E.A.6 モデルのサービス化
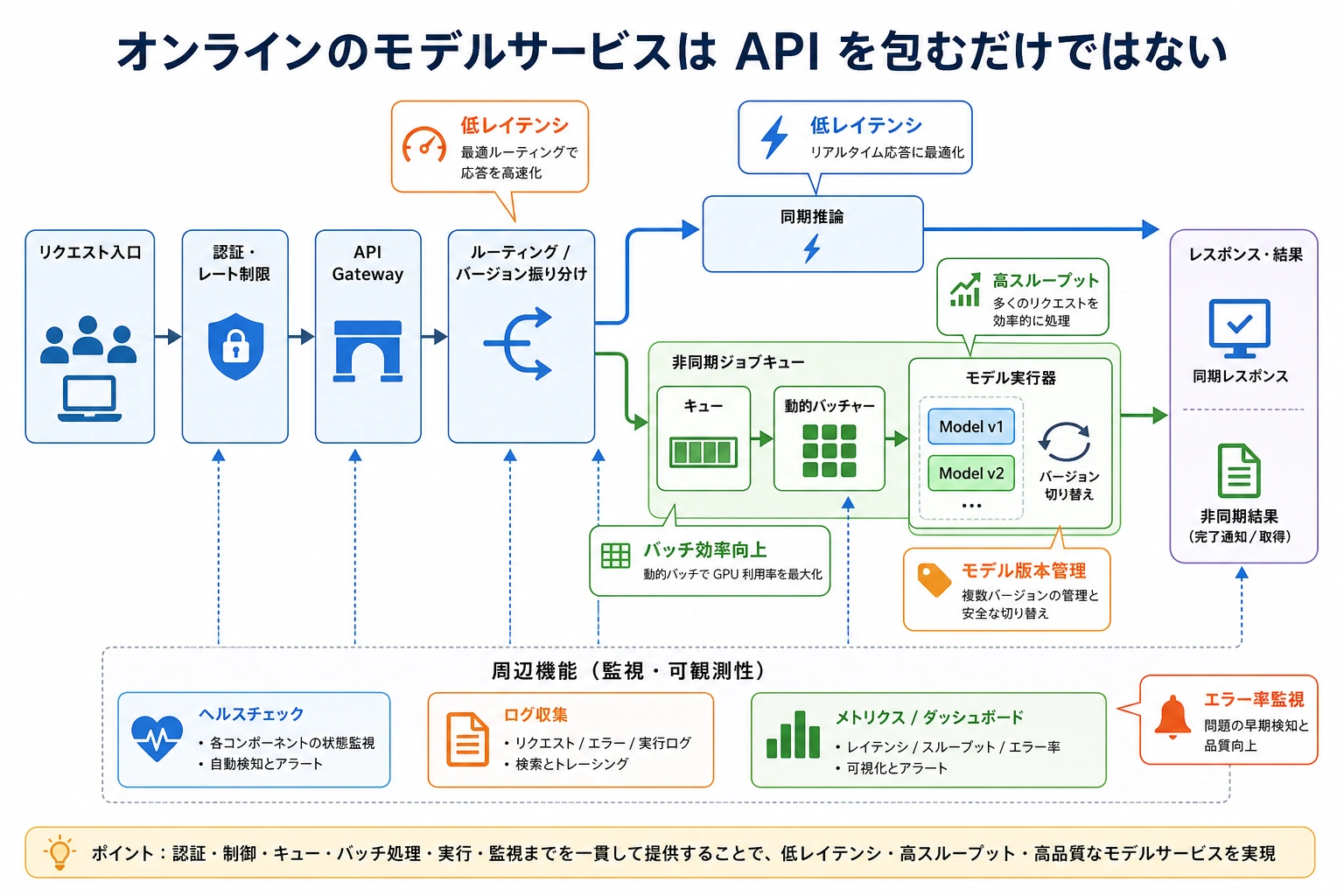
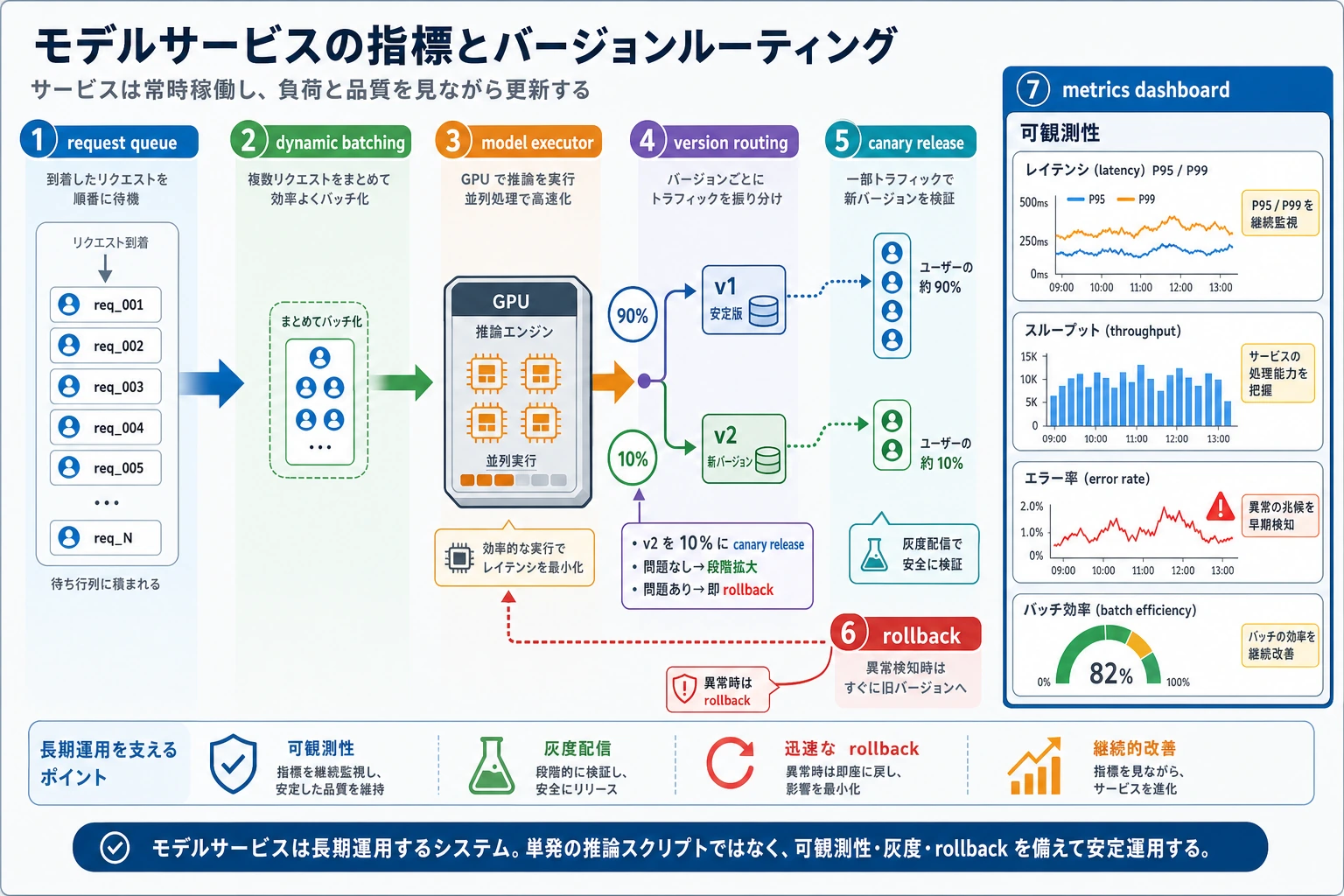
モデルをサービス化することは、スクリプトで一度モデルを呼ぶこととは違います。サービスは多くのリクエストを受け取り、キューに並べ、バッチ化し、正しいモデルバージョンへ送り、指標を記録し、あるバージョンが失敗しても戻せる必要があります。
準備するもの
- Python 3.10+
- 外部パッケージ不要
- 辞書とリストの基本
重要用語
- Queue(キュー):リクエストが一時的に待つ場所。
- Batch(バッチ):複数のリクエストをまとめて処理する単位。
- Version routing(バージョンルーティング):トラフィックを
v1、v2、カナリアモデルへ送ること。 - P95 latency(P95 レイテンシ):95% のリクエストがこの時間以内に終わるという指標。
- Rollback(ロールバック):トラフィックを安定した旧バージョンへ戻すこと。
小さな Serving ループを動かす
serving_loop.py を作成します。
requests = [
{"id": 1, "version": "v1", "text": "refund"},
{"id": 2, "version": "v1", "text": "invoice"},
{"id": 3, "version": "v2", "text": "change address"},
{"id": 4, "version": "v2", "text": "shipping"},
{"id": 5, "version": "v1", "text": "certificate"},
]
batches = {}
for request in requests:
batches.setdefault(request["version"], []).append(request)
for version, items in batches.items():
print(version, "batch_size=", len(items), "ids=", [item["id"] for item in items])
for item in items:
item["answer"] = f"{version}:{item['text']}:ok"
print("answers:")
for request in requests:
print(request["id"], request["answer"])
実行します。
python serving_loop.py
期待される出力:
v1 batch_size= 3 ids= [1, 2, 5]
v2 batch_size= 2 ids= [3, 4]
answers:
1 v1:refund:ok
2 v1:invoice:ok
3 v2:change address:ok
4 v2:shipping:ok
5 v1:certificate:ok
この小さなスクリプトは、サービス化の中心の流れを示します。リクエストが入り、バージョンごとに分けられ、バッチで処理され、追跡できる答えを返します。
安全ルールを追加する
バッチ処理ループの前にこれを追加します。
requests = [
{"id": 1, "version": "v1", "text": "refund"},
{"id": 2, "version": "v1", "text": "invoice"},
{"id": 3, "version": "v2", "text": "change address"},
]
healthy_versions = {"v1": True, "v2": False}
routed_requests = [
request if healthy_versions[request["version"]] else {**request, "version": "v1"}
for request in requests
]
print([request["version"] for request in routed_requests])
期待される出力:
['v1', 'v1', 'v1']
もう一度実行します。v2 を希望したリクエストは v1 に戻ります。これがヘルスチェックとロールバックの基本です。
本番前に最初に見る指標
まず記録したいもの:
- キュー待ち時間
- 平均レイテンシと P95 レイテンシ
- エラー率
- 平均 batch サイズ
- モデルバージョンごとのトラフィック比率
よくある間違い
- モデル推論時間だけを報告し、キュー、前処理、ネットワーク時間を無視する。
- batch を大きくしすぎて、ユーザー側のレイテンシを悪化させる。
- バージョンルーティングなしで本番モデルを直接置き換える。
- リクエスト ID がなく、障害時に追跡できない。
練習
各リクエストに latency_ms を追加し、バージョンごとの平均レイテンシを計算してください。v2 が v1 より 20 ms 以上遅い場合、以後のリクエストをすべて v1 に戻します。