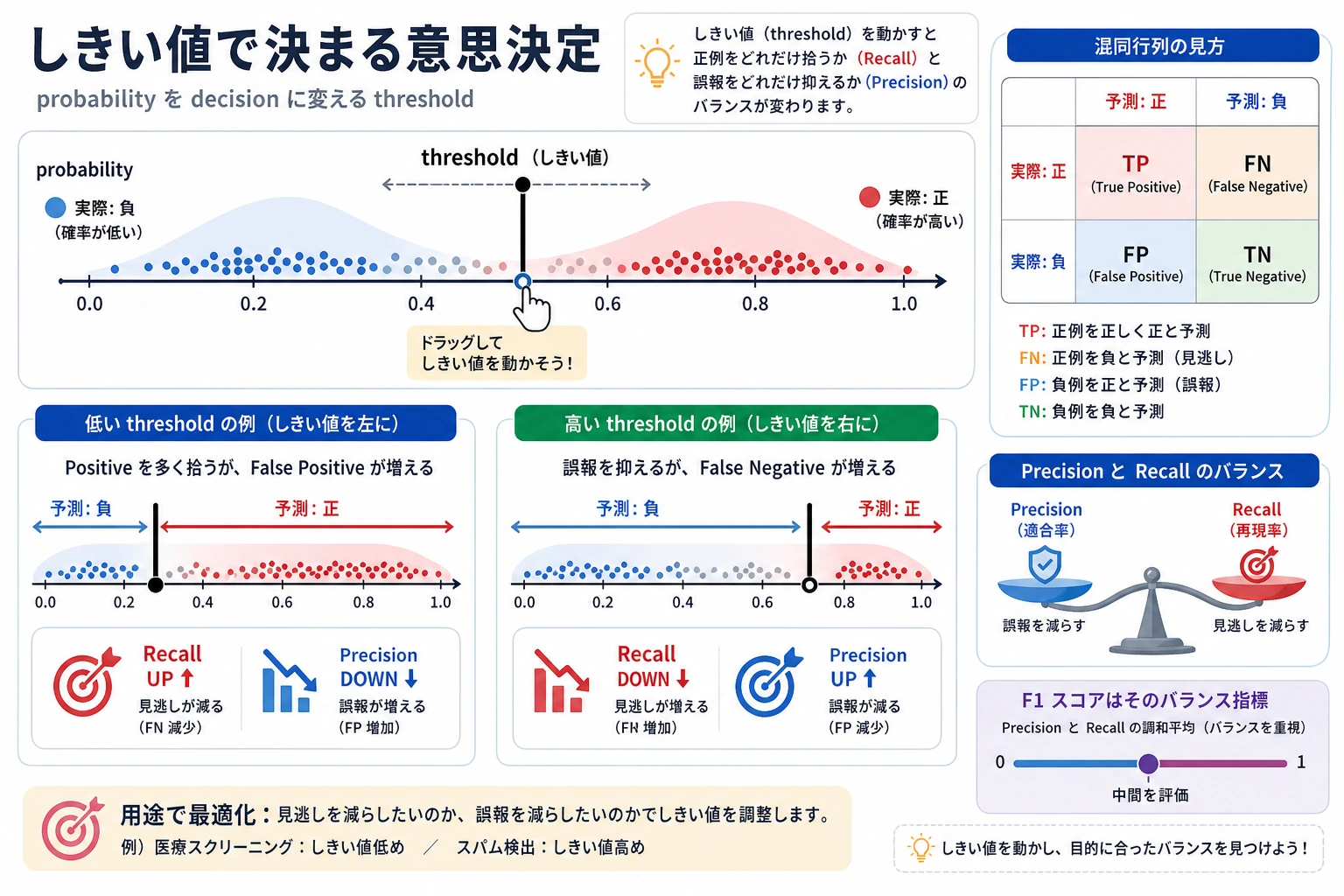
出力を見ると、しきい値を変えるだけでミスの種類が変わります。
| しきい値 | 何が起きたか | 向いている場面 |
|---|---|---|
0.3 | recall は 1.000、ただし偽陽性が増える | スクリーニング、アラート、一次抽出 |
0.5 | この分割では最もバランスが良い | コストがまだ不明なときの出発点 |
0.7 | 偽陽性は少なめ、偽陰性は増える | 人手レビューが高い、確定基準が厳しい |
経験者向けの注意点:しきい値を accuracy だけで決めないでください。fp と fn のコストを確認し、precision-recall 曲線や ROC 曲線も比較します。
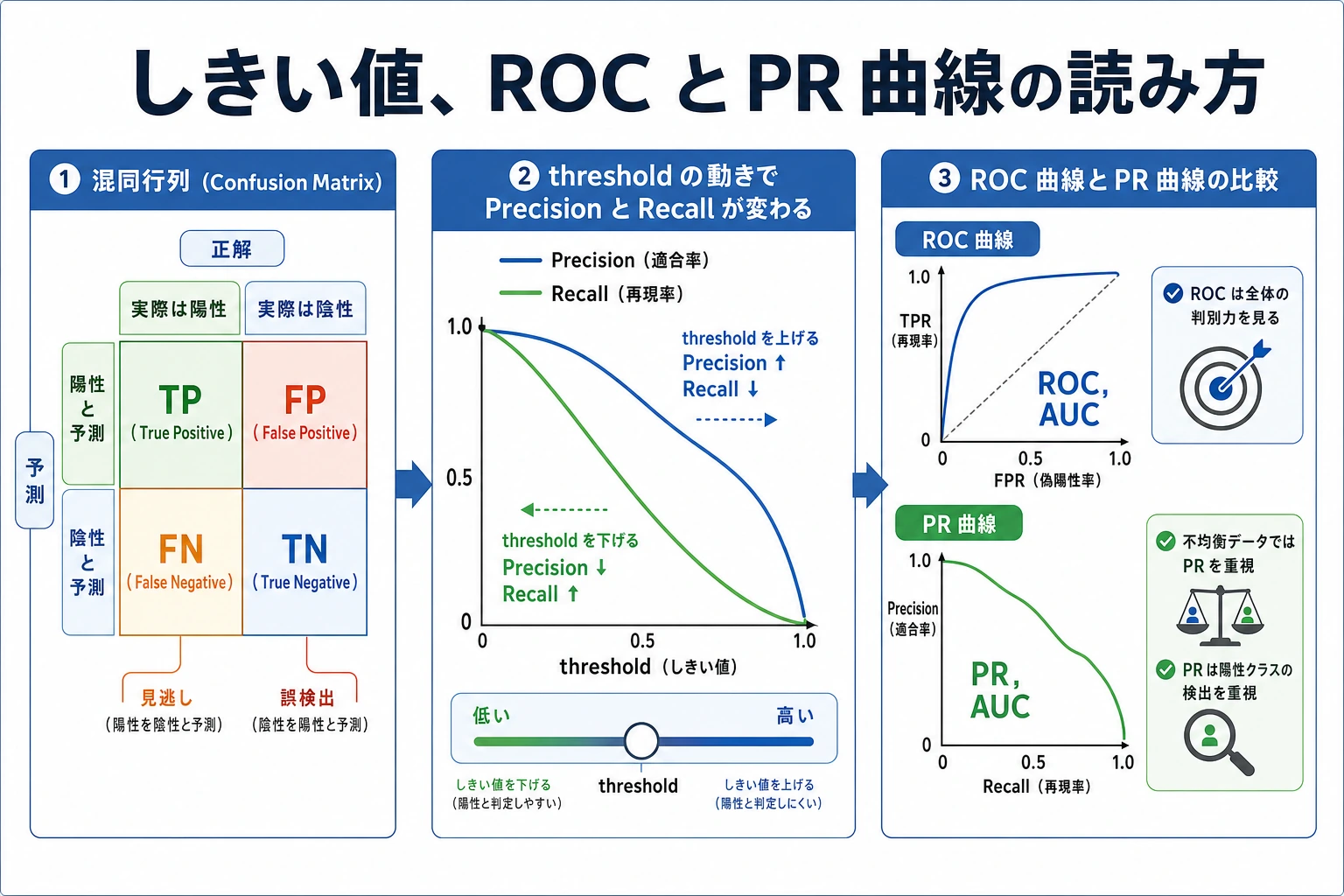
正則化と C
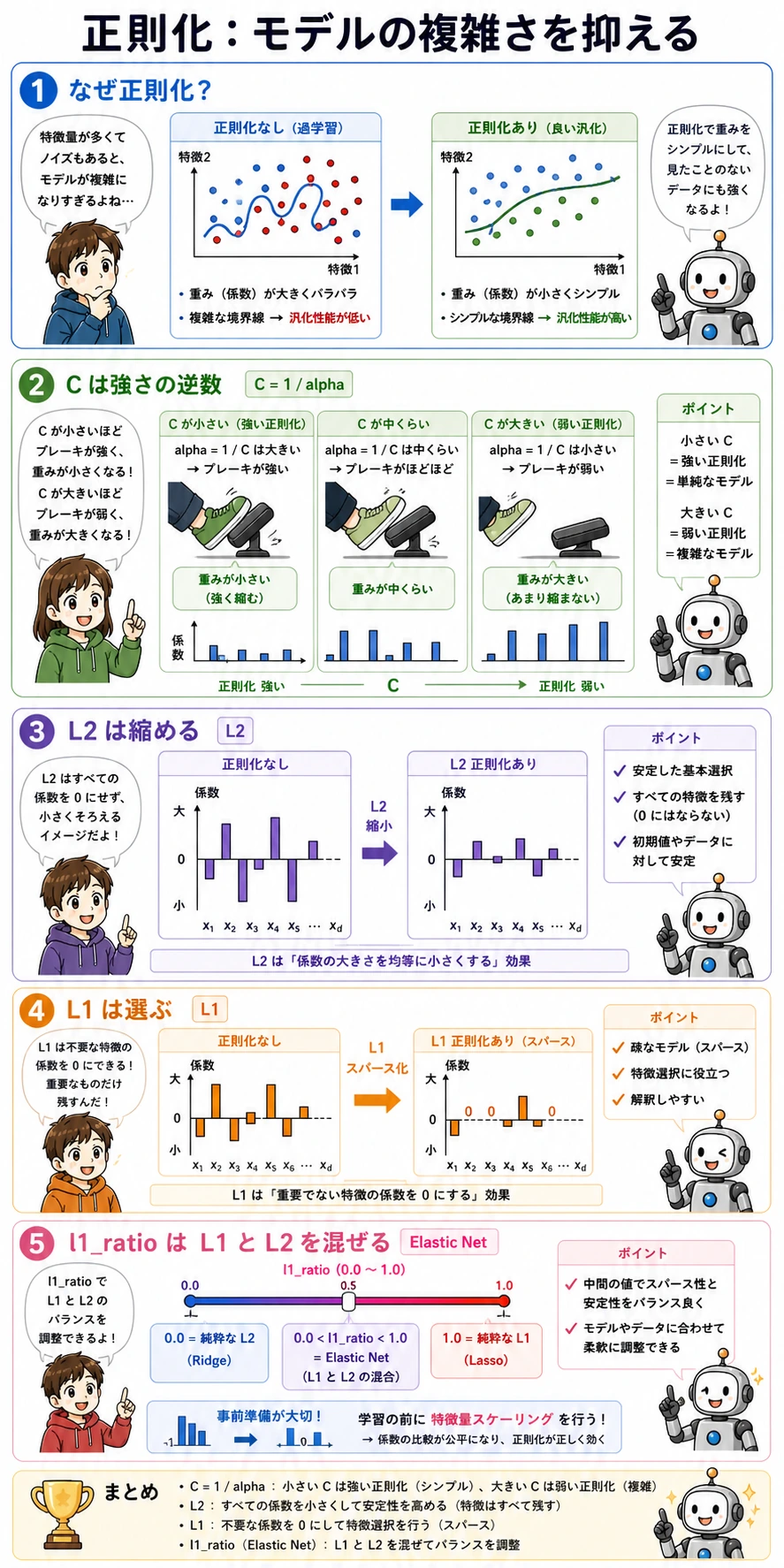
sklearn では、C は正則化強度の逆数です。
Cが小さいほど、正則化は強い;- 正則化が強いほど、係数は小さくなりやすい;
- 係数が極端に大きい場合、ノイズに合わせすぎている可能性がある。
今回の実験出力でもこの傾向が見えます。
C=0.1 accuracy=0.979 coef_norm=1.77
C=1.0 accuracy=0.986 coef_norm=3.52
C=10.0 accuracy=0.972 coef_norm=8.38
係数ノルムが一番大きいモデルが一番良いとは限りません。実運用のベースラインでは、精度だけでなく安定性と説明しやすさも重要です。
多クラス分類

クラスが 3 つ以上でも、ロジスティック回帰は確率を返せます。Iris の出力では、各行の確率がだいたい 1.0 になります。
setosa:0.03 | versicolor:0.62 | virginica:0.35
これは、モデルが versicolor を選びたいが、完全には確信していないことを意味します。この不確実性は、レビューキュー、能動学習、人間参加型のワークフローで役に立ちます。
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| 学習が収束しない | 特徴量をスケーリングしていない、または max_iter が小さい | Pipeline に StandardScaler を入れ、max_iter を増やす |
| accuracy は高いのに recall が低い | クラス不均衡、またはしきい値が合っていない | 混同行列、precision、recall、F1 を表示する |
| 係数を比較しにくい | 特徴量の単位が違う | 数値特徴量を先にスケーリングする |
| テストスコアが不自然に完璧 | train/test 分割前に前処理を fit した | 前処理を Pipeline に入れる |
| 多クラスコードで古い引数の警告が出る | 非推奨の multi_class 引数を使っている | 特定の solver が必要でなければ sklearn の既定動作を使う |
練習
- しきい値リストを
[0.2, 0.4, 0.6, 0.8]に変えてください。偽陰性が最も少ないしきい値はどれですか? Cを[0.01, 0.1, 1, 10, 100]に変えてください。accuracy はどこから伸びにくくなりますか?- 絶対値が大きい 3 つだけでなく、小さい係数も 3 つ表示してください。標準化後に何が見えますか?
- breast cancer データセットを自分の CSV に置き換えてください。構造は同じです。先に分割し、pipeline を fit し、指標を出し、最後にしきい値を調整します。
合格チェック
次の 4 文を見ずに説明できれば、この節はクリアです。
- ロジスティック回帰は分類器で、確率を予測する。
predict_proba()は確率を返し、しきい値が確率をラベルに変える。Cは正則化を制御し、Cが小さいほど正則化は強い。- 偽陽性と偽陰性のコストが違う場合、accuracy だけでは不十分。